2021年大数据常用语言Scala(二十七):函数式编程 聚合操作

目录
聚合操作
聚合操作,可以将一个列表中的数据合并为一个。这种操作经常用来统计分析中
聚合 reduce
reduce表示将列表,传入一个函数进行聚合计算
定义
方法签名
def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1
方法解析
| reduce方法 |
API |
说明 |
| 泛型 |
[A1 >: A] |
(下界)A1必须是集合元素类型的子类 |
| 参数 |
op: (A1, A1) ⇒ A1 |
传入函数对象,用来不断进行聚合操作<br />第一个A1类型参数为:当前聚合后的变量<br />第二个A1类型参数为:当前要进行聚合的元素 |
| 返回值 |
A1 |
列表最终聚合为一个元素 |
reduce执行流程分析
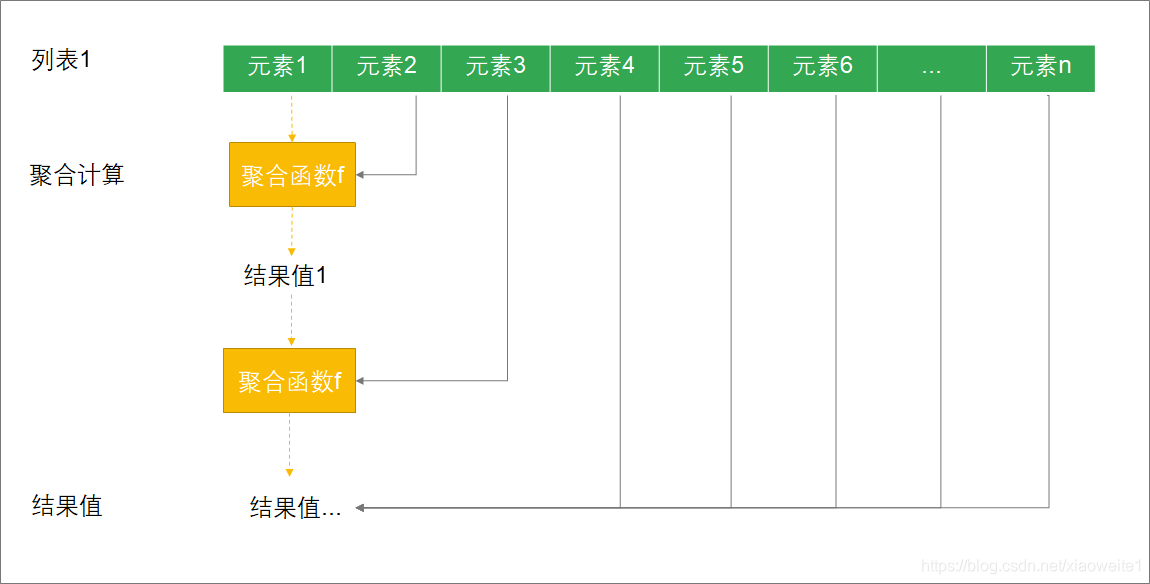
[!NOTE]
- reduce和reduceLeft效果一致,表示从左到右计算
- reduceRight表示从右到左计算
案例
定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
使用reduce计算所有元素的和
参考代码
-
scala> val a = List(1,2,3,4,5,6,7,8,9,10)
-
a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
-
-
scala> a.reduce((x,y) => x + y)
-
res5: Int = 55
-
-
// 第一个下划线表示第一个参数,就是历史的聚合数据结果
-
// 第二个下划线表示第二个参数,就是当前要聚合的数据元素
-
scala> a.reduce(_ + _)
-
res53: Int = 55
-
-
// 与reduce一样,从左往右计算
-
scala> a.reduceLeft(_ + _)
-
res0: Int = 55
-
-
// 从右往左聚合计算
-
scala> a.reduceRight(_ + _)
-
res1: Int = 55
折叠 fold
fold与reduce很像,但是多了一个指定初始值参数
定义
方法签名
def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1
方法解析
| reduce方法 |
API |
说明 |
| 泛型 |
[A1 >: A] |
(下界)A1必须是集合元素类型的子类 |
| 参数1 |
z: A1 |
初始值 |
| 参数2 |
op: (A1, A1) ⇒ A1 |
传入函数对象,用来不断进行折叠操作<br />第一个A1类型参数为:当前折叠后的变量<br />第二个A1类型参数为:当前要进行折叠的元素 |
| 返回值 |
A1 |
列表最终折叠为一个元素 |
[!NOTE]
- fold和foldLet效果一致,表示从左往右计算
- foldRight表示从右往左计算
案例
定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
使用fold方法计算所有元素的和
参考代码
-
scala> val a = List(1,2,3,4,5,6,7,8,9,10)
-
a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
-
-
scala> a.fold(0)(_ + _)
-
res4: Int = 155
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/116560492

- 点赞
- 收藏
- 关注作者
评论(0)