《白帽子讲Web安全》读书笔记

起初,研究计算机系统和网络的人,被称为"Hacker",“Hacker"在中国按照音译,被称为“黑客”
第一篇 ,世界安全观
Web安全筒史
起初,研究计算机系统和网络的人,被称为"Hacker",“Hacker"在中国按照音译,被称为“黑客”
对于现代计算机系统来说,在用户态的最高权限是root (administrator),也是黑客们最渴望能够获取的系统最高权限。不想拿到“root"”的黑客,不是好黑客。漏洞利用代码能够帮助黑客们达成这一目标。
黑客们使用的漏洞利用代码,被称为"exploit"。在黑客的世界里,有的黑客,精通计算机技术,能自己挖掘漏洞,并编写exploit;- 只对攻击本身感兴趣,对计算机原理和各种编程技术的了解比较粗浅,因此只懂得编译别人的代码, 自己并没有动手能力,这种黑客被称为
“SriptKids",即“·脚本小子”。
今天已经形成产业的计算机犯罪、网络犯罪中,造成主要破坏的,也是这些“脚本小子”。
中国黑客简史
笔者把中国黑客的发展分为了:启蒙时代、黄金时代、黑暗时代。
黑客技术的发展历程
从黑客技术发展的角度看,在早期,黑客攻击的目标以系统软件居多。
- 一方面,是由于这个时期的Web技术发展还远远不成熟;
- 另一方面,则是因为通过攻击系统软件,黑客们往往能够直接获取root权限。
这段时期,涌现出了非常多的经典漏洞以及"exploit"。比如著名的黑客组织TESO,就曾经编写过一个攻击SSH的exploit,并公然在exploit的banner中宣称曾经利用这个exploit入侵过cia.gov (美国中央情报局)。
2003年的冲击波蠕虫是一个里程碑式的事件,这个针对Windows操作系统RPC服务(运行在445端口)的蠕虫,在很短的时间内席卷了全球,造成了数百万台机器被感染,损失难以估量。在此次事件后,网络运营商们很坚决地在骨干网络上屏蔽了135、445等端口的连接请求。此次事件之后,整个互联网对于安全的重视达到了一个空前的高度。
Web安全的兴起
SQL注入的出现是Web安全史上的一个里程碑,它最早出现大概是在1999年,
- 黑客们发现通过SQL注入攻击,
可以获取很多重要的、敏感的数据,甚至能够通过数据库获取系统访问权限,这种效果并不比直接攻击系统软件差。SQL注入漏洞至今仍然是Web安全领域中的一个重要组成部分。
xss (跨站脚本攻击)的出现则是Web安全史上的另一个里程碑。实际上, xss的出现时间和SQL注入差不多,但是真正引起人们重视则是在大概2003年以后。在经历了MySpace的xSs蠕虫事件后,安全界对xss的重视程度提高了很多, OWASP 2007 TOP 10威胁甚至把xss 排在榜首。
黑帽子,白帽子
- 白帽子,则是指那些精通安全技术,但是工作在反黑客领域的专家们;
- 黑帽子,则是指利用黑客技术造成破坏,甚至进行网络犯罪的群体。
返璞归真,揭秘安全的本质
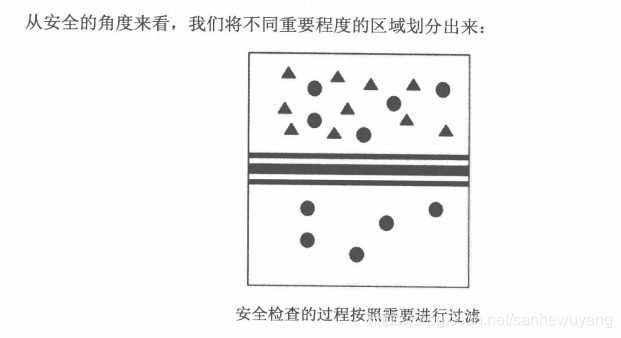
通过一个安全检查(过滤、净化)的过程,可以梳理未知的人或物,使其变得可信任。
- 被划分出来的具有不同信任级别的区域,我们称为
信任域, - 划分两个不同信任域之间的边界,我们称为
信任边界。
数据从高等级的信任域流向低等级的信任域,是不需要经过安全检查的;
数据从低等级的 信任域流向高等级的信任域,则需要经过信任边界的安全检查。
笔者认为,安全问题的本质是信任的问题。
一切的安全方案设计的基础,都是建立在信任关系上的。我们必须相信一些东西,必须有一些最基本的假设,安全方案才能得以建立;如果我们否定一切,安全方案就会如无源之水,无根之木,无法设计,也无法完成。
举例来说,假设我们有份很重要的文件要好好保管起来,能想到的一个方案是把文件“锁".到抽屉里。这里就包含了几个基本的假设,首先,制作这把锁的工匠是可以信任的,他没有私自藏一把钥匙:其次,制作抽屉的工匠没有私自给抽屉装一个后门;最后,钥匙还必须要保管在一个不会出问题的地方,或者交给值得信任的人保管。反之,如果我们一切都不信任,那么也就不可能认为文件放在抽屉里是安全的。当制锁的工匠无法打开锁时,文件才是安全的,这是我们的假设前提之一。但是如果那个工匠私自藏有一把钥匙,那么这份文件也就不再安全了。这个威胁存在的可能性,依赖于对工匠的信任程度。如果我们信任工匠,那么在这个假设前提下,我们就能确定文件的安全性。
这种对条件的信任程度,是确定对象是否安全的基础。
在现实生活中,我们很少设想最极端的前提条件,因为极端的条件往往意味者小概率以及高成本,因此在成本有限的情况下,我们往往会根据成本来设计安全方案,并将一些可能性较大的条件作为决策的主要依据。
因此,把握住信任条件的度,使其恰到好处,正是设计安全方案的难点所在,也是安全这门学问的艺术魅力所在。
破除迷信,没有银弹
安全是一个持续的过程。
安全三要素
安全三要素是安全的基本组成元素,分别是机密性(Confidentiality)、完整性(Integrity),可用性(Availability).
- 机密性要求保护数据内容不能泄露,加密是实现机密性要求的常见手段。
- 完整性则要求保护数据内容是完整、没有被篡改的。常见的保证一致性的技术手段是数字,签名。
- 可用性要求保护资源是“随需而得"。
-
假设一个停车场里有100个车位,在正常情况下,可以停100辆车。但是在某一天,有个坏人搬了100块大石头,把每个车位都占用了,停车场无法再提供正常服务。在安全领域中这种攻击叫做拒绝服务攻击,简称Dos (Denial of Service)。拒绝服务攻击破坏的是安全的可用性。
-
如何实施安全评估

