【实践】YOLOP 全景驾驶感知 同时处理三大视觉任务

前言
YOLOP能同时处理目标检测、可行驶区域分割、车道线检测 三个视觉感知任务,并速度优异、保持较好精度进行工作,代码开源。它是华中科技大学——王兴刚团队,在全景驾驶感知方面提出的模型,致敬开源精神。
论文地址:
开源代码:
全景驾驶感知系统是自动驾驶的重要组成部分。高精度、实时的感知系统可以辅助车辆在行驶中做出合理的决策。提出了一个全景驾驶感知网络(YOLOP)来同时执行交通目标检测、可行驶区域分割和车道检测。


在上图中,紫色边界框表示交通对象,绿色区域是可行驶区域,红色线表示车道线。
搭建开发环境
下载工程包,并解压。
首先创建一个conda环境,命名为YOLOP
conda create -n YOLOP python=3.7创建好后进入环境
conda activate YOLOP安装PyTorch 1.7+版本和 torchvision 0.8+版本
conda install pytorch==1.7.0 torchvision==0.8.0 cudatoolkit=10.2 -c pytorch安装其他依赖库
pip install -r requirements.txt如果安装过程没错误,这样YOLOP的开发环境就搭建好了。
模型推理测试
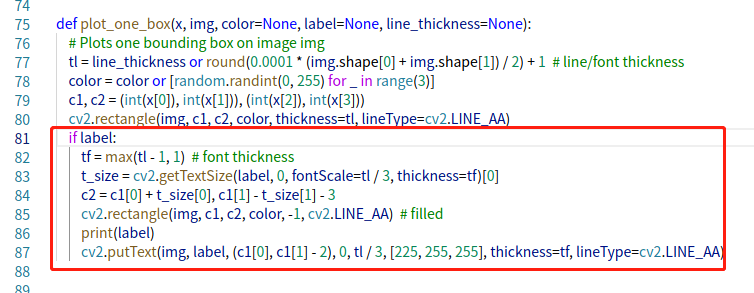
注意:官方代码默认是“注释掉标签信息的”,如果想每个框框中显示类别和置信度,需要解注释。
lib/utils/plot.py,在plot.py文件中的81到87行代码,进行解注释
![]()
输入的结果中,每个框有标签信息

![]()
1 推理图片
测试某一张图片
python tools/demo.py --source inference/images/name.png测试整个目录下的所有图片
结果不会直接显示的,而是放在 inference/output 目录下。
![]()
2 使用GPU推理
代码默认是CPU进行推理的,如果使用GPU需要添加参数 --device
指定CPU进行推理
5.3 推理视频
使用GPU推理视频
python tools/demo.py --source inference/videos/1.mp4 --device 05.4 使用相机进行推理
使用相机进行GPU推理
六、训练模型
首先下载数据集和标签:
-
从 下载图片数据集
-
从 下载检测任务的标签
-
从 下载可行驶区域分割任务的标签
-
从 下载车道线分割任务的标签
按照如下图片数据集文件结构:
├─dataset root
│ ├─images
│ │ ├─train
│ │ ├─val
│ ├─det_annotations
│ │ ├─train
│ │ ├─val
│ ├─da_seg_annotations
│ │ ├─train
│ │ ├─val
│ ├─ll_seg_annotations
│ │ ├─train
│ │ ├─val
在 ./lib/config/default.py下更新数据集的路径配置。
我们可以在 ./lib/config/default.py设定训练配置. (包括: 预训练模型的读取,损失函数, 数据增强,optimizer,训练预热和余弦退火,自动anchor,训练轮次epoch, batch_size)
如果你想尝试交替优化或者单一任务学习,可以在./lib/config/default.py 中将对应的配置选项修改为 True。(如下,所有的配置都是 False, which means training multiple tasks end to end)。
# Alternating optimization
_C.TRAIN.SEG_ONLY = False # Only train two segmentation branchs
_C.TRAIN.DET_ONLY = False # Only train detection branch
_C.TRAIN.ENC_SEG_ONLY = False # Only train encoder and two segmentation branchs
_C.TRAIN.ENC_DET_ONLY = False # Only train encoder and detection branch
# Single task
_C.TRAIN.DRIVABLE_ONLY = False # Only train da_segmentation task
_C.TRAIN.LANE_ONLY = False # Only train ll_segmentation task
_C.TRAIN.DET_ONLY = False # Only train detection task
开始训练:
参考文献
[1]
[3] 论文地址:
[4] 开源代码:
[5]
本文只供大家参考和学习。

- 点赞
- 收藏
- 关注作者
评论(0)