手把手教你轻松搞定高精度的消费者数据分析和预测

消费者数据分析,一直是众多企业最基础也是最重要的数据工作。如何做高精度的消费者数据分析和预测?这篇文章把这个问题讲透。
这里我们使用天池开放的数据资源(Baby Goods Info Data,资源地址: https://tianchi.aliyun.com/dataset/dataDetail?dataId=45)里下载了两个csv的数据:
- Tianchi_mum_baby.csv(儿童信息)
- Tianchi_mum_baby_trade_history.csv(交易记录)
作为体验该软件的样例数据。表结构如下2图所示。
表1 儿童信息
| 列名 | 描述 |
| user_id | 整数类型,用户ID |
| birthday | 时间类型,出生年月日 |
| gender | 性别(“0”是女,“1”是男,“2”是未知) |
表2 交易记录
| 列名 | 描述 |
| auction_id | 整数类型,交易ID |
| user_id | 整数类型,用户ID |
| cat_id | 整数类型,品类ID |
| cat1 | 整数类型,基础品类ID |
| property | 文本类型,商品相关属性 |
| buy_mount | 整数类型,购买数量 |
| day | 时间戳,交易日期 |
通过两个表的数据,实现“根据用户购买的儿童用品交易记录预测儿童的年龄”。
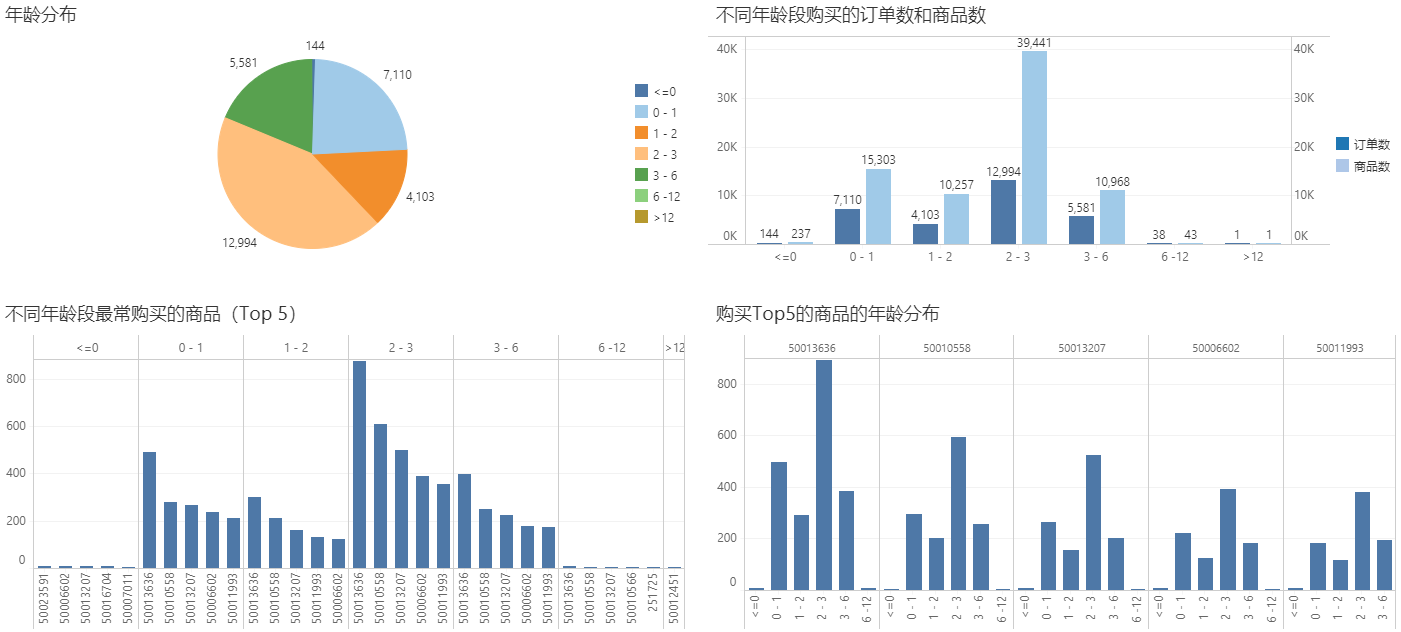