资产等级划分
资产等级划分是所有工作的基础,这项工作能够帮助我们明确目标是什么,要保护什么。
在互联网的基础设施已经比较完善的今天,互联网的核心其实是由用户数据驱动的-用户产生业务,业务产生数据。
互联网公司除了拥有一些固定资产,如服务器等死物外,最核心的价值就是其拥有的用户数据,
所以互联网安全的核心问题,是数据安全的问题。
对互联网公司拥有的资产进行等级划分,就是对数据做等级划分。
当完成资产等级划分后,对要保护的目标已经有了一个大概的了解,接下来就是要·划分信任域和信任边界了。
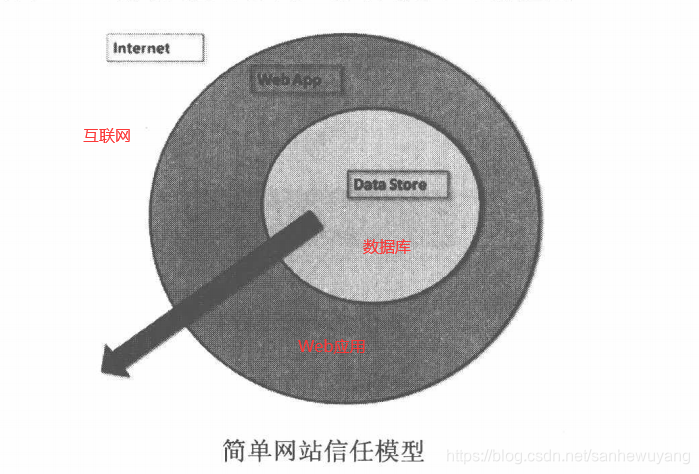
通常我们用一种最简单的划分方式,就是从网络逻辑上来划分。比如最重要的数据放在数据库里,那么把数据库的服务器圈起来; Web应用可以从数据库中读/写数据并对外提供服务,那再把Web服务器圈起来;最外面是不可信任的Internet.
威胁分析
在安全领域里,我们把可能造成危害的来源称为威胁(Threat),而把可能会出现的损失称为风险(Risk),
风险一定是和损失取系在一起的
接下来要提到的“威胁建模”和“风险分析”两个阶段,这两个阶段的联系是很紧密的。什么是威胁分析?
威胁分析就是把所有的威胁都找出来。怎么找?一般是采用头脑风暴法。当然,也有一些比较科学的方法,比如使用一个模型,帮助我们去想,在哪些方面有可能会存在威胁,这个过程能够避免遗漏,这就是威胁建模。
介绍一种威胁建模的方法,它最早是由微软提出的,叫做STRIDE模型。STRIDE是6个单词的首字母缩写,我们在分析威胁时,可以从以下6个方面去考虑。
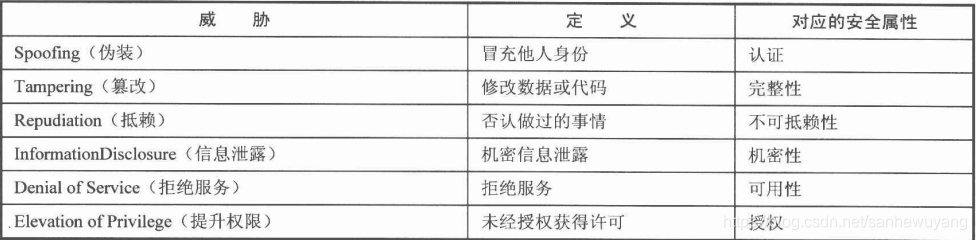
在进行威胁分析时,要尽可能地不遗漏威胁,头脑风暴的过程可以确定攻击面(AttackSurface)在维护系统安全时,最让安全工程师沮丧的事情就是花费很多的时间与精力实施安全方案,但是攻击者却利用了事先完全没有想到的漏洞(漏洞的定义:系统中可能被威胁利用以造成危害的地方。)完成入侵。这往往就是由于在确定攻击面时,想的不够全面而导致的。
风险分析
风险由以下因素组成:
Risk = Probability* Damage Potential
影响风险高低的因素,除了造成损失的大小外,还需要考虑到发生的可能性。
介绍一个DREAD模型,它也是由微软提出的。DREAD也是几个单词的首字母缩写,它指导我们应该从哪些方面去判断一个威胁的风险程度。


