2021年大数据Spark(二十五):SparkSQL的RDD、DF、DS相关操作

目录
RDD、DF、DS相关操作
SparkSQL初体验
Spark 2.0开始,SparkSQL应用程序入口为SparkSession,加载不同数据源的数据,封装到DataFrame/Dataset集合数据结构中,使得编程更加简单,程序运行更加快速高效。

SparkSession 应用入口
SparkSession:这是一个新入口,取代了原本的SQLContext与HiveContext。对于DataFrame API的用户来说,Spark常见的混乱源头来自于使用哪个“context”。现在使用SparkSession,它作为单个入口可以兼容两者,注意原本的SQLContext与HiveContext仍然保留,以支持向下兼容。
文档:http://spark.apache.org/docs/2.4.5/sql-getting-started.html#starting-point-sparksession
1)、添加MAVEN依赖
-
<dependency>
-
-
<groupId>org.apache.spark</groupId>
-
-
<artifactId>spark-sql_2.11</artifactId>
-
-
<version>2.4.5</version>
-
-
</dependency>
2)、SparkSession对象实例通过建造者模式构建,代码如下:

其中①表示导入SparkSession所在的包,②表示建造者模式构建对象和设置属性,③表示导入SparkSession类中implicits对象object中隐式转换函数。
3)、范例演示:构建SparkSession实例,加载文本数据,统计条目数。
-
package cn.itcast.sql
-
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示SparkSQL
-
*/
-
object SparkSQLDemo00_hello {
-
def main(args: Array[String]): Unit = {
-
//1.准备SparkSQL开发环境
-
println(this.getClass.getSimpleName)
-
println(this.getClass.getSimpleName.stripSuffix("$"))
-
val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
val df1: DataFrame = spark.read.text("data/input/text")
-
val df2: DataFrame = spark.read.json("data/input/json")
-
val df3: DataFrame = spark.read.csv("data/input/csv")
-
val df4: DataFrame = spark.read.parquet("data/input/parquet")
-
-
df1.printSchema()
-
df1.show(false)
-
df2.printSchema()
-
df2.show(false)
-
df3.printSchema()
-
df3.show(false)
-
df4.printSchema()
-
df4.show(false)
-
-
-
df1.coalesce(1).write.mode(SaveMode.Overwrite).text("data/output/text")
-
df2.coalesce(1).write.mode(SaveMode.Overwrite).json("data/output/json")
-
df3.coalesce(1).write.mode(SaveMode.Overwrite).csv("data/output/csv")
-
df4.coalesce(1).write.mode(SaveMode.Overwrite).parquet("data/output/parquet")
-
-
//关闭资源
-
sc.stop()
-
spark.stop()
-
}
-
}
使用SparkSession加载数据源数据,将其封装到DataFrame或Dataset中,直接使用show函数就可以显示样本数据(默认显示前20条)。
Spark2.0使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。 SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
获取DataFrame/DataSet
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息,官方提供两种方式:类型推断和自定义Schema。
官方文档:http://spark.apache.org/docs/2.4.5/sql-getting-started.html#interoperating-with-rdds