后续就可以基于预测的结果向用户推荐该年龄段可能需要的商品,促成更多商品销售,用数据分析提升产品转换。笔者所使用的软件是Yonghong Desktop,最终实现做成了一幅可视化报表,如下:
接下来我们就来一起学习下,如何利用这些数据来实现分析与预测吧~
一、做好基础准备——数据的导入与探索
数据导入
数据源的格式为CSV格式,直接在Yonghong Desktop上选择下图1这个功能上传数据即可形成数据集。
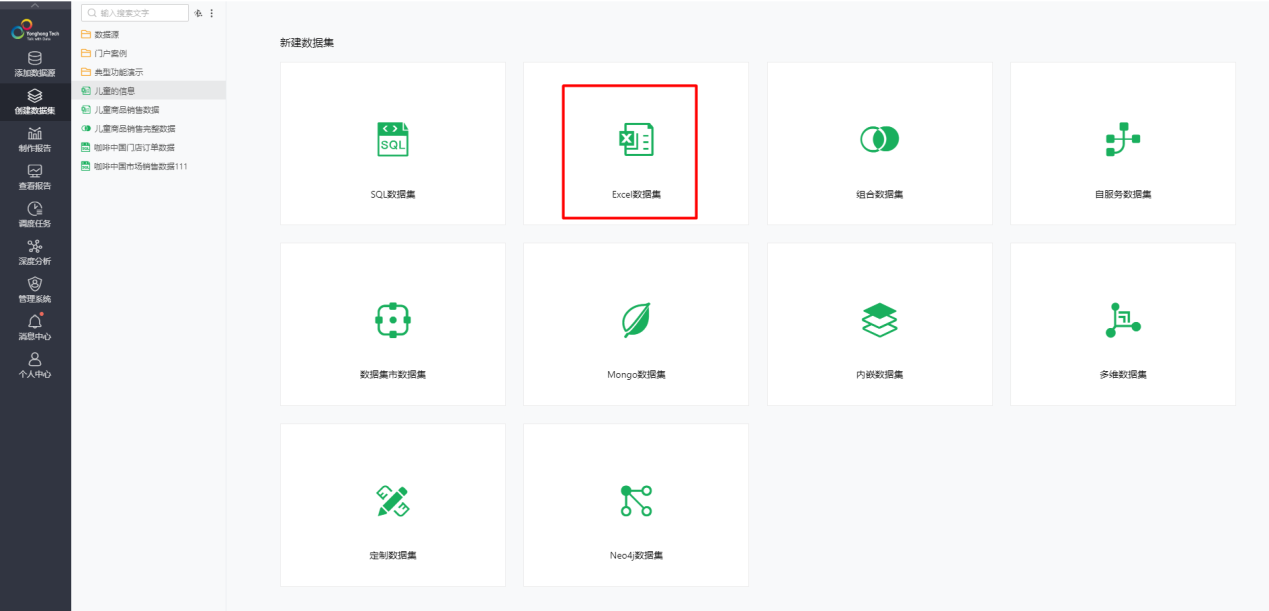
图1 CSV数据导入功能
导入后的数据集分别存放在如下位置:
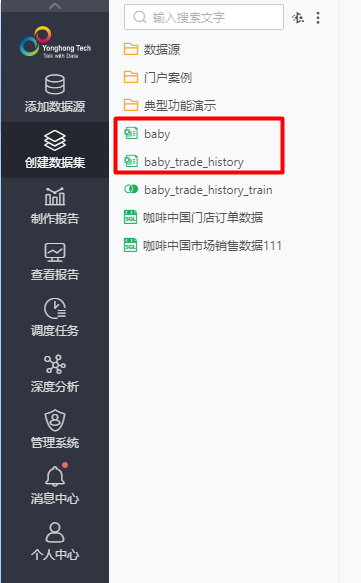
图2 导入的原始数据集
数据探索
在Yonghong Desktop 上“深度分析”模块创建一个新实验,将数据集“baby”、“baby_trade_history”拖入画布,在右侧查看各个数据的元数据、探索数据功能。
可以发现:
“baby”数据集的user_id字段唯一值数量为953个,“baby_trade_history”数据集的user_id字段唯一值数量为29944个,因此只有3.18%的用户关联有baby数据的。“baby_trade_history”数据集的property字段是关于购买商品的属性信息且均已脱敏,无法知道其具体含义。
这么多的交易记录都查不到对应的儿童信息,我的想法是通过有儿童信息的交易记录,经过模型构建推理剩下那些交易记录对应的儿童信息。
二、简单五步——轻松完成数据处理