设计安全方案
最终,一个优秀的安全方案应该具备以下特点:
- 能够有效解决问题;
- 用户体验好;
- 高性能;
- 低耦合;
- 易于扩展与升级。
白帽子兵法
Secure By Default原则
黑名单、白名单
黑名单、白名单比如,在制定防火墙的网络访问控制策略时,
- 如果
网站只提供Web服务,那么正确的做法是只允许网站服务器的80和443端口对外提供服务,屏蔽除此之外的其他端口。这是一种“白·名单”的做法; - 如果使用“黑名单”,则可能会出现问题。
假设黑名单的策略是:不允许SSH端口对Internet开放,那么就要审计SSH的默认端口: 22端口是否开放了Internet。
但在实际工作过程中,经常会发现有的工程师为了偷懒或图方便,私自改变了SSH的监听端口,比加把SSH的端口从22改到了2222,从而绕过了安全策略。
在网站的生产环境服务器上,应该限制随意安装软件,而需要制定统一的软件版本规范。 这个规范的制定,也可以选择白名单的思想来实现。按照白名单的思想,应该根据业务需求,列出一个允许使用的软件以及软件版本的清单,在此清单外的软件则禁止使用。如果允许工程师在服务器上随意安装软件的话,则可能会因为安全部门不知道、不熟悉这些软件而导致一些漏洞,从而扩大攻击面。
最小权限原则最小权限原则要求系统只授予主体必要的权限,而不要过度授权,这样能有效地减少系统、网络、应用、数据库出错的机会。
- 比如在
Linux系统中,一种良好的操作习惯是使用普通账户登录,在执行需要root权限的操作时,再通过sudo命令完成。这样能最大化地降低一些误操作导致的风险;同时普通账户被盗用后,与root帐户被盗用所导致的后果是完全不同的。
纵深防御原则
纵深防御包含两层含义:,
- 要在各个不同层面、不同方面实施安全方案,避免出现疏漏,不同安全方案之间需要相互配合,构成一个整体;
- 要在正确的地方做正确的事情,即:在解决根本问题的地方实施针对性的安全方案。
某矿泉水品牌曾经在广告中展示了一滴水的生产过程:经过十多层的安全过滤,去除有害物质,最终得到一滴饮用水。
这种多层过滤的体系,就是一种纵深防御,是有立体层次感的安全方案。
纵深防御并不是同一个安全方案要做两遍或多遍,而是要从不同的层面、不同的角度对系· 统做出整体的解决方案。
在常见的入侵案例中,大多数是利用web应用的漏洞,攻击者先获得一个低权限的webshell然后通过低权限的webshell上传更多的文件,并尝试执行更高权限的系统命令,尝试在服务器上提升权限为root;接下来攻击者再进一步尝试渗透内网,比如数据库服务器所在的网段。
常有必要将风险分散到系统的各个层面。就入侵的防御来说,我们需要考虑的可能有Web应用安全、OS系统安全、数据库安全、网络环境安全等。在这些不同层面设计的安全方案,将共同组成整个防御体系,这也就是纵深防御的思想。
纵深防御的第二层含义,是要在正确的地方做正确的事情。如何理解呢?它要求我们深入理解威胁的本质,从而做出正确的应对措施。
对于一个复杂的系统,纵深防御是构建安全体系的必要选择。
数据与代码分离原则
实际上,缓冲区溢出,也可以认为是程序违背了这一原则的后果-程序在栈或者堆中,将用户数据当做代码执行,混淆了代码与数据的边界,从而导致安全问题的发生。
在Web安全中,由·“注入”·引起的问题比比皆是,如XSS. SQL Injection, CRLF Injection.. X-Path Injection等。此类问题均可以根据“数据与代码分离原则”设计出真正安全的解决方案,因为这个原则抓住了漏洞形成的本质原因。以XSS为例,它产生的原因是HTML Injection或JavaScript Injection,
不可预测性原则
微软的Windows系统用户多年来深受缓冲区溢出之苦,因此微软在Windows的新版本中增加了许多对抗缓冲区溢出等内存攻击的功能。微软无法要求运行在系统中的软件没有漏洞,因此它采取的做法是让漏洞的攻击方法失效。比如,使用DEP来保证堆栈不可执行,使用ASLR让进程的栈基址随机变化,从而使攻击程序无法准确地猜测到内存地址,大大提高了攻击的门,槛。经过实践检验,证明微软的这个思路确实是有效的–即使无法修复code,但是如果能够使得攻击的方法无效,那么也可以算是成功的防御。微软使用的ASLR技术,在较新版本的Linux内核中也支持。在ASLR的控制下,一个程序每次启动时,其进程的栈基址都不相同,具有一定的随机性,对于攻击者来说,这就是“不可预测性"。
不可预测性原则,可以巧妙地用在一些敏感数据上。比如在CSRF的防御技术中,通常会使用一个token来进行有效防御。这个token能成功防御CSRF,就是因为攻击者在实施CSRF攻击的过程中,是无法提前预知这个token值的,因此要求token足够复杂时,不能被攻击者·猜测到。
不可预测性的实现往往需要用到加密算法、随机数算法、哈希算法,好好使用这条原则,在设计安全方案时往往会事半功倍。
第二篇 客户端脚本安全
第2章浏览器安全
同源策略
同源策略(Same Origin Policy)是一种约定,它是浏览器最核心也最基本的安全功能
如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略的基础之上的,```浏览器只是针对同源策略的一种实现`。对于客户端Web安全的学习与研究来说,深入理解同源策略是非常重要的,也是后续学习的基础。
很多时候浏览器实现的同源策略是隐性、透明的,很多因为同源策略导致的问题并没有明显的出错提示,如果不熟悉同源策略,则可能一直都会想不明白问题的原因。
浏览器的同源策略,限制了来自不同源的"document"或脚本,对当前"document"读取或设置某些属性。
这一策略极其重要,试想如果没有同源策略,可能a.com的一段JavaScript脚本,在b.com未曾加载此脚本时,也可以随意涂改b.com的页面(在浏览器的显示中)。为了不让浏览器的页面行为发生混乱,浏览器提出了"Origin" (源)这一概念,来自不同Origin的对象无法互相干扰。对于JavaScript来说,以下情况被认为是同源与不同源的。!
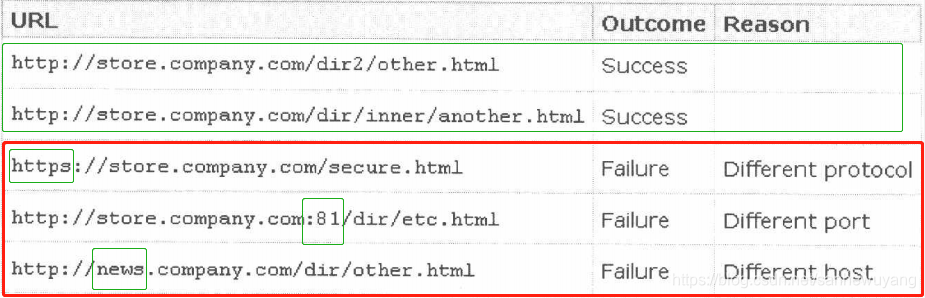
由上表可以看出,影响“源”的因素有: host (域名或IP地址,如果是IP地址则看做一个根域名)、子域名、端口、协议。
需要注意的是,对于当前页面来说,页面内存放JavaScript文件的域并不重要,重要的是.加载JavasScript页面所在的域是什么。换言之, a.com通过以下代码:
<script src="https://b.com/b.js"></script>