使用样例类
当RDD中数据类型CaseClass样例类时,通过反射Reflecttion获取属性名称和类型,构建Schema,应用到RDD数据集,将其转换为DataFrame。
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示基于RDD创建DataFrame--使用样例类
-
*/
-
object CreateDataFrameDemo1 {
-
case class Person(id:Int,name:String,age:Int)
-
-
def main(args: Array[String]): Unit = {
-
//1.准备环境-SparkSession
-
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
//2.加载数据
-
val lines: RDD[String] = sc.textFile("data/input/person.txt")
-
-
//3.切割
-
//val value: RDD[String] = lines.flatMap(_.split(" "))//错误的
-
val linesArrayRDD: RDD[Array[String]] = lines.map(_.split(" "))
-
-
//4.将每一行(每一个Array)转为样例类(相当于添加了Schema)
-
val personRDD: RDD[Person] = linesArrayRDD.map(arr=>Person(arr(0).toInt,arr(1),arr(2).toInt))
-
-
//5.将RDD转为DataFrame(DF)
-
//注意:RDD的API中没有toDF方法,需要导入隐式转换!
-
import spark.implicits._
-
val personDF: DataFrame = personRDD.toDF
-
-
//6.查看约束
-
personDF.printSchema()
-
-
//7.查看分布式表中的数据集
-
personDF.show(6,false)//false表示不截断列名,也就是列名很长的时候不会用...代替
-
}
-
}
此种方式要求RDD数据类型必须为CaseClass,转换的DataFrame中字段名称就是CaseClass中属性名称。
指定类型+列名
除了上述两种方式将RDD转换为DataFrame以外,SparkSQL中提供一个函数:toDF,通过指定列名称,将数据类型为元组的RDD或Seq转换为DataFrame,实际开发中也常常使用。
![]()
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示基于RDD创建DataFrame--使用类型加列名
-
*/
-
object CreateDataFrameDemo2 {
-
def main(args: Array[String]): Unit = {
-
//1.准备环境-SparkSession
-
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
//2.加载数据
-
val lines: RDD[String] = sc.textFile("data/input/person.txt")
-
-
//3.切割
-
//val value: RDD[String] = lines.flatMap(_.split(" "))//错误的
-
val linesArrayRDD: RDD[Array[String]] = lines.map(_.split(" "))
-
-
//4.将每一行(每一个Array)转为三元组(相当于有了类型!)
-
val personWithColumnsTypeRDD: RDD[(Int, String, Int)] = linesArrayRDD.map(arr=>(arr(0).toInt,arr(1),arr(2).toInt))
-
-
//5.将RDD转为DataFrame(DF)并指定列名
-
//注意:RDD的API中没有toDF方法,需要导入隐式转换!
-
import spark.implicits._
-
val personDF: DataFrame = personWithColumnsTypeRDD.toDF("id","name","age")
-
-
//6.查看约束
-
personDF.printSchema()
-
-
//7.查看分布式表中的数据集
-
personDF.show(6,false)//false表示不截断列名,也就是列名很长的时候不会用...代替
-
}
-
}
自定义Schema
依据RDD中数据自定义Schema,类型为StructType,每个字段的约束使用StructField定义,具体步骤如下:
第一步、RDD中数据类型为Row:RDD[Row];
第二步、针对Row中数据定义Schema:StructType;
第三步、使用SparkSession中方法将定义的Schema应用到RDD[Row]上;
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.types.{IntegerType, LongType, StringType, StructField, StructType}
-
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示基于RDD创建DataFrame--使用StructType
-
*/
-
object CreateDataFrameDemo3 {
-
def main(args: Array[String]): Unit = {
-
//1.准备环境-SparkSession
-
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
//2.加载数据
-
val lines: RDD[String] = sc.textFile("data/input/person.txt")
-
-
//3.切割
-
//val value: RDD[String] = lines.flatMap(_.split(" "))//错误的
-
val linesArrayRDD: RDD[Array[String]] = lines.map(_.split(" "))
-
-
//4.将每一行(每一个Array)转为Row
-
val rowRDD: RDD[Row] = linesArrayRDD.map(arr=>Row(arr(0).toInt,arr(1),arr(2).toInt))
-
-
//5.将RDD转为DataFrame(DF)并指定列名
-
//注意:RDD的API中没有toDF方法,需要导入隐式转换!