将“baby_trade_history”数据集关联有儿童信息的交易记录作为儿童年龄已标注的训练集,未关联儿童信息的记录作为待预测数据集。根据对业务和数据集的理解,儿童年龄与字段cat_id (商品品类)、cat1 (商品基础品类)、property (商品属性)、buy_mount(购买数量)相关性较高。
第一步,构造“baby_trade_history_train”数据集作为模型的训练集
它是由数据集“baby”、“baby_trade_history”数据集内部联接而成。构造数据流如下图3所示,“联接”算子的配置如图4所示。
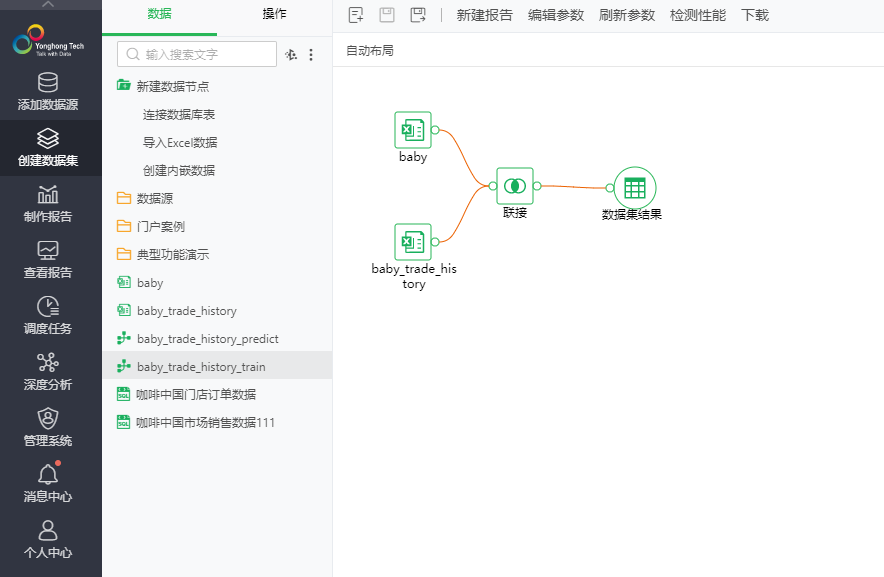
图3 baby_trade_history_train数据集的工作流
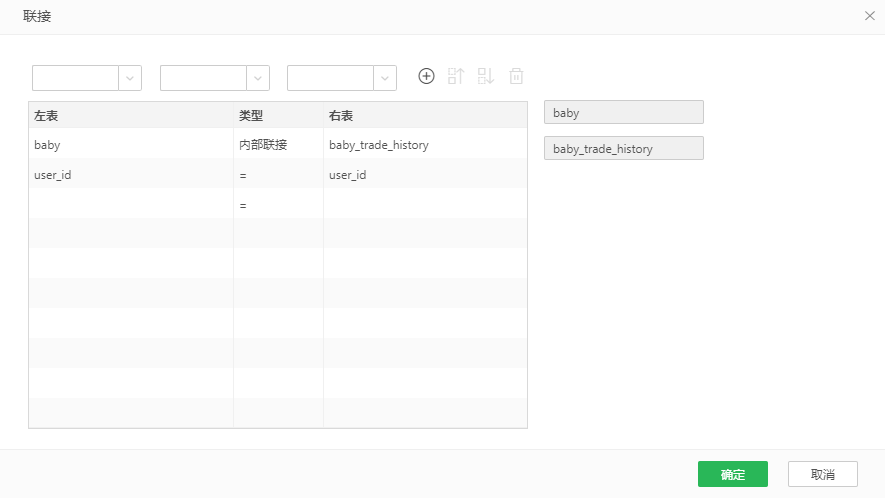
图4 训练集的内部联接配置
第二步,通过交易日期和生日,算出年龄字段
在“baby_trade_history_train”数据集上通过新建计算列生成一个计算列字段age,其取值为根据字段birthday计算出的儿童年龄。该计算列:
“roundUp((dateValue(parseDate(col[‘day’],’yyyyMMdd’))-dateValue(parseDate(col[‘birthday’],’yyyyMMdd’)))/365,1)”
第三步,构造“baby_trade_history_predict”数据集作为模型推理用的待预测数据集
它是由数据集“baby”、“baby_trade_history”数据集右侧联接而成,如图5所示。
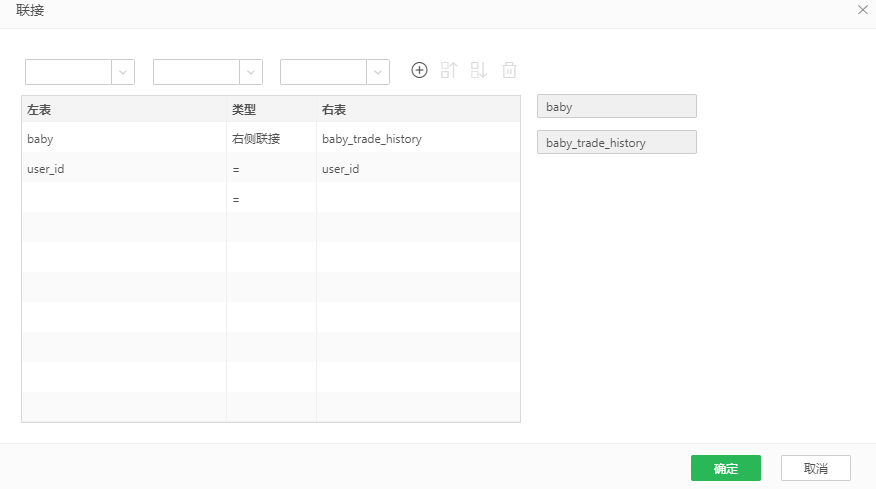
