2021年大数据Spark(四十六):Structured Streaming Operations 操作

【摘要】
目录
Operations 操作
官网示例代码:
Operations 操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述
官网示例代码:
case class DeviceData...
目录
Operations 操作
获得到Source之后的基本数据处理方式和之前学习的DataFrame、DataSet一致,不再赘述
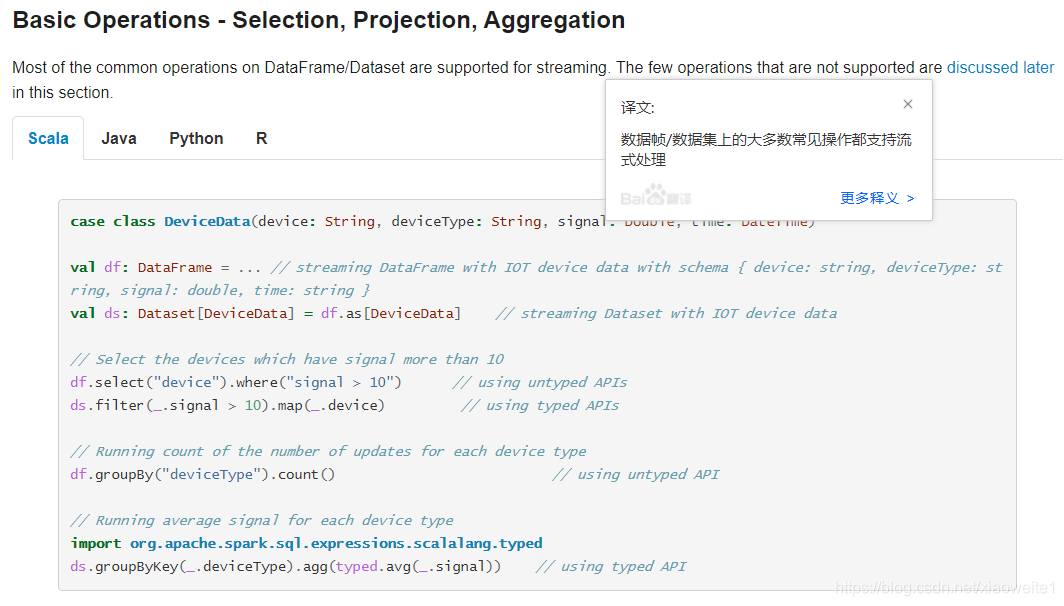
官网示例代码:
-
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
-
-
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
-
-
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
-
-
// Select the devices which have signal more than 10
-
-
df.select("device").where("signal > 10") // using untyped APIs
-
-
ds.filter(_.signal > 10).map(_.device) // using typed APIs
-
-
// Running count of the number of updates for each device type
-
-
df.groupBy("deviceType").count() // using untyped API
-
-
// Running average signal for each device type
-
-
import org.apache.spark.sql.expressions.scalalang.typed
-
-
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/116036090

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)