2021年大数据Spark(三十):SparkSQL自定义UDF函数

目录
第一种:UDF(User-Defined-Function) 函数
第二种:UDAF(User-Defined Aggregation Function) 聚合函数
第三种:UDTF(User-Defined Table-Generating Functions) 函数
自定义UDF函数
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在org.apache.spark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
第一种:UDF(User-Defined-Function) 函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function) 聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions) 函数
一对多的关系,输入一个值输出多个值(一行变为多行);
用户自定义生成函数,有点像flatMap;
注意
目前来说Spark 框架各个版本及各种语言对自定义函数的支持:
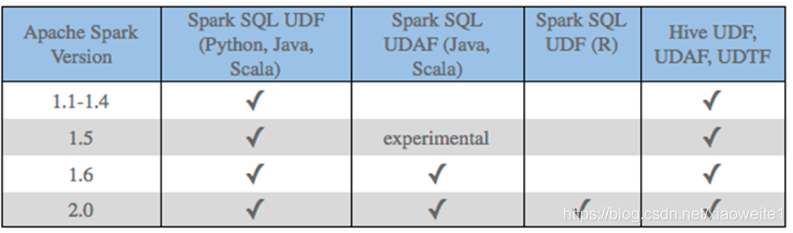
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数:
UDF函数:一对一关系;
UDAF函数:聚合函数,通常与group by 分组函数连用,多对一关系;
由于SparkSQL数据分析有两种方式:DSL编程和SQL编程,所以定义UDF函数也有两种方式,不同方式可以在不同分析中使用。
SQL方式
使用SparkSession中udf方法定义和注册函数,在SQL中使用,使用如下方式定义:

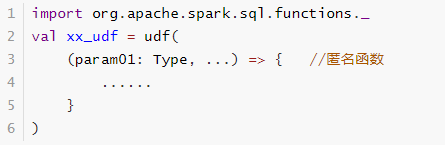
DSL方式
使用org.apache.sql.functions.udf函数定义和注册函数,在DSL中使用,如下方式:
代码演示
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.sql.expressions.UserDefinedFunction
-
import org.apache.spark.sql.{DataFrame, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc
-
* 将udf.txt中的单词使用SparkSQL自定义函数转为大写
-
* hello
-
* haha
-
* hehe
-
* xixi
-
*/
-
object UDFDemo {
-
def main(args: Array[String]): Unit = {
-
//1.准备环境
-
val spark: SparkSession = SparkSession.builder().appName("UDFDemo").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
import spark.implicits._
-
-
//2.加载数据
-
val df: DataFrame = spark.read.text("data/input/udf.txt")
-
df.show()
-
/*
-
+-----+
-
|value|
-
+-----+
-
|hello|
-
| haha|
-
| hehe|
-
| xixi|
-
+-----+
-
*/
-
-
//3.使用自定义函数将单词转为大写
-
-
//SQL风格-自定义函数
-
//spark.udf.register("函数名",函数实现)
-
spark.udf.register("small2big", (value: String) => value.toUpperCase())
-
-
df.createOrReplaceTempView("t_words")
-
val sql: String =
-
"""
-
|select value,small2big(value) as small_word
-
|from t_words
-
|""".stripMargin
-
spark.sql(sql).show() //如果没有自定义该函数,那么会报错:Undefined function: 'small2big'.
-
-
//DSL风格-自定义函数
-
//val small2big2: UserDefinedFunction = functions.udf((value: String) => value.toUpperCase)
-
import org.apache.spark.sql.functions._
-
val small2big2: UserDefinedFunction = udf((value: String) => value.toUpperCase)
-
df.select($"value", small2big2($"value").as("small_word")).show()
-
}
-
}
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115808039

- 点赞
- 收藏
- 关注作者
评论(0)