ModelBox - AI养猪

AI变身农场主:养猪养牛还养马
什么是AI养猪?AI养猪有什么作用?
本文中小编将使用ModelBox框架开发一个AI养猪的应用,时刻监控每一头猪的状态,并统计猪圈中猪只的数量,最终的效果如下所示:
如果想了解这样一个AI应用是如何开发出来的可以继续跟随小编的脚步,相信看完你也能开发出属于自己的AI应用(@u@)
首先一个完整的AI应用开发应该包含以下几步:1、数据的采集与处理;2、模型的训练与转换;3、AI应用开发和部署
这里小编将使用华为云ModelArts平台进行数据标注和模型训练,ModelArts提供了包括数据标注,训练环境,预置算法等在内的丰富的功能,甚至可以通过订阅算法0代码实现模型的训练工作,当然你也可以在本地训练自己的模型,拥有训练好的模型就可以进行模型的转换以及后面AI应用的开发。
下面小编将逐条介绍如何借助华为云ModelArts平台和ModelBox框架开发一个AI养猪的应用(@o@)
1. 数据采集与处理
我们的实验数据采用猪只检测数据集,使用ModelArts进行标注,包含500张图片以及对应的xml文件,目前已发布到AI Gallery上。

2. 模型训练与转换

目标检测模型采用YOLOX网络结构,YOLOX是YOLO系列的优化版本,引入了解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展,拥有较好的精度表现,同时对工程部署友好。我们在ModelArts的Notebook环境中训练后,再转换成对应平台的模型格式:onnx格式可以运行在Windows设备上,RK系列设备上需要转换为rknn格式。下图为模型训练300个Epoch取得的结果:
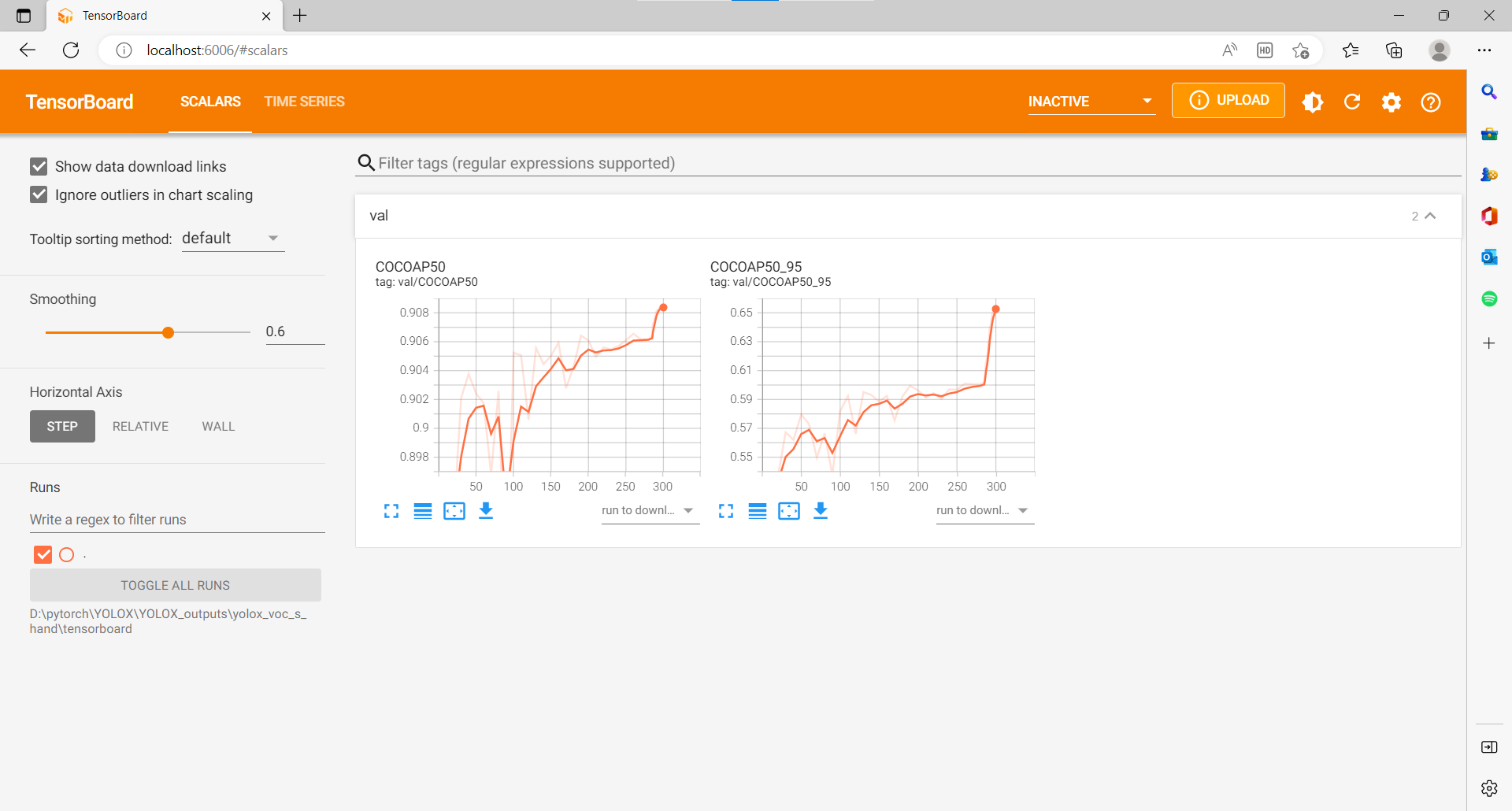
体态识别模型使用MobileNetV2作为卷积基,分别使用迁移学习和从头开始训练网络,实验表明训练网络所有层明显优于迁移学习。模型的训练与转换教程已经开放在AI Gallery中,其中包含训练数据、训练代码、模型转换脚本以及模型推理代码。开发者如果希望尝试自己训练模型,或者对模板中提供的模型效果不满意,可以进入体态识别模型的训练与转换页面,点击右上角的Run in ModelArts按钮,也可以修改其中的代码、更换新的数据集训练出自己的模型。

