2021年大数据Spark(八):环境搭建集群模式 Standalone HA

环境搭建-Standalone HA
高可用HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
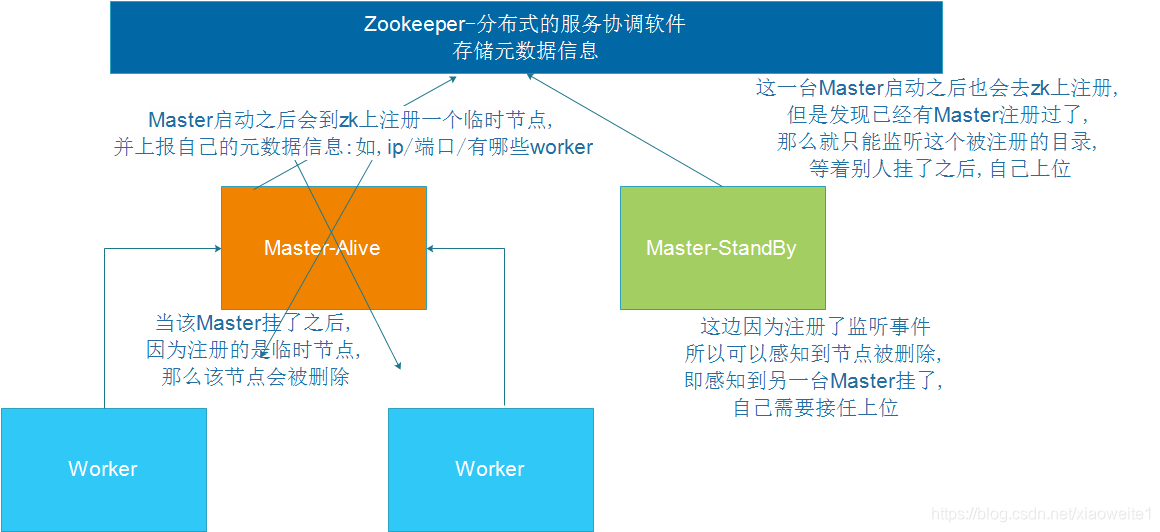
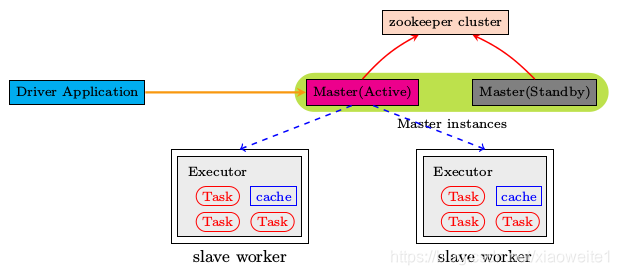
基于Zookeeper实现HA
官方文档:http://spark.apache.org/docs/2.4.5/spark-standalone.html#standby-masters-with-zookeeper
先停止Sprak集群
/export/server/spark/sbin/stop-all.sh
在node01上配置:
vim /export/server/spark/conf/spark-env.sh
注释或删除MASTER_HOST内容:
-
-
# SPARK_MASTER_HOST=node1
增加如下配置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
参数含义说明:
-
spark.deploy.recoveryMode:恢复模式
-
-
spark.deploy.zookeeper.url:ZooKeeper的Server地址
-
-
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。
将spark-env.sh分发集群
-
cd /export/server/spark/conf
-
-
scp -r spark-env.sh root@node2:$PWD
-
-
scp -r spark-env.sh root@node3:$PWD
启动集群服务
启动ZOOKEEPER服务
zkServer.sh status
zkServer.sh stop
zkServer.sh start
node1上启动Spark集群执行
/export/server/spark/sbin/start-all.sh
在node2上再单独只起个master:
/export/server/spark/sbin/start-master.sh
查看WebUI
测试运行
测试主备切换
1.在node1上使用jps查看master进程id
2.使用kill -9 id号强制结束该进程
3.稍等片刻后刷新node2的web界面发现node2为Alive
-
sc.textFile("hdfs://node1:8020/wordcount/input/words.txt")
-
-
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
-
-
.saveAsTextFile("hdfs://node1:8020/wordcount/output3")
如启动spark-shell,需要指定多个master地址
/export/server/spark/bin/spark-shell --master spark://node1:7077,node2:7077
停止集群
/export/server/spark/sbin/stop-all.sh
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115587089

- 点赞
- 收藏
- 关注作者
评论(0)