2021年大数据Spark(十):环境搭建集群模式 Spark on YARN

目录
环境搭建-Spark on YARN
Spark运行在YARN上是有2个模式的, 1个叫 Client模式 一个叫Cluster模式
Spark On Yarn - Cluster模式
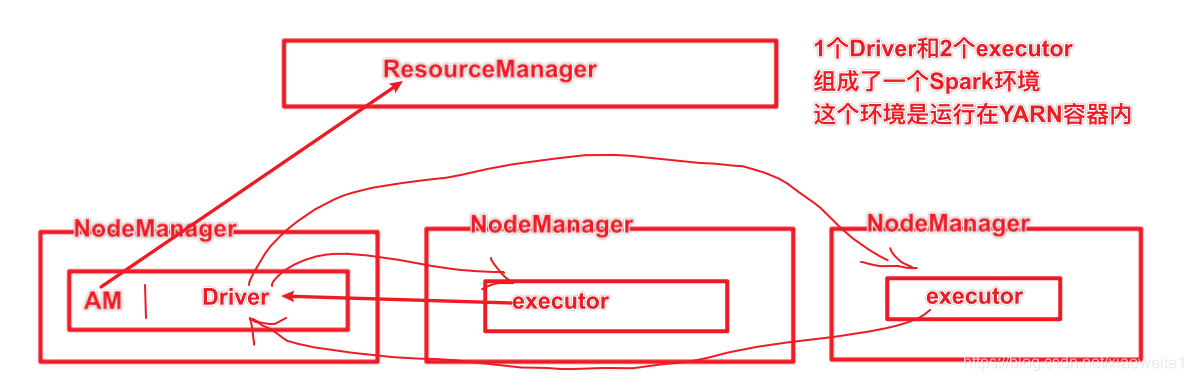
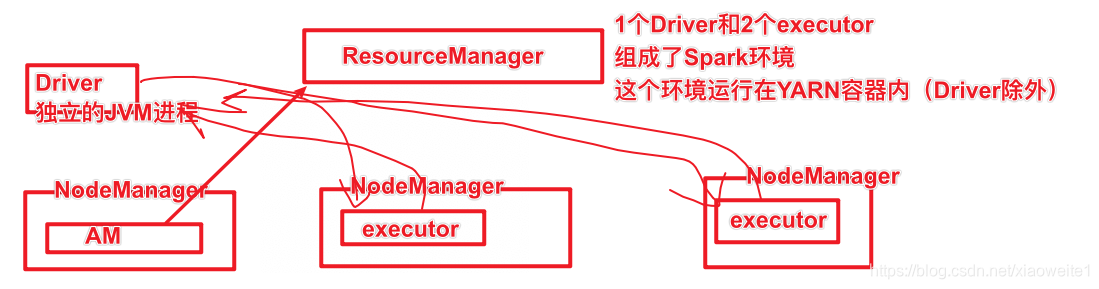
Spark On Yarn - Client模式
Yarn是一个成熟稳定且强大的资源管理和任务调度的大数据框架,在企业中市场占有率很高,意味着有很多公司都在用Yarn,将公司的资源交给Yarn做统一的管理!并支持对任务做多种模式的调度,如FIFO/Capacity/Fair等多种调度模式!
所以很多计算框架,都主动支持将计算任务放在Yarn上运行,如Spark/Flink
企业中也都是将Spark Application提交运行在YANR上,文档: http://spark.apache.org/docs/2.4.5/running-on-yarn.html#launching-spark-on-yarn
注意事项
Spark On Yarn的本质?
将Spark任务的class字节码文件打成jar包,提交到Yarn的JVM中去运行
Spark On Yarn需要啥?
1.需要Yarn集群:已经安装了
2.需要提交工具:spark-submit命令--在spark/bin目录
3.需要被提交的jar:Spark任务的jar包(如spark/example/jars中有示例程序,或我们后续自己开发的Spark任务)
4.需要其他依赖jar:Yarn的JVM运行Spark的字节码需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
总结:
SparkOnYarn
不需要搭建Spark集群
只需要:Yarn+单机版Spark(里面有提交命令,依赖jar,示例jar)
当然还要一些配置
修改配置
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
修改spark-env.sh
cd /export/server/spark/conf
vim /export/server/spark/conf/spark-env.sh
添加内容
-
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
-
-
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
-
-
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
同步
-
-
cd /export/server/spark/conf
-
-
scp -r spark-env.sh root@node2:$PWD
-
-
scp -r spark-env.sh root@node3:$PWD
整合历史服务器并关闭资源检查
整合Yarn历史服务器并关闭资源检查
在【$HADOOP_HOME/etc/hadoop/yarn-site.xml】配置文件中,指定MRHistoryServer地址信息,添加如下内容,
在node1上修改
cd /export/server/hadoop/etc/hadoop
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
添加内容
-
<configuration>
-
-
<!-- 配置yarn主节点的位置 -->
-
-
<property>
-
-
<name>yarn.resourcemanager.hostname</name>
-
-
<value>node1</value>
-
-
</property>
-
-
<property>
-
-
<name>yarn.nodemanager.aux-services</name>
-
-
<value>mapreduce_shuffle</value>
-
-
</property>
-
-
<!-- 设置yarn集群的内存分配方案 -->
-
-
<property>
-
-
<name>yarn.nodemanager.resource.memory-mb</name>
-
-
<value>20480</value>
-
-
</property>
-
-
<property>
-
-
<name>yarn.scheduler.minimum-allocation-mb</name>
-
-
<value>2048</value>
-
-
</property>
-
-
<property>
-
-
<name>yarn.nodemanager.vmem-pmem-ratio</name>
-
-
<value>2.1</value>
-
-
</property>
-
-
<!-- 开启日志聚合功能 -->
-
-
<property>
-
-
<name>yarn.log-aggregation-enable</name>
-
-
<value>true</value>
-
-
</property>
-
-
<!-- 设置聚合日志在hdfs上的保存时间 -->
-
-
<property>
-
-
<name>yarn.log-aggregation.retain-seconds</name>
-
-
<value>604800</value>
-
-
</property>
-
-
<!-- 设置yarn历史服务器地址 -->
-
-
<property>
-
-
<name>yarn.log.server.url</name>
-
-
<value>http://node1:19888/jobhistory/logs</value>
-
-
</property>
-
-
<!-- 关闭yarn内存检查 -->
-
-
<property>
-
-
<name>yarn.nodemanager.pmem-check-enabled</name>
-
-
<value>false</value>
-
-
</property>
-
-
<property>
-
-
<name>yarn.nodemanager.vmem-check-enabled</name>
-
-
<value>false</value>
-
-
</property>
-
-
</configuration>
由于使用虚拟机运行服务,默认情况下YARN检查机器内存,当内存不足时,提交的应用无法运行,可以设置不检查资源
在yarn-site.xml 中添加proxyserver的配置,可以让点击applicationmaster的时候跳转到spark的WEBUI上。
-
<property>
-
-
<name>yarn.web-proxy.address</name>
-
-
<value>node1:8089</value>
-
-
</property>
同步
-
cd /export/server/hadoop/etc/hadoop
-
-
scp -r yarn-site.xml root@node2:$PWD
-
-
scp -r yarn-site.xml root@node3:$PWD
配置spark历史服务器
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加内容:
-
-
spark.eventLog.enabled true
-
-
spark.eventLog.dir hdfs://node1:8020/sparklog/
-
-
spark.eventLog.compress true
-
-
spark.yarn.historyServer.address node1:18080
修改spark-env.sh
进入配置目录
cd /export/server/spark/conf
修改配置文件
vim spark-env.sh
增加如下内容:
-
-
## 配置spark历史服务器地址
-
-
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
注意:sparklog需要手动创建
hadoop fs -mkdir -p /sparklog
设置日志级别
进入目录
cd /export/server/spark/conf
修改日志属性配置文件名称
mv log4j.properties.template log4j.properties
改变日志级别
vim log4j.properties
修改内容如下:

同步
-
-
cd /export/server/spark/conf
-
-
scp -r spark-env.sh root@node2:$PWD
-
-
scp -r spark-env.sh root@node3:$PWD
-
-
scp -r spark-defaults.conf root@node2:$PWD
-
-
scp -r spark-defaults.conf root@node3:$PWD
-
-
scp -r log4j.properties root@node2:$PWD
-
-
scp -r log4j.properties root@node3:$PWD
配置依赖Spark Jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
-
-
## hdfs上创建存储spark相关jar包目录
-
-
hadoop fs -mkdir -p /spark/jars/
-
-
## 上传$SPARK_HOME/jars所有jar包
-
-
hadoop fs -put /export/server/spark/jars/* /spark/jars/
在spark-defaults.conf中增加Spark相关jar包位置信息:
在node1上操作
vim /export/server/spark/conf/spark-defaults.conf
添加内容
-
-
spark.yarn.jars hdfs://node1:8020/spark/jars/*
同步
-
cd /export/server/spark/conf
-
-
scp -r spark-defaults.conf root@node2:$PWD
-
-
scp -r spark-defaults.conf root@node3:$PWD
启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
-
## 启动HDFS和YARN服务,在node1执行命令
-
-
start-dfs.sh
-
-
start-yarn.sh
-
-
或
-
-
start-all.sh
-
-
## 启动MRHistoryServer服务,在node1执行命令
-
-
mr-jobhistory-daemon.sh start historyserver
-
-
## 启动Spark HistoryServer服务,,在node1执行命令
-
-
/export/server/spark/sbin/start-history-server.sh
-
-
## 启动Yarn的ProxyServer服务
-
-
/export/server/hadoop/sbin/yarn-deamon.sh start proxyserver
Spark HistoryServer服务WEB UI页面地址:
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115587523

- 点赞
- 收藏
- 关注作者
评论(0)