-
import spark.implicits._
-
/*val schema: StructType = StructType(
-
StructField("id", IntegerType, false) ::
-
StructField("name", StringType, false) ::
-
StructField("age", IntegerType, false) :: Nil)*/
-
val schema: StructType = StructType(List(
-
StructField("id", IntegerType, false),
-
StructField("name", StringType, false),
-
StructField("age", IntegerType, false)
-
))
-
val personDF: DataFrame = spark.createDataFrame(rowRDD,schema)
-
-
//6.查看约束
-
personDF.printSchema()
-
-
//7.查看分布式表中的数据集
-
personDF.show(6,false)//false表示不截断列名,也就是列名很长的时候不会用...代替
-
}
-
-
}
此种方式可以更加体会到DataFrame = RDD[Row] + Schema组成,在实际项目开发中灵活的选择方式将RDD转换为DataFrame。
RDD、DF、DS相互转换
实际项目开发中,常常需要对RDD、DataFrame及Dataset之间相互转换,其中要点就是Schema约束结构信息。
1)、RDD转换DataFrame或者Dataset
转换DataFrame时,定义Schema信息,两种方式
转换为Dataset时,不仅需要Schema信息,还需要RDD数据类型为CaseClass类型
2)、Dataset或DataFrame转换RDD
由于Dataset或DataFrame底层就是RDD,所以直接调用rdd函数即可转换
dataframe.rdd 或者dataset.rdd
3)、DataFrame与Dataset之间转换
由于DataFrame为Dataset特例,所以Dataset直接调用toDF函数转换为DataFrame
当将DataFrame转换为Dataset时,使用函数as[Type],指定CaseClass类型即可。
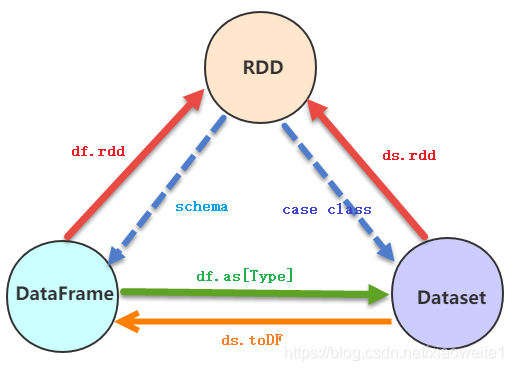
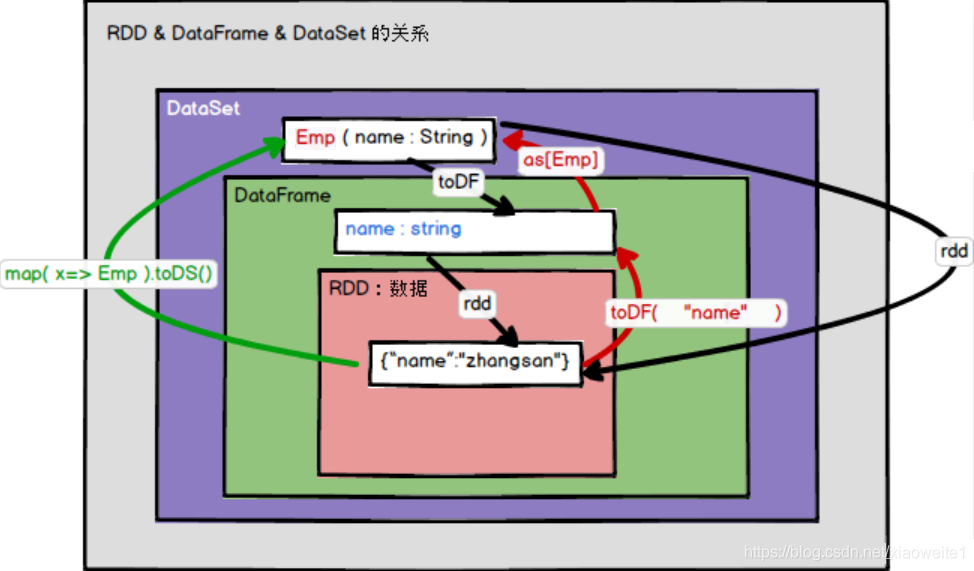
RDD、DataFrame和DataSet之间的转换如下,假设有个样例类:case class Emp(name: String),相互转换
-
RDD转换到DataFrame:rdd.toDF(“name”)
-
-
RDD转换到Dataset:rdd.map(x => Emp(x)).toDS
-
-
DataFrame转换到Dataset:df.as[Emp]
-
-
DataFrame转换到RDD:df.rdd
-
-
Dataset转换到DataFrame:ds.toDF
-
-
Dataset转换到RDD:ds.rdd
注意:
RDD与DataFrame或者DataSet进行操作,都需要引入隐式转换import spark.implicits._,其中的spark是SparkSession对象的名称!
-
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示基于RDD/DataFrame/DataSet三者之间的相互转换
-
*/
-
object TransformationDemo {
-
case class Person(id:Int,name:String,age:Int)
-
-
def main(args: Array[String]): Unit = {
-
//1.准备环境-SparkSession
-
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
//2.加载数据
-
val lines: RDD[String] = sc.textFile("data/input/person.txt")
-
-
//3.切割
-
//val value: RDD[String] = lines.flatMap(_.split(" "))//错误的
-
val linesArrayRDD: RDD[Array[String]] = lines.map(_.split(" "))
-
-
//4.将每一行(每一个Array)转为样例类(相当于添加了Schema)
-
val personRDD: RDD[Person] = linesArrayRDD.map(arr=>Person(arr(0).toInt,arr(1),arr(2).toInt))
-
-
//5.将RDD转为DataFrame(DF)
-
//注意:RDD的API中没有toDF方法,需要导入隐式转换!
-
import spark.implicits._
-
//转换1:rdd-->df
-
val personDF: DataFrame = personRDD.toDF //注意:DataFrame没有泛型
-
//转换2:rdd-->ds
-
val personDS: Dataset[Person] = personRDD.toDS() //注意:Dataset具有泛型
-
//转换3:df-->rdd
-
val rdd: RDD[Row] = personDF.rdd //注意:DataFrame没有泛型,也就是不知道里面是Person,所以转为rdd之后统一的使用Row表示里面是很多行
-
//转换4:ds-->rdd
-
val rdd1: RDD[Person] = personDS.rdd //注意:Dataset具有泛型,所以转为rdd之后还有原来泛型!
-
//转换5:ds-->df
-
val dataFrame: DataFrame = personDS.toDF()
-
//转换5:df-->ds
-
val personDS2: Dataset[Person] = personDF.as[Person]
-
-
//目前DataFrame和DataSet使用类似,如:也有show/createOrReplaceTempView/select
-
personDS.show()
-
personDS.createOrReplaceTempView("t_person")
-
personDS.select("name").show()
-
-
}
-
}
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115747643

- 点赞
- 收藏
- 关注作者
评论(0)