图5 测试集的右侧联接配置
第四步,待预测数据集过滤掉年龄字段不为空的数据行
由于“baby_trade_history”数据集的user_id唯一值数量多于“baby”数据集的记录,右联接后“baby_trade_history_predict”数据集中关于”baby”的有大量空值,如图6所示。在该数据集上添加过滤条件滤出birthday字段含有空值的行作为“baby_trade_history_predict”数据集最终输出,过滤完的结果只剩下在baby数据集里查询不到的数据。过滤条件配置如图7所示。
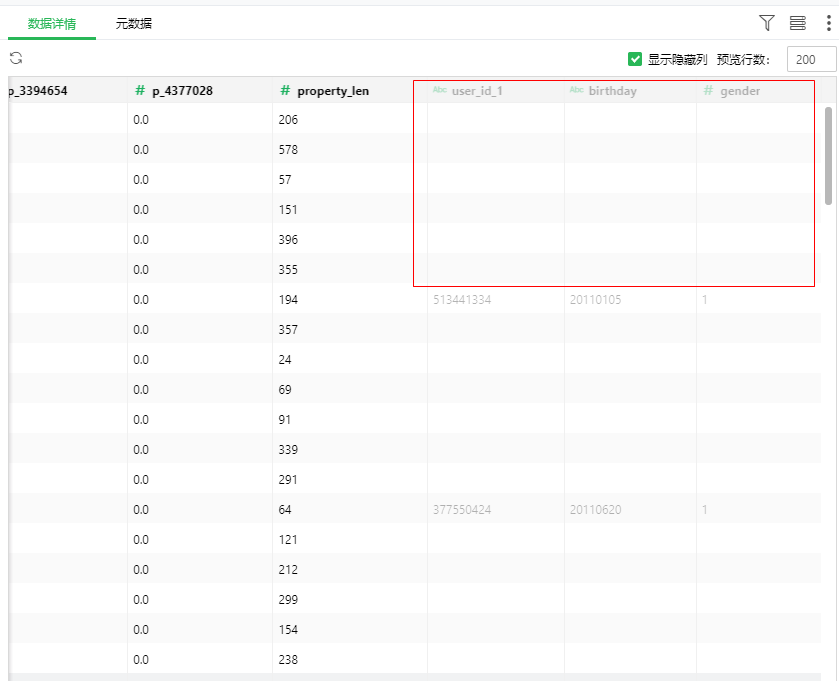
图6 有空值的字段
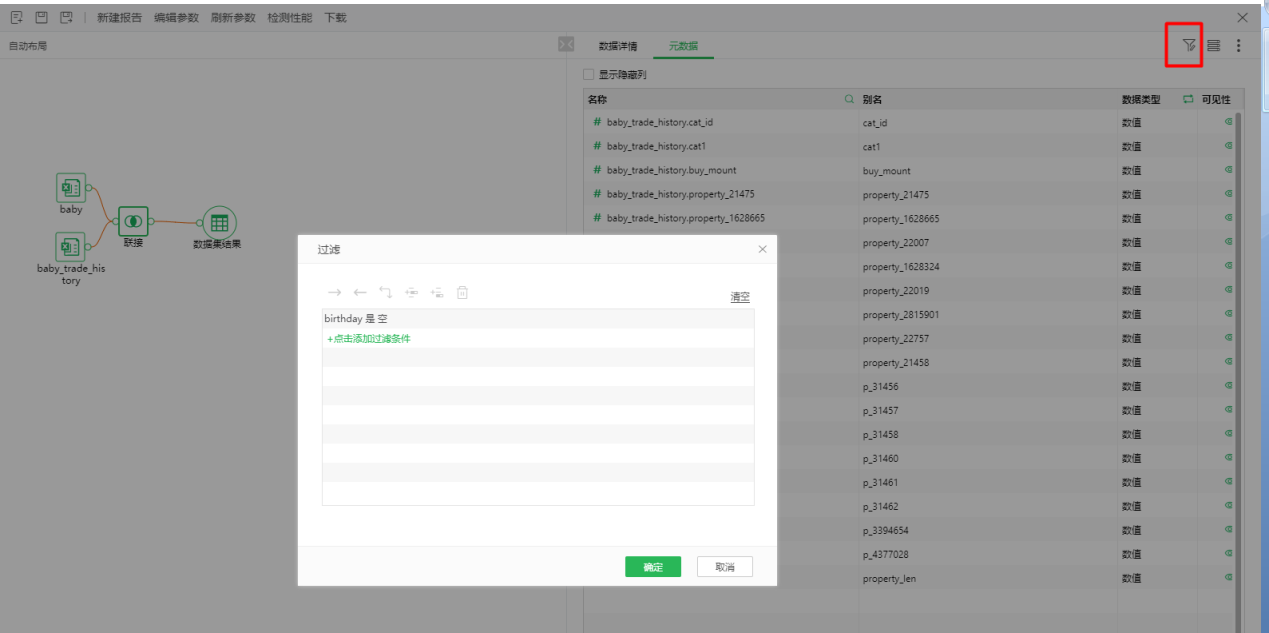
图7 过滤条件
第五步,从property字段构造新特征
property字段的数据如图8所示。
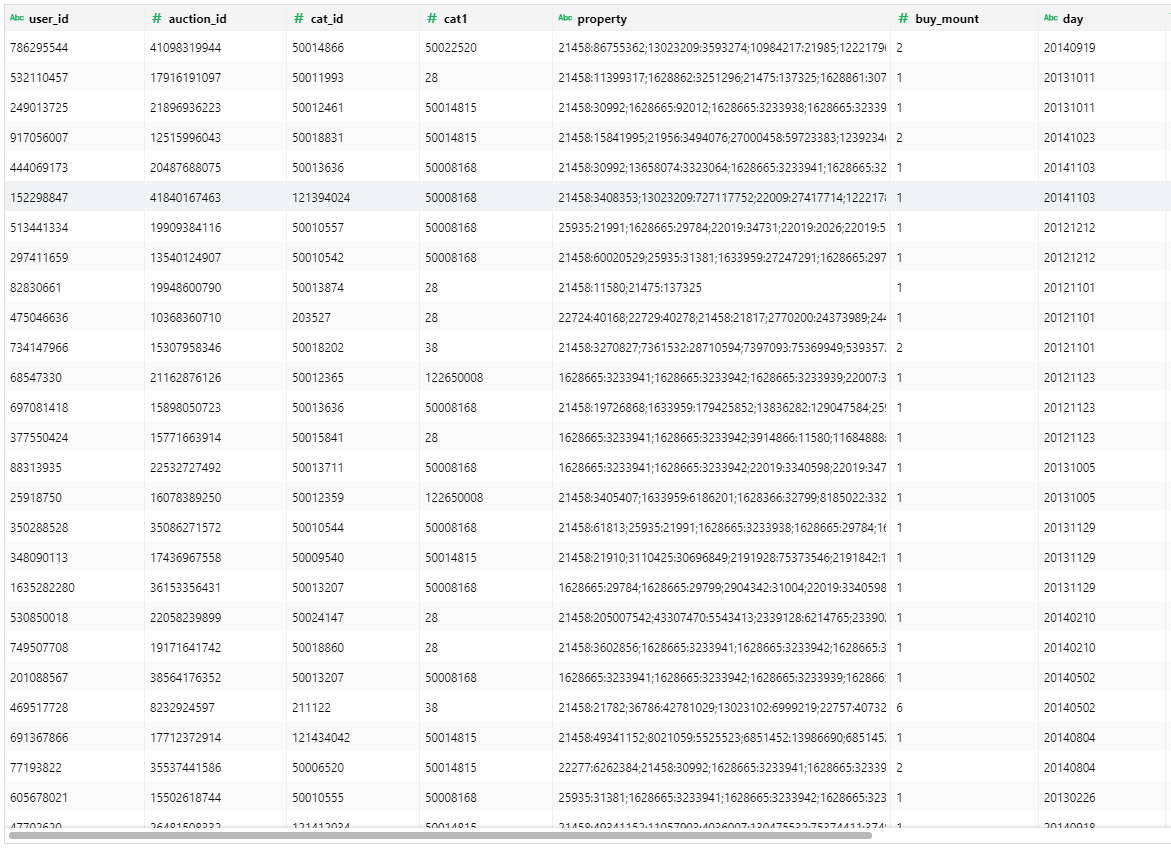
图8 baby_trade_history数据
该字段集中了商品的所有属性名及其取值,但显然不同类型的商品,其属性必然有差异,比如用途、尺寸、重量、材质、商品细分类型等等,不同年龄段的儿童用商品必然有所不同或者儿童偏好不同,这决定了商品属性必然与年龄存在相关性。通过观察数据(图8)发现,property字段将商品属性及其取值以冒号分割同时以分号分割不同的属性,虽然属性及取值均已脱敏,但仍然有利用的价值,于是我尝试用计算列拆分该字段构造出新字段。由于商品属性较多,我分离出了几个常见的商品属性作为计算列,如图9所示,其中:property_len是商品属性个数,其内容为:len(col[‘property’])-len(substitute(col[‘property’],’;’,”))。