加载了b.com上的b.js,但是b.js是运行在a.com页面中的,因此对于当前打开的页面(a.com页面)来说, b.js的Origin就应该是a.com而非b.com。在浏览器中,<script>,、 <iframe>、 <link>等标签都可以跨域加载资源,而不受同源策略的限制。这些带"src"属性的标签每次加载时,实际上是由浏览器发起了一次GET请求。
不同于XMLHttpRequest的是,通过src属性加载的资源,浏览器限制了Javascript的权限,使其不能读、写返回的内容。对于 XMLHttpRequest来说,它可以访问来自同源对象的内容。比如下例:
<html>
<head>
<script type=text/Javascript">
var xmihttp;
function loadXMLDoc(url) {
xmlhttp = null;
if (window.XMLHttpRequest) {// code forFirefox, Opera, IE7, etc.
xmlhttp = new XMLHttpRequest();
} else if (window.Activexobject) {// code for IE6,IE5
xmlhttp = new Activexobject("Microsoft. XMLHTTP");
}
if (xmlhttp != null) {
xmlhttp.onreadystatechange = state_Change;
xmlhttp.open("GET", url, true);
xmlhttp.send(null);
} else {
alert("Your browser does not support xMLHTTP.")
}
}
function state_Change() {
if (xmlhttp.readystatem == 4) {
if (xmlhttp.status == 200) {// 200= "OK
document.getElementById("T1").innerHTML = xmlhttp.responseText;
} else {
alert("problem retrieving data:" + xmlhttp.statusText
}
}
}
</script>
</head>
<body onload="loadxMLDoc('/example/xdom/test xmlhttp.txt')">
<button onclick="loadXMLDoc('/example/xdom/test xmlhttp2.txt') ">Click</button>
</body>
</html>
但XMLHttpRequest受到同源策略的约束,不能跨域访问资源,在AJAX应用的开发中尤其需要注意这一点。
如果XMLHttpRequest能够跨域访问资源,则可能会导致一些敏感数据泄露,比如CSRF的token,从而导致发生安全问题。但是互联网是开放的,随着跨域请求的需求越来越迫切
w3C委员会制定了XMLHttpRequest跨域访问标准。它需要通过目标域返回的HTTP头来授权是否允许跨域访问,因为HTTP头对于JavaScript来说一般是无法控制的,所以认为这个方案可以实施。注意:这个跨域访问方案的安全基础就是信任"JavaScript无法控制该HTTP头”
对于浏览器来说,除了DOM, Cookie,XMLHttpRequest会受到同源策略的限制外,一些第三方插件也有各自的同源策略。最常见的一些插件如Flash, Java Applet.Silverlight. Google Gears等都有自己的控制策略。
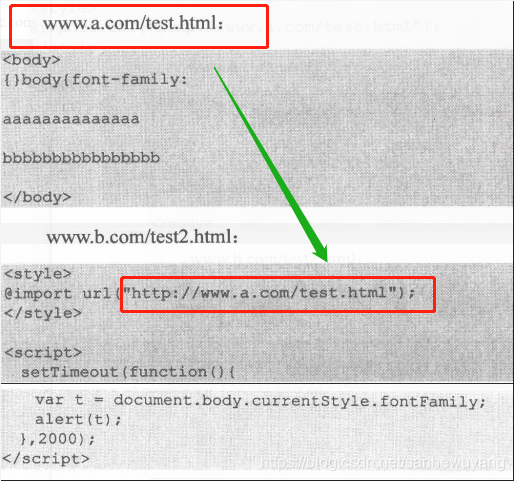
在www.b.com/test2.html中通过@import加载了http://www.a.com/test.html为Css文件,渲染进入当前页面DOM,同时通过document.body.currentStyle.fontFamily访问此内容。问题发生在IE的CSS Parse的过程中, IE将fontFamily后面的内容当做了value,从而可以读取www.a.com/test.html的页面内容。
<script>等标签仅能加载资源,但不能读、写资源的内容,而这个漏洞能够跨域读取页面内容,因此绕过了同源策略,成为一个跨域漏洞。浏览器的同源策略是浏览器安全的基础,
同源策略一旦出现漏洞被绕过,也将带来非常严重的后果,很多基于同源策略制定的安全方案都将失去效果。
浏览器沙箱
“挂马”:在网页中插入一段恶意代码,利用浏览器漏洞执行任意代码的攻击方式,在黑客圈子里被形象地称为“挂马”。
“挂马”是浏览器需要面对的一个主要威胁。
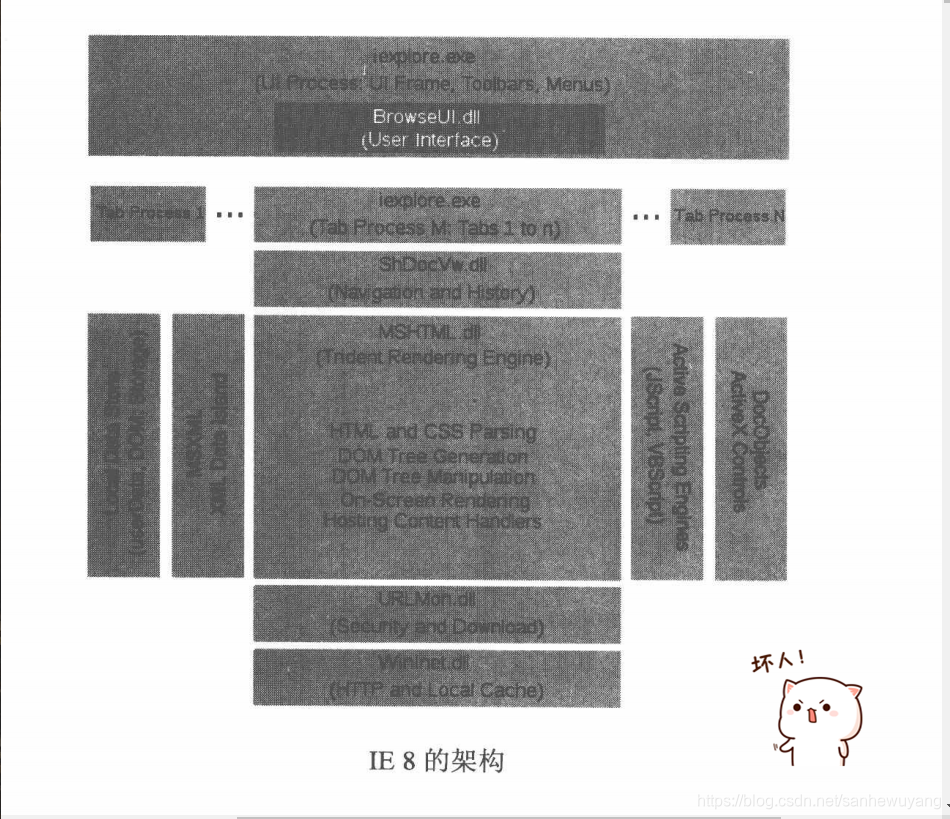
近年来,独立于杀毒软件之外,浏览器厂商根据挂马的特点研究出了一些对抗挂马的技术。比如在Windows系统中,浏览器密切结合
DEP, ASLR, SafesEH等操作系统提供的保护技术,对抗内存攻击。与此同时,浏览器还发展出了多进程架构,从安全性上有了很大的提高。浏览器的多进程架构,将浏览器的各个功能模块分开,各个浏览器实例分开,当一个进程崩溃时,也不会影响到其他的进程。
Google Chrome是第一个采取多进程架构的浏览器。Google Chrome的主要进程分为:浏览器进程、渲染进程、插件进程、扩展进程。插件进程如flash、 java, pdf等与浏览器进程严格隔离,因此不会互相影响。
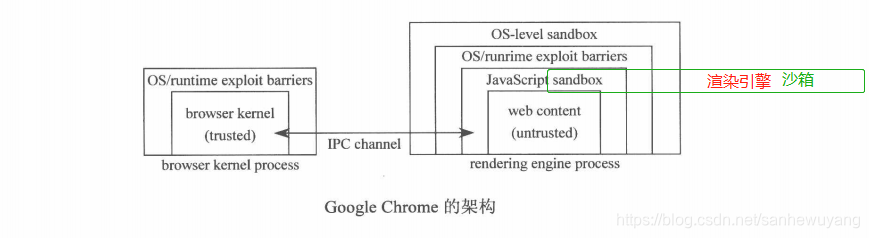
渲染引擎由Sandbox隔离,网页代码要与浏览器内核进程通信、与操作系统通信都需要通过IPC channel,在其中会进行一些安全检查。
Sandbox即沙箱, Sandbox已经成为泛指“资源隔离类模块”的代名词。Sandbox的设计目的一般是为了让不可信任的代码运行在一定的环境中,限制不可信任的代码访问隔离区之外的资源。如果一定要跨越Sandbox边界产生数据交换,则只能通过指定的数据通道
Sandbox的应用范围非常广泛。比如一个提供hosting服务的共享主机环境,假设支持用户上传PHP, Python、 Java等语言的代码,为了防止用户代码破坏系统环境,或者是不同用户之间的代码互相影响,则应该设计一个Sandbox对用户代码进行隔离。
·Sandbox需要考虑用户代码针对本地文件系统、内存、数据库、网络的可能请求·,可以采用默认拒绝的策略,对于有需要的请求,则可以通过封装API的方式实现。
而对于浏览器来说,采用Sandbox技术,无疑可以让不受信任的网页代码、JavaScript代码运行在一个受到限制的环境中,从而保护本地桌面系统的安全。