3. 应用开发
打开VS Code,连接到ModelBox sdk所在目录或者远程开发板,开始进行猪只体态识别应用的开发。下面以RK3568版本为例进行说明,其他版本与之类似。如果对Windows ModelBox SDK使用还不熟悉,可以参考巨佬飞哥的ModelBox 端云协同AI开发套件(Windows)上手指南。
1)下载模板
本案例所需模板资源(代码、模型、测试数据等)均可从multi_pig_pose_yolox_mbv2下载,下载模板到ModelBox核心库的solution目录下:

2)新建项目
在ModelBox sdk目录下使用create.py创建multi_pig_pose工程,末尾-s参数,表示将使用后面参数值代表的模板创建工程,而不是创建空的工程。

3)查看流程图
ModelBox提供了可视化图编排工具:Editor,可以使用python ./create.py -t editor开启图编排服务:
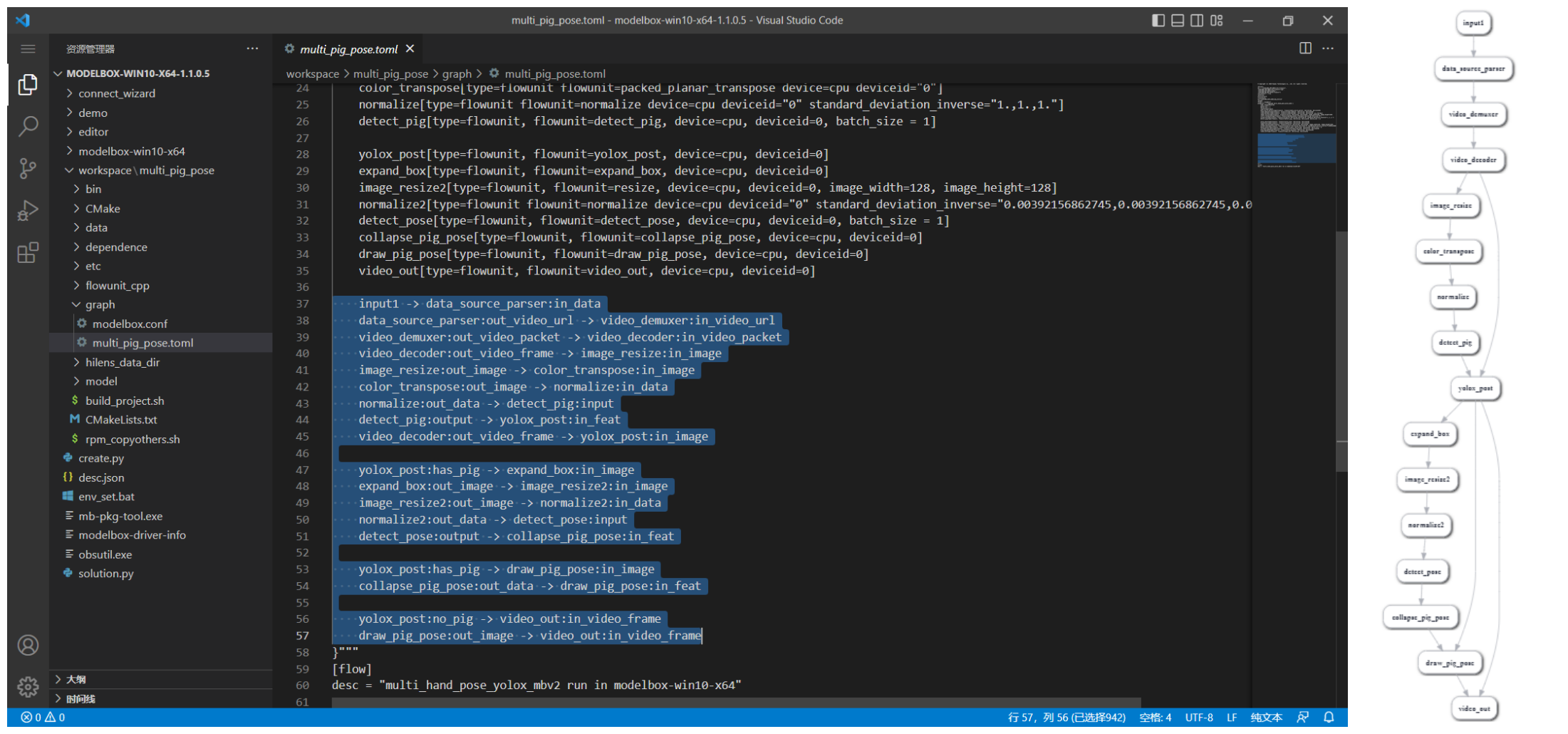
图中,可以看到条件功能单元yolox_post的两个输出分别对接到不同的功能单元,在未检测到猪只时,no_pig分支直接对接到video_out进行视频编码;检测到猪只时,has_pig对接到之后的展开/收拢功能单元做全部猪的体态识别。而展开功能单元expand_box与收拢功能单元collapse_pig_pose之间其他功能单元的使用方式,与正常流程并无不同。
multi_pig_pose需要根据检测结果选择不同的分支进行后续操作:如果没有检测到猪,直接输出原始图像;如果检测到猪,需要对图中检测到的每只猪都识别体态。使用展开功能单元expand_box,将图中的所有检测框展开为多个输出,传递到后面的功能单元分别做体态识别;最后又增加了收拢功能单元collapse_pig_pose,对同一张图的多只猪的体态数据进行合并输出,使得后面的画图功能单元能收集到同一张图片的完整数据。