property_21458是属性21458对应的值,其计算列内容为:
if contains(ifNull(col[‘property’],’0′),’21458:’) then
parseInt(split(split(col[‘property’],’21458:’,2),’;’,1))/1000
else
0
end
其它属性列对应的计算列同property_21458列。
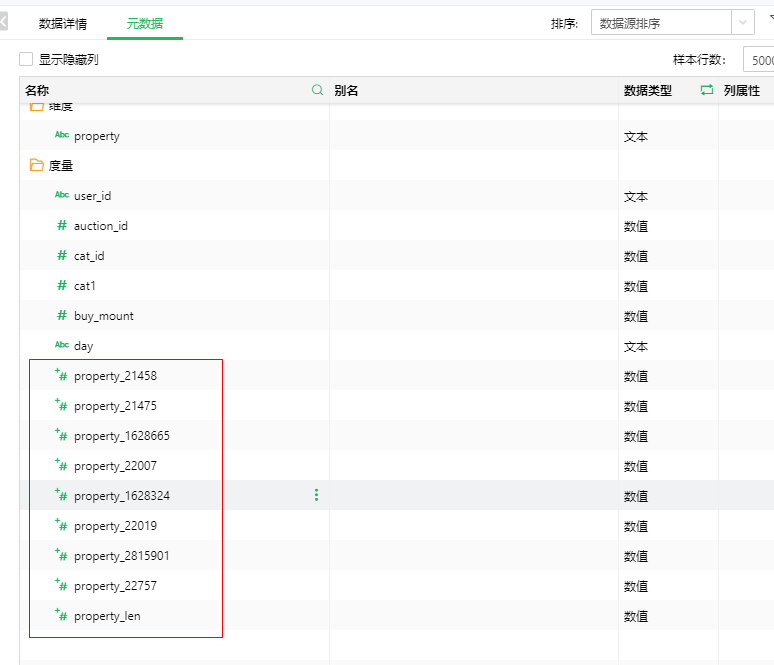
图9 property分离出的新字段(红框内)
经过以上步骤,数据处理完成。
三、快速搭建实验——模型的构建与推理
模型构建
模型构建涉及特征工程和训练过程,在深度分析中是以实验的形式存在的。经过前面数据处理之后,搭建模型实验已经比较简单了。在Yonghong Desktop上创建一个实验,将“数据集”tab下的训练集“baby_trade_history_train”数据集和“操作”tab下“/算法/回归/决策树回归”算子及视图节点拖至实验画布,构建的实验如下图10所示,用到的节点位于图11中标注的位置。
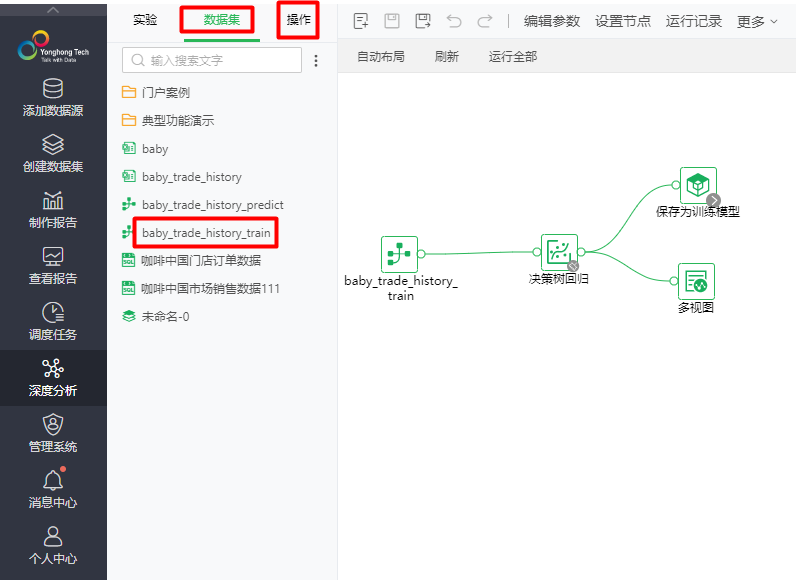
图10 创建的模型训练实验工作流
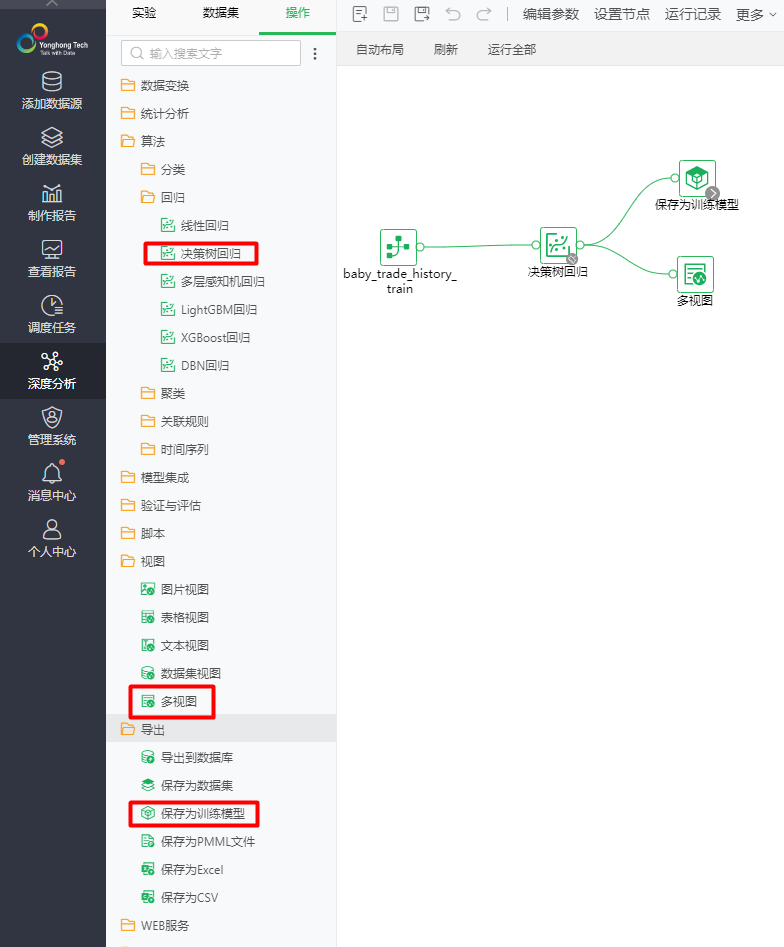
图11 使用的算子