恶意网址拦截
钓鱼网站、诈骗网站对于用户来说也是一种恶意网址。为了保护用户安全,浏览器厂商纷纷推出了各自的拦截恶意网址功能。目前各个浏览器的拦截恶意网址的功能都是基于“黑名单”的。
恶意网址拦截的工作原理:,一般都是浏览器周期性地从服务器端获取一份最新的恶意网址黑名单,如果用户上网时访问的网址存在于此黑名单中,浏览器就会弹出一个警告页面。
常见的恶意网址分为两类:
- 一类是挂马网站,这些网站通常包含有恶意的脚本如JavaScript或Flash,通过利用浏览器的漏洞(包括一些插件、控件漏洞)执行shellcode,在用户电脑中植入木马;
- 一类是钓鱼网站,通过模仿知名网站的相似页面来欺骗用户。
PhishTank是互联网上免费提供恶意网址黑名单的组织之一,它的黑名单由世界各地的志愿者提供,且更新频繁。
除了恶意网址黑名单拦截功能外,主流浏览器都开始支持 EV SSL证书(Extended Validation’SSL. Certificate),以增强对安全网站的识别。
高速发展的浏览器安全.
当用户访问的URL中包含了Xss攻击的脚本时, IE就会修改其中的关键字符使得攻击无法成功完成,并对用户弹出提示框。
第3章跨站脚本攻击(XSS)
xss简介
跨站脚本攻击,英文全称是Cross Site Script,本来缩写是css,但是为了和层叠样式表Cascading Style Sheet, CSS)有所区别,所以在安全领域叫做"XSS"
xss攻击,通常指黑客通过"HTML注入”篡改了网页,插入了恶意的脚本,从而在用户浏览网页时,控制用户浏览器的一种攻击。 在一开始,这种攻击的演示案例是跨域的,所以叫做“跨站脚本”。
xss长期以来被列为客户端Web安全中的头号大敌。
-
反射型xSs,:反射型xSS反射型xSS只是简单地把用户输入的数据“反射”给浏览器。也就是说,黑客往往需要诱使用户“点击”一个恶意链接,才能攻击成功。反射型xss也叫做“非持久型xSs"(Non-persistent XSS)。