另外,可以看到预处理功能单元resize、normalize等分别使用了两次(两次的属性不同),每种功能单元在图中也相应的定义了两个实例,使用不同的节点名称进行区分。
4)查看输入输出配置
查看任务配置文件bin/mock_task.toml,可以看到其中的任务输入和任务输出配置为如下内容:

即使用本地视频文件data/pig.mp4作为输入,解码、预处理、猪只检测、后处理、猪只体态识别后,输出画面显示到名为modelbox_show的本地屏幕窗口中。
5)用启动脚本执行应用
然后执行bin/main.bat运行应用:将会自动弹出实时的猪只体态识别的画面!

6)性能评估
在技能流程图中开启性能统计配置项:
[profile]
profile=true
trace=true
之后双击bin/main.bat或在powershell中运行技能:
./bin/main.bat
运行完成后生成的视频与性能统计文件都在hilens_data_dir文件夹下:

我们可以在Chrome浏览器chrome://tracing/中加载性能统计文件查看:

逐项查看后发现耗时最久的是体态识别功能单元,平均耗时10.69ms,因为ModelBox是静态图并行推理,fps取决于耗时最久的功能单元,理论计算fps = 1000 / 10.69 \approx 94fps=1000/10.69≈94,ModelBox真的很快,nice!
4. 小结
在本案例中我们使用ModelBox的展开/合并功能单元进行猪只体态识别应用的开发,有一类常见的视频AI应用是检测+分类,或者检测+识别,需要对检测到的所有对象分别处理,如人脸识别、车牌识别等,此时可以使用ModelBox中的展开/合并功能单元,它能保证大部分模块的处理逻辑与正常数据流相同,又能对展开的子数据流进行高效的并发处理,提高运行速度。最后打包部署,就完成了一个AI应用的开发,从模型的训练到转换再到开发到部署的全部流程。有关ModelBox的课程可以报名ModelBox入门实战营和小编一起学习进步!

- 点赞
- 收藏
- 关注作者
评论(0)