决策树回归的参数配置表如图12所示,调参过程略过,这里大家可以根据对数据和业务的理解自行设置。特征列选择如图13所示,注意字段的顺序是有用的,模型应用的时候字段的含义和顺序需要与这个特征列顺序保持一致。
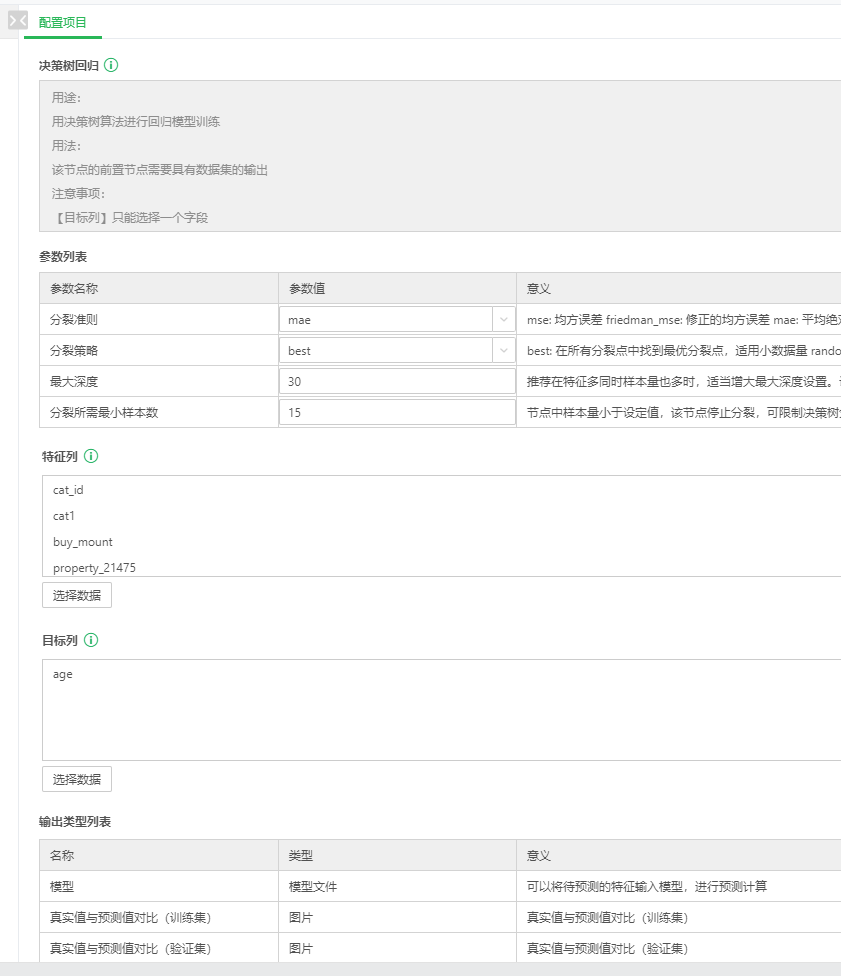
图12 决策树回归算法的参数配置表
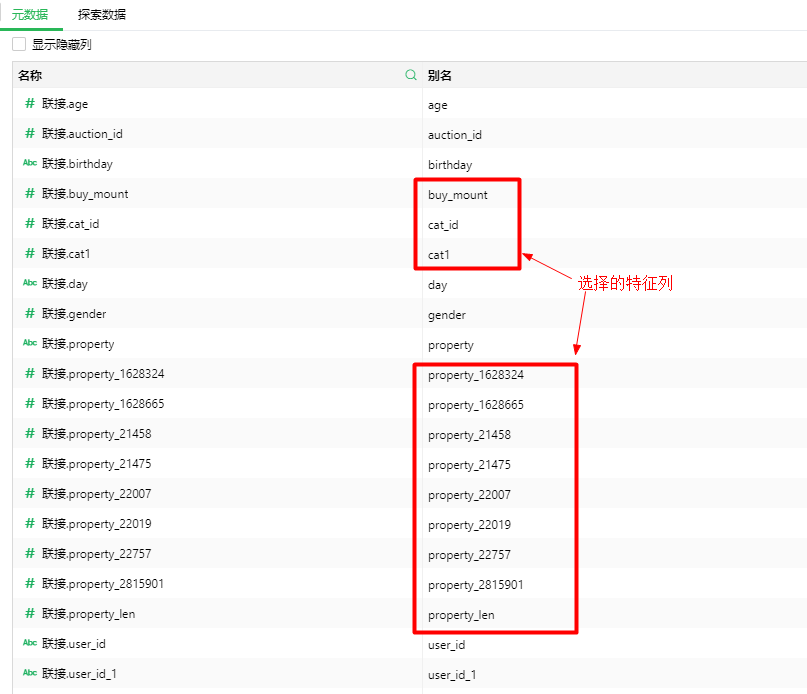
图13 特征列
训练完模型后通过“多视图”节点可以查看其性能指标、特征重要性等,如下图14所示。为了后续应用训练好的模型,我通过“保存为训练模型”及时将模型保存下来(操作过程略),保存的训练模型存放于如图15所示的位置,取名为:儿童年龄预测_训练模型。
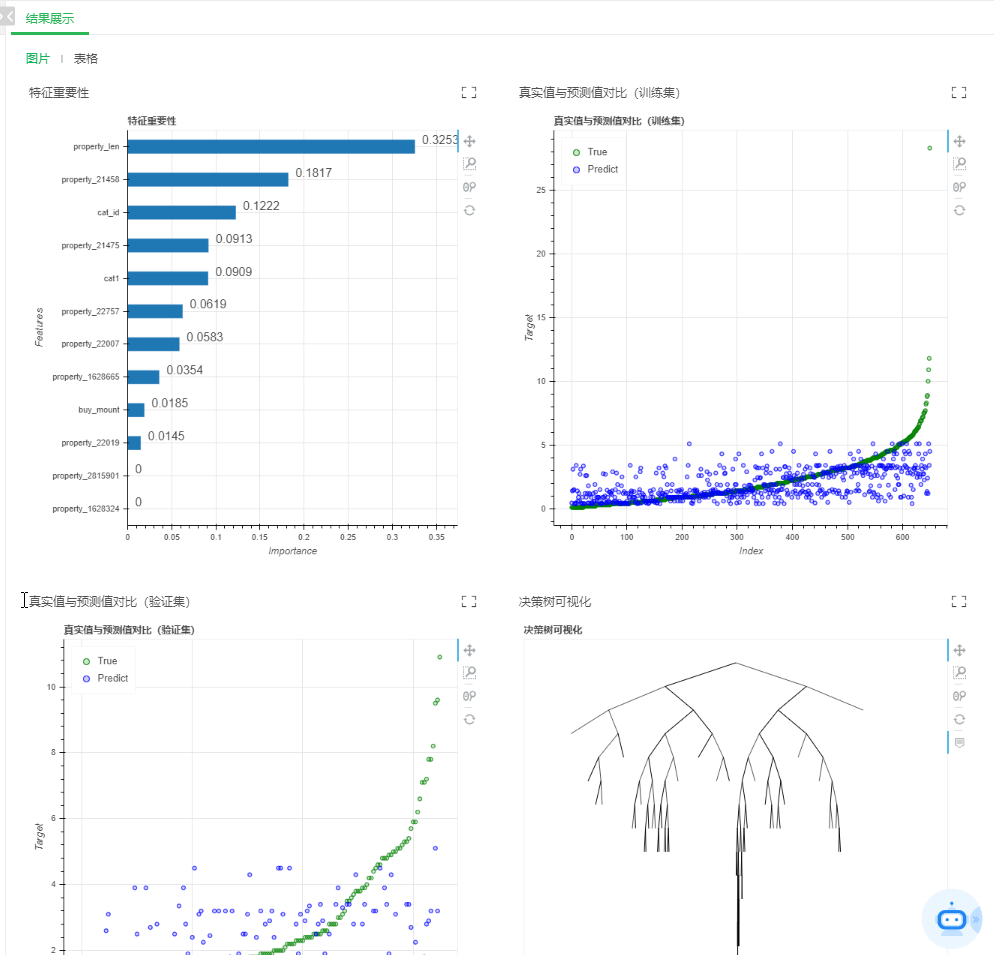
图14 模型性能指标视图
图15 保存的训练模型
特别注意:在搭建模型训练实验的时候,遇到一个小坑。在“创建数据集”模块构建训练集时,如果添加计算列或者更新了计算列的计算逻辑后,在深度分析实验工作流中的训练集“baby_trade_history_train”节点上需要鼠标右键菜单点击“刷新”。
模型推理
保存了训练模型,就可以开始用它搭建模型推理服务工作流了。
第一步,新建一个实验,将预测数据集:baby_trade_history_predict,和刚保存的训练模型:儿童年龄预测_训练模型拖入画布中,创建工作流如图16所示。
第二步,配置模型应用节点。由于训练集和测试集的所选的特征字段完全一样,所以模型应用中填写的特征列与训练模型的字段和顺序完全一致,本实验中的配置如图17所示。