再查看源代码:<script>alert (/xss/)</scriptx -
第二种类型:存储型xss存储型XSS会把用户输入的数据“存储”在服务器端。这种XSS具有很强的稳定性。

比较常见的一个场景就是,黑客写下一篇包含有恶意JavaScript代码的博客文章,文章发表后,所有访问该博客文章的用户,都会在他们的浏览器中执行这段恶意的JavaScript代码。黑客把恶意的脚本保存到服务器端,所以这种
XSs攻击就叫做“存储型XSs"
- 第三种类型: DOM Based XSS实际上,这种类型的XSs并非按照“数据是否保存在服务器端”来划分, DOM Based xss, 从效果上来说也是反射型xSs。单独划分出来,是因为DOM Based Xss的形成原因比较特别,发现它的安全专家专门提出了这种类型的xss。出于历史原因,也就把它单独作为一个分类了。通过修改页面的DOM节点形成的xss,称之为DOM Based XSS.


xss攻击进阶
初探XSS Payload
xss攻击成功后,攻击者能够对用户当前浏览的页面植入恶意脚本,通过恶意脚本,控制用户的浏览器。这些用以完成各种具体功能的恶意脚本,被称为"XSS Payload"
XSS Payload实际上就是Javascript脚本(还可以是Flash或其他富客户端的脚本),
一个最常见的XSS Payload,就是通过读取浏览器的Cookie对象,从而发起"Cookie劫持攻击。Cookie中一般加密保存了当前用户的登录凭证。Cookie如果丢失,往往意味着用户的登录凭证丢失。换句话说,攻击者可以不通过密码,而直接登录进用户的账户。如下所示,攻击者先加载一个远程脚本:

利用自定义Cookie访问网站”的过程是一样的
当前的Web中, Cookie一般是用户登录的凭证,浏览器发起的所有请求都会自动带上Cookie,如果Cookie没有绑定客户端信息,当攻击者窃取了Cookie后,就可以不用密码登录进用户的账户。Cookie的"HttpOonly"标识可以防止"Cookie劫持”,我们将在稍后的章节中再具体介绍。
强大的XSS Payload
"Cookie劫持”并非所有的时候都会有效。有的网站可能会在Set-Cookie时给关键Cookie植入HttpOnly标识;有的网站则可能会把Cookie与客户端IP绑定(相关内容在"XSS的防御”一节中会具体介绍),从而使得xss窃取的Cookie失去意义。
构造GET与POST请求
一个网站的应用,只需要接受HTTP协议中的GET或POST请求,即可完成所有操作。"对于攻击者来说,仅通过JavaScript,就可以让浏览器发起这两种请求。博客上有一篇文章,想通过xss删除它,该如何做呢?
Get請求:

POST請求:

也可以通过Ajax发送。
xSS钓鱼
xss的攻击过程都是在浏览器中通过JavaScript脚本自动进行的,也就是说,缺少“与用户交互”的过程。
- 对于验证码, XSS Payload可以通过读取页面内容,将验证码的图片URL发送到远程服务器上来实施–攻击者可以在远程xss后台接收当前验证码,并将验证码的值返回给当前的xSS Payload,从而绕过验证码。
- 修改密码的问题稍微复杂点。为了窃取密码,攻击者可以将XSs与“钓鱼”相结合。实现思路很简单:利用JavaScript在当前页面上“画出”一个伪造的登录框,当用户在登录框中输入用户名与密码后,其密码将被发送至黑客的服务器上。
识别用户浏览器
如果知道用户使用的浏览器、操作系统,攻击者就有可能实施一次精准的浏览器内存攻击,最终给用户电脑植入一个木马。
xSs能够帮助攻击者快速达到收集信息的目的。如何通过JavaScript脚本识别浏览器版本呢?最直接的莫过于通过xsS读取浏览器UserAgent对象:alert (navigator.userAgent);

识别用户安装的软件
在IE中,可以通过判断·Activex控件的classid是否存在,来推测用户是否安装了该软件。这种方法很早就被用于“挂马攻击”-黑客通过判断用户安装的软件,选择对应的浏览器漏洞,最终达到植入木马的目的。
Firefox的插件(Plugins)列表存放在一个DOM对象中,通过查询DOM可以遍历出所有的插件
CSS History Hack
我们再看看另外一个有趣的XSs Payload-通过css,来发现一个用户曾经访问过的网站。其原理是利用style的visited属性-如果用户曾经访问过某个链接,那么这个链接的颜色会变得与众不同:
获取用户的真实IP地址
通过XSS Payload还有办法获取一些客户端的本地IP地址。
用户电脑使用了·代理服务器,或者在局域网中隐藏在NAT后面。网站看到的客户端IP地址,是内网的出口IP地址,而并非用户电脑真实的本地IP地址。javascript本身沒有提供方法。
- 客户端安装了Java环境(JRE),那么xss就可以通过调用Java Applet的接口获取客户端的本地IP地址。
Xss攻击平台
- Attack API: Attack API"是安全研究者pdp所主导的一个项目,它总结了很多能够直接使用xssPayload,归纳为API的方式。比如上节提到的“获取客户端本地信息的API"就出自这个项目。
- BeEF :BeEF"曾经是最好的xss演示平台。不同于Attack API, BeEF所演示的是一个完整的xss攻击过程。BeEF有一个控制后台,攻击者可以在后台控制前端的一切。
- Xss-ProxyXSS-Proxy是一个轻量级的xss攻击平台,通过嵌套iframe的方式可以实时地远程控制被xss攻击的浏览器。
终极武器: xss worm
在2005年,年仅19岁的
Samy Kamkar发起了对MySpace.com的xss Worm攻击。Samy, Kamkar的蠕虫在短短几小时内就感染了100万用户-它在每个用户的自我简介后边加了一句话: “but most of all, Samy is my hero.” (Samy是我的偶像),这是Web安全史上第一个重量级的XSS Worm,具有里程碑意义。
百度空间蠕虫
XsS Worm是xSs的一种终极利用方式,它的破坏力和影响力是巨大的。但是发起xssWorm攻击也有一定的条件。
一般来说,用户之间发生交互行为的页面,如果存在存储型xss,则比较容易发起xss• Worm攻击。
比如,发送站内信、用户留言等页面,都是xss Worm的高发区,需要重点关注。而相对的,如果一个页面只能由用户个人查看,
比如“用户个人资料设置”页面,因为缺乏用户之间互动的功能,所以即使存在xss,也不能被用于xss worm的传播。
调试JavaScript
- Firebug这是最常用的脚本调试工具,前端工程师与Web Hacking必备,被喻为“居家旅行的瑞士军刀”。
- IE 8Developer Tools在IE8中,为开发者内置了一个JavaScript Debugger, 可以动态调试JavaScript.
- FiddlerFiddler是一个本地代理服务器,需要将浏览器设置为使用本地代理服务器上网才可使用。Fiddler会监控所有的浏览器请求,并有能力在浏览器请求中插入数据。Fiddler支持脚本编程,一个强大的Fiddler脚本将非常有助于安全测试。
- HttpWatchHttpwatch是一个商业软件,它以插件的形式内嵌在浏览器中。
xSS构造技巧
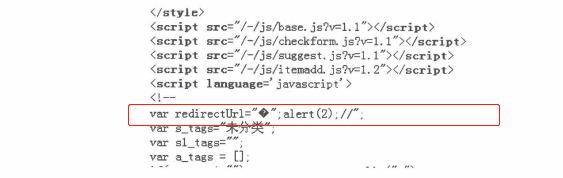
利用字符编码
“百度搜藏”曾经出现过一个这样的xss漏洞。百度在一个<scrip标签中输出了一个变量,其中转义了双引号:var redirectUrla""alert(/xss/):";一般来说,这里是没有xss漏洞的,因为变量处于双引号之内,系统转义了双引号导致变量无法"escape"。但是,百度的返回页面是GBK/GB2312编码的,因此“%c1"这两个字符组合在一起后,会成为一个Unicode字符。在Firefox下会认为这是一个字符,所以构造:
绕过长度限制
产生xss的地方会有变量的长度限制,攻击者可以利用事件(Event)来缩短所需要的字节数:

但利用“事件”能够缩短的字节数是有限的。最好的办法是把xss Payload写到别处,再通过简短的代码加载这段xss Payload.
最常用的一个“藏代码”的地方,就是"location.hash",而且根据HTTP协议, location.hash的内容不会在HTTP包中发送,所以服务器端的Web日志中并不会记录下location.hash里的内容,从而也更好地隐藏了黑客真实的意图。

在某些环境下,可以利用注释符绕过长度限制。比如我们能控制两个文本框,第二个文本框允许写入更多的字节。此时可以利用HTML的“注释符号”,把两个文本框之间的HTML代码全部注释掉,从而“打通”两个<input>标签。

使用<base>标签
<base>标签并不常用,它的作用是定义页面上的所有使用`“相对路径”标签的hosting`地址。  有的技术文档中,`提到<base>标签只能用于<head>标签之内,其实,这是不对的`。`<base>标签可以出现在页面的任何地方,并作用于位于该标签之后的所有标签`。攻击者如果在页面中插入了<base>标签,就可以通过在远程服务器上伪造图片、链接或脚本,`劫持当前页面中的所有使用“相对路径”的标签。`比如  #### window.name对象 对当前窗口的window.name对象赋值,`没有特殊字符的限制`。因为window对象是`浏览器的窗体`,而并非`document对象`,因此很多时候`window对象不受同源策略的限制`。攻击者利用这个对象,可以实现`跨域、跨页面传递数据`。在某些环境下,这种特性将变得非常有用。 **这个没看懂....** 默认情况下,`document.domain`存放的是载入文档的服务器的主机名,可以手动设置这个属性,不过是有限制的,只能设置成当前域名或者上级的域名,并且必须要包含一个.号,也就是说不能直接设置成顶级域名。例如:id.qq.com,可以设置成qq.com,但是不能设置成com。   ### 变废为宝: Mission Impossible 从xSS漏洞利用的角度来看,存储型xss对攻击者的用处比反射型Xss要大。- 存储型XSS在用户访问正常URL时会自动触发;
- 反射型xss会修改一个正常的URL,一般要求攻击者将XSS URL发送给用户点击,无形中提高了攻击的门槛。
Apache Expect Header XSS
"Apache Expect Header XSS"漏洞最早公布于2006年。这个漏洞曾一度被认为是无法利用的,所以厂商不认为这是个漏洞。这个漏洞的影响范围是: Apache Httpd Server版本1.3.342.0.57,2.2.1及以下。漏洞利用过程如下。

后来安全研究者Amit Klein提出了“使用Flash构造请求”的方法,成功地利用了这个漏洞,变废为宝!在Flash中发送HTTP请求时,可以自定义大多数的HTTP头。

第4章跨站点请求伪造(CSRF)
CSRF的全名是Cross Site Request Forgery,翻译成中文就是跨站点请求伪造。它是一种常见的Web攻击,但很多开发者对它很陌生。CSRF也是Web安全中最容易被忽略的一种攻击方式,甚至很多安全工程师都不太理解它的利用条件与危害,因此不予重视。但CSRF在某些时候却能够产生强大的破坏性。

·删除博客文章·的请求,是攻击者所伪造的,所以这种攻击就叫做“跨站点请求伪造”
CSRF进阶
4.2.1 浏览器的Cookie策略
攻击者伪造的请求之所以能够被服务器验证通过,是因为用户的浏览器成功发送了Cookie的缘故。浏览器所持有的Cookie分为两种:
- 一种是"Session Cookie",又称“临时Cookie",
- 另一种是“Third-party Cookie",也称为“本地Cookie".
两者的区别:, Third-party Cookie是服务器在Set-Cookie时指定了Expire时间,只有到了Expire时间后Cookie才会失效,所以这种Cookie会保存在本地;而Session Cookie则没有指定Expire时间,所以浏览器关闭后, Session Cookie就失效了。在浏览网站的过程中,若是一个网站设置了Session Cookie,那么在浏览器进程的生命周期内,即使浏览器新打开了Tab页, Session Cookie也都是有效的。Session Cookie保存在浏览器进程的内存空间中;而Third-party Cookie则保存在本地如果浏览器从一个域的页面中,要加载另一个域的资源,由于安全原因,某些浏览器会阻止Third-party Cookie的发送
IE出于安全考虑,默认禁止了浏览器在、 <iframe, <script.<link>等标签中发送第三方Cookie.
P3P Header是w3C制定的一项关于隐私的标准,全称是The Platform for PrivacyPreferences.如果网站返回给浏览器的HTTP头中包含有P3P头,则在某种程度上来说,将允许浏览器发送第三方Cookie。
在IE下即使是

- 点赞
- 收藏
- 关注作者
评论(0)