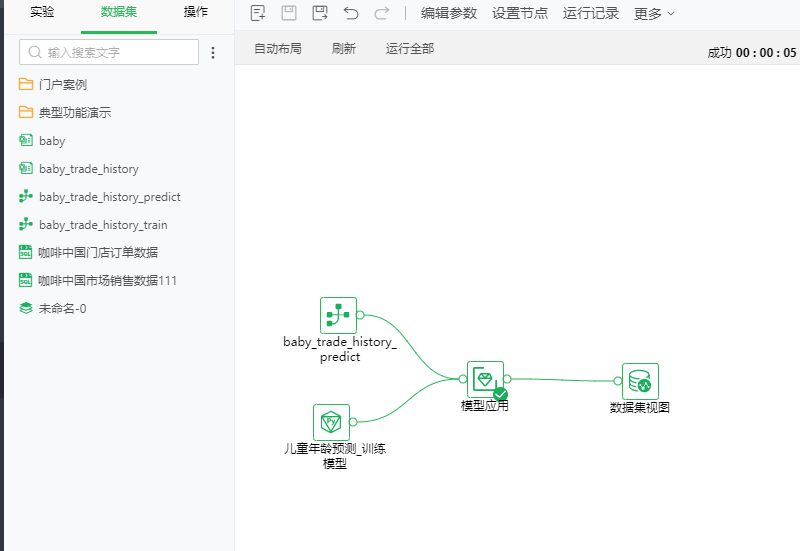
图16 模型推理工作流
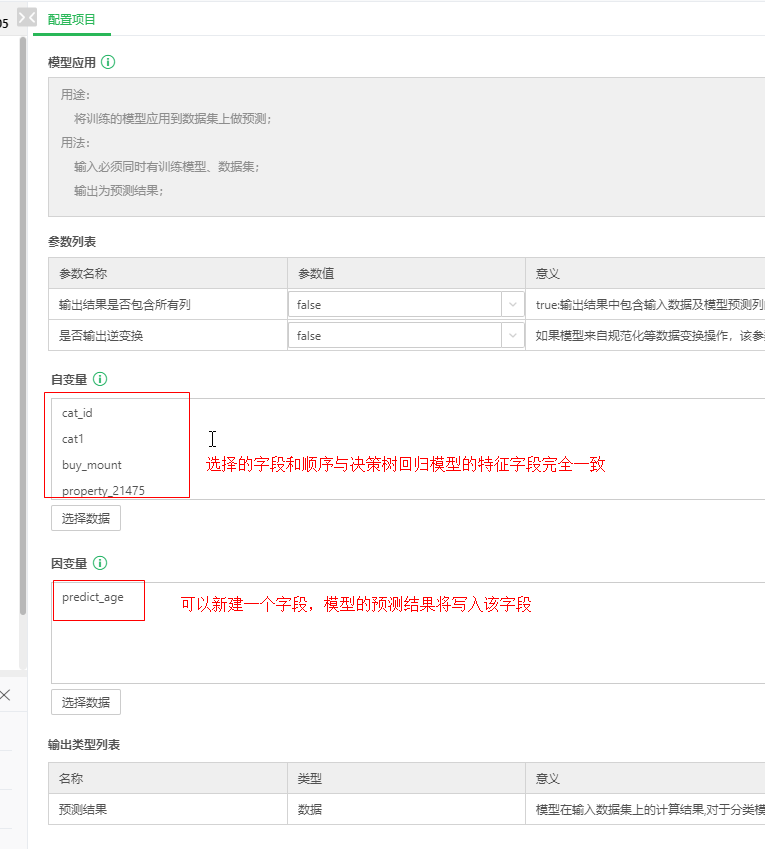
图17 模型应用算子的配置项
predict_age字段是新建的字段,点击图18里的icon进行创建。
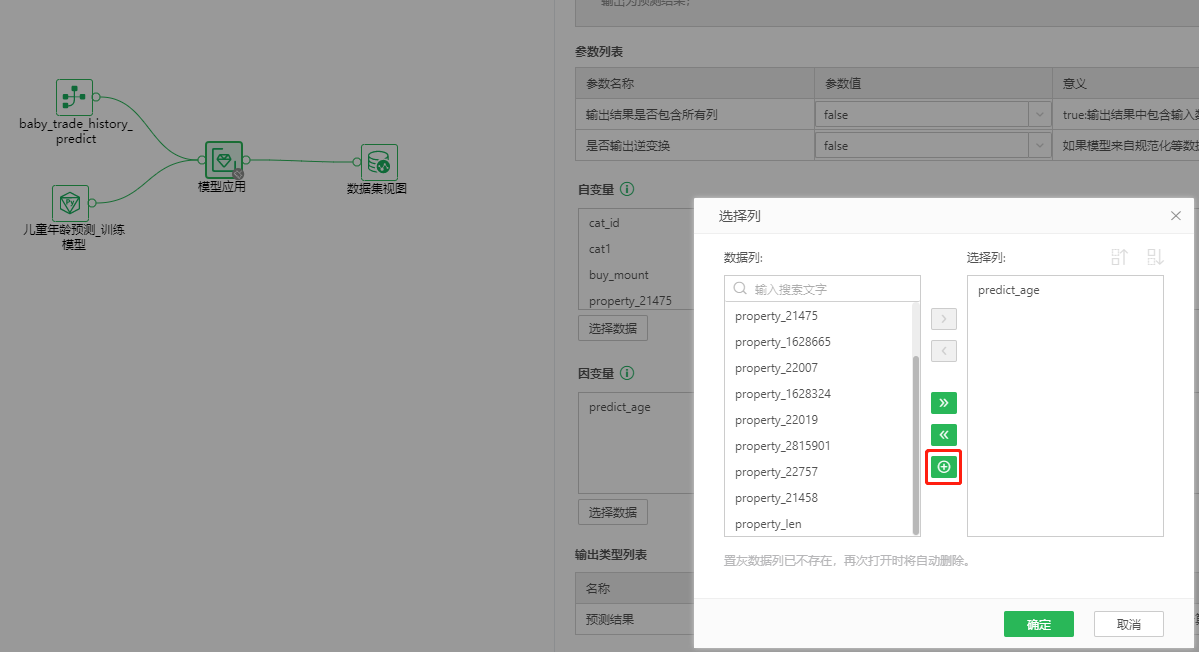
图18 新建字段写入模型预测的结果
第三步,设置制作报告可以使用的节点输出。这里显然模型应用节点的输出是我需要的,直接选择该节点即可,节点设置页面如图19所示。
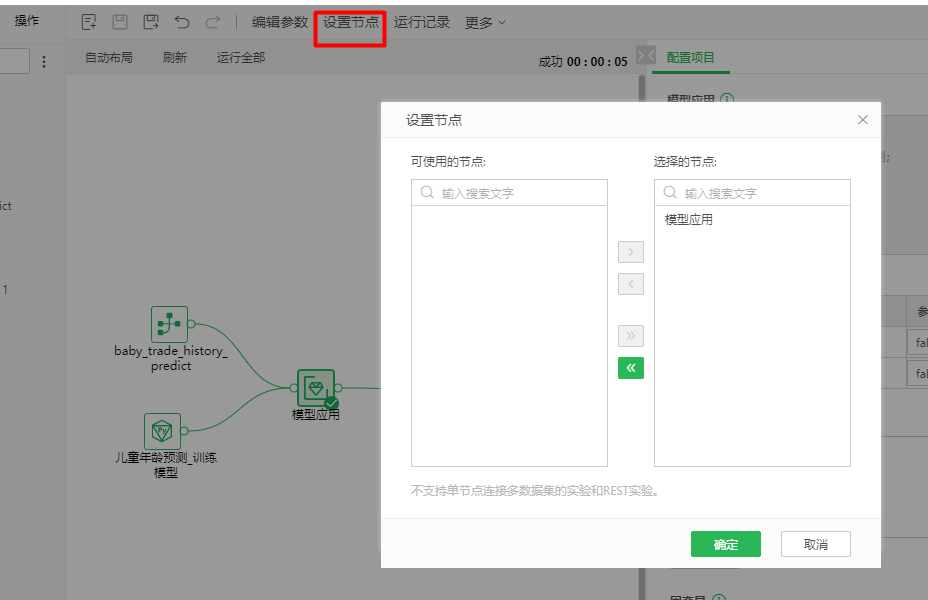
图19 设置用于制作报告的节点
保存该实验,取名为:儿童年龄预测实验。
四、让结果一目了然——制作可视化报告
训练数据集baby_trade_history_train里有age字段,待预测数据集里有预测结果字段predict_age。现在的一个想法,就是把所有交易记录的age和predict_age拼接到一列里,就可以得到所有交易记录的年龄(一部分是实际的,一部分是预测的)。
第一步:合并训练数据集和待预测数据集
这里又用到了自服务数据集进行数据处理,将待预测数据集baby_trade_history_predict和训练数据集baby_trade_history_train做联合得到新数据集baby_trade,如图20。
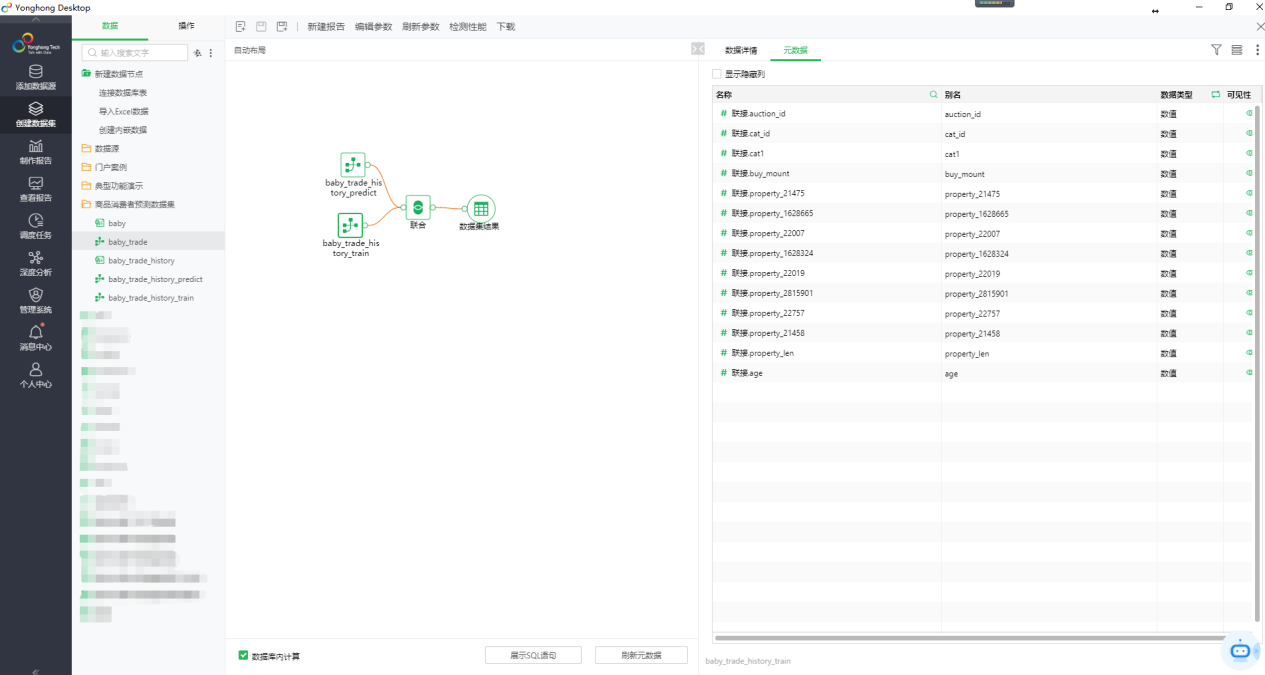
图20 联合之后的数据集baby_trade
特别注意:联合的数据集需要字段相同,字段类型也匹配。
第二步:基于合并的数据集新建报告,并应用实验
基于baby_trade新建报告,选择绑定pane上的应用实验,如图21。
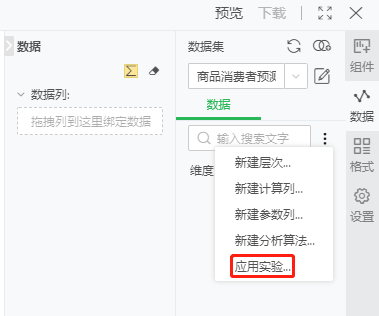
图21 应用实验入口
在弹出的选择实验窗口中,如图22 选择实验窗口,选择儿童年龄预测实验,并选择模型应用节点,点击确定。
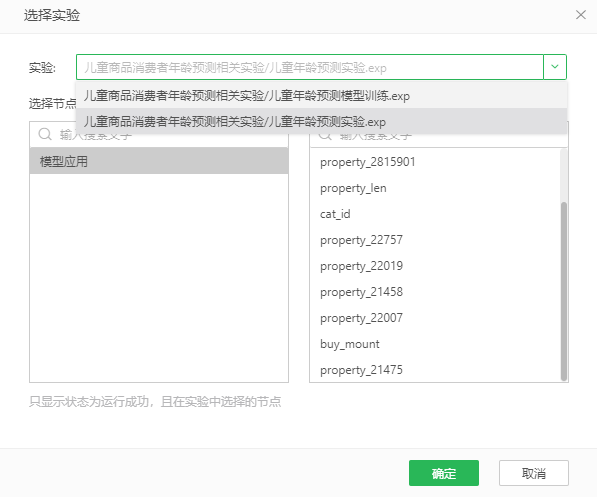
图22 选择实验窗口
在此绑定数据集上,出现模型应用上新增的字段,见图23。
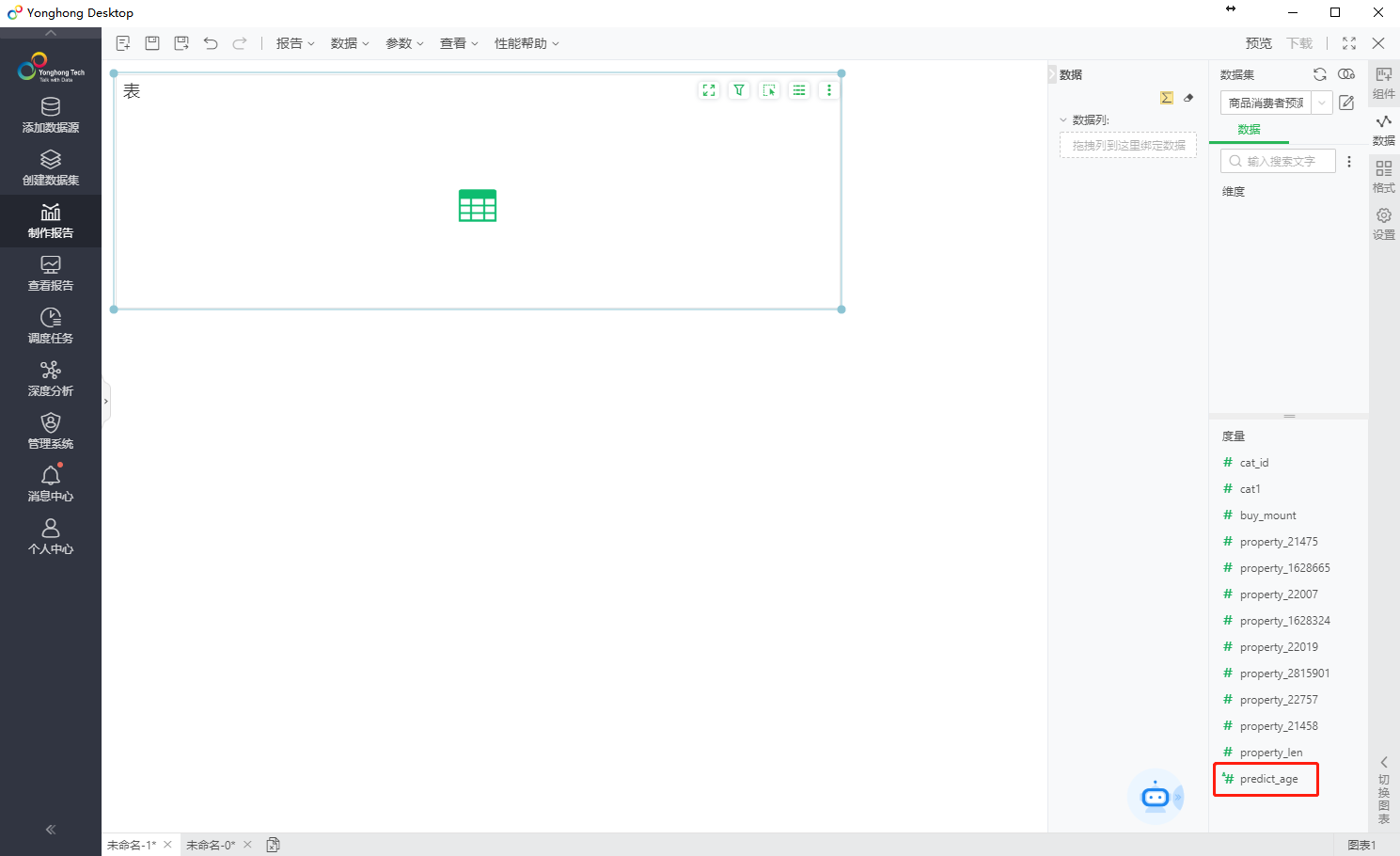
图23 应用实验
第三步:合并age和predict_age字段
新建计算列age_new,进行拼接,见图24。
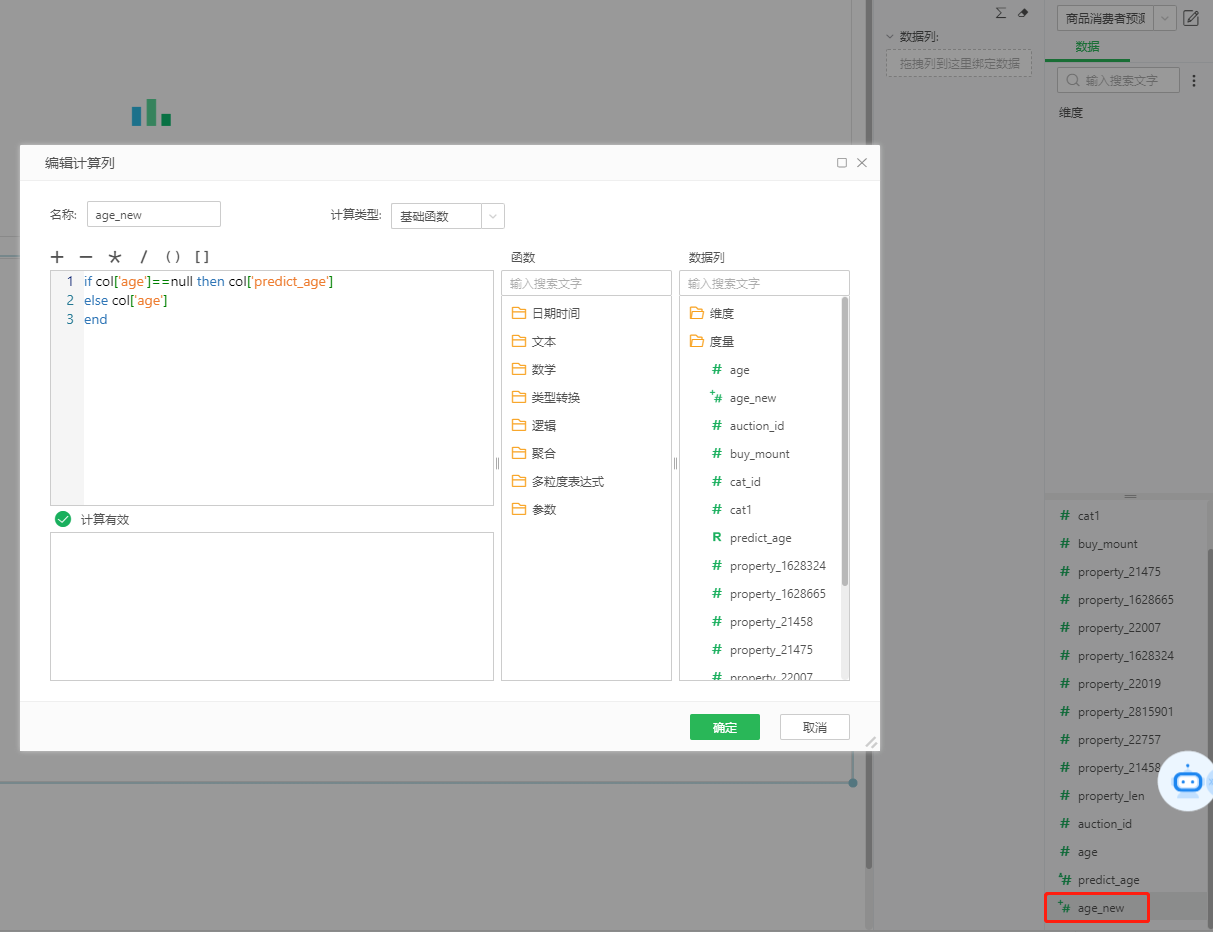
图24 字段拼接
第四步:对每个年龄段进行分组
基于age_new字段新建数据分箱,设置见图25。
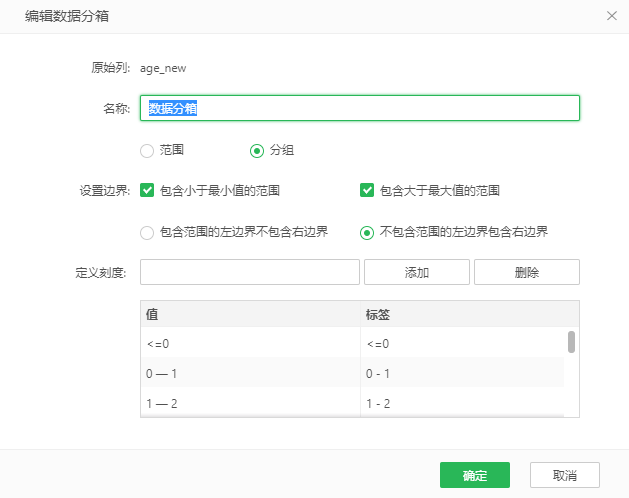
图25 数据分箱
第五步:制作报告
用上面预测和准备的数据,即可在Yonghong Desktop上通过可视化的方式拖拽得到消费商品的年龄分布,不同年龄段的购买情况,不同年龄的商品偏好,不同商品的年龄分布,并由此做精准的商品推荐。我拖拽做了四个图表,基本在分钟级以内搞定,最终展示效果如图26所示。
图26 可视化效果

- 点赞
- 收藏
- 关注作者
评论(0)