【论文解读】Faster R-CNN 实时目标检测

前言
Faster R-CNN 的亮点是使用RPN来提取候选框;RPN全称是Region Proposal Network,也可理解为区域生成网络,或区域候选网络;它是用来提取候选框的。RPN特点是耗时少。
Faster R-CNN是“RCNN系列算法”的杰出产物,也是two-stage中经典的物体检测算法。two-stage的过程是:
- 第一阶段先找出图片中待检测物体的anchor矩形框。(对背景、待检测物体进行二分类)
- 第二阶段对anchor框内待检测物体进行分类。
简单来说:先产生一些待检测框,再对检测框进行分类。关键点是如何找到“待检测框”,这些待检测框中包含目标物体,虽然暂时不知道它的类别。
论文地址:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network
开源代码:https://github.com/endernewton/tf-faster-rcnn
一、网络框架
Faster RCNN主要分为4个主要内容:
- CNN提取特征,生成feature maps;
- RPN网络提取候选框;
- ROI pooling确定具有物体区域的feature maps;
- 指定区域进行分类。
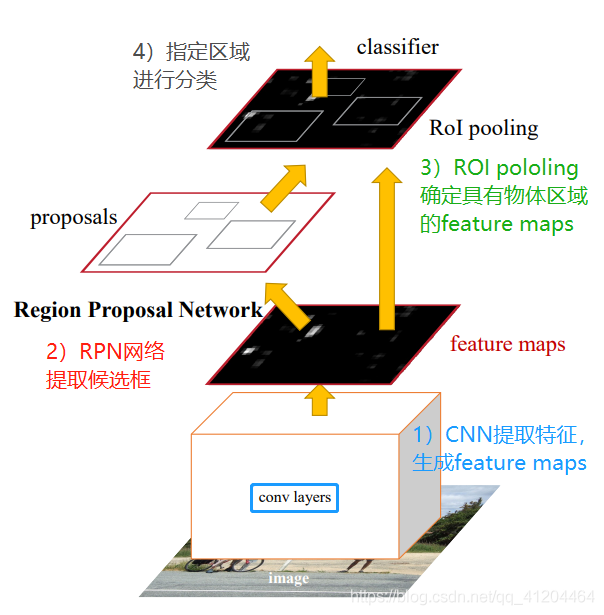
ps:上图的RoI poloing单词写错了,正确是RoI pooling
Faster RCNN的4个主要内容:
- CNN提取特征,生成特征图feature maps。共享基础卷积层,用于提取整张图片的特征。例如VGG16,去除其中的全连接层,只留下卷积层,输出下采样后的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- RPN网络提取候选框。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
- ROI pooling确定具有物体区域的feature maps。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- 指定区域进行分类。对候选检测框进行分类,并且再次微调候选框坐标。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。(在RPN中,网络会根据先前人为设置的anchor框进行坐标调整,所以这里是第二次调整)
二、思路流程
引用《一文读懂Faster RCNN》中的模型结构图:
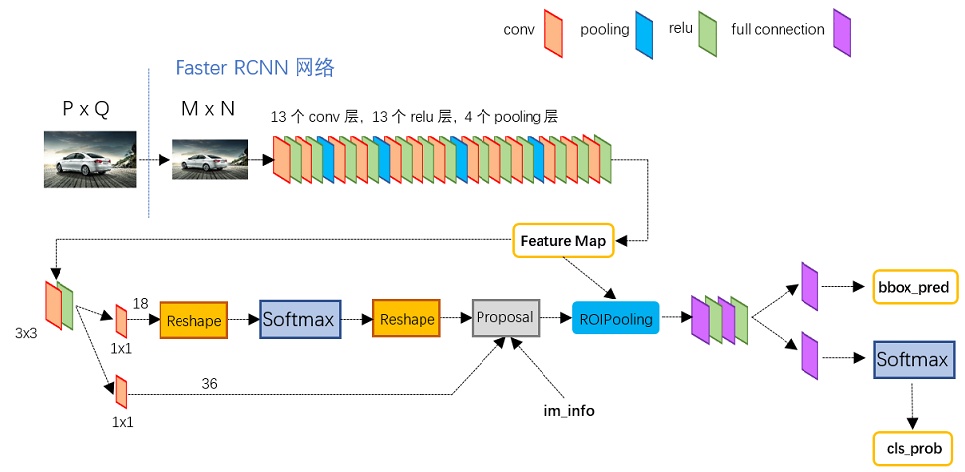
![]()
输入是任意大小PxQ的图像;流程步骤如下:
- 首先缩放至固定大小MxN,然后将MxN图像送入网络;
- Conv layers基于VGG-16模型提取特征,其中包含了13个conv层+13个relu层+4个pooling层;
- RPN网络首先经过3x3卷积,再分别生成positive anchors(包含物体的边界框),和对应bounding box regression偏移量,然后计算出proposals(最有可能包含物体的区域);
- Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
三、CNN提取特征
Faster R-CNN的主干网络可以基于VGG16模型,去除其中的全连接层,只留下卷积层,提取整张图片的特征。
在论文中可能经常会将主干网络称为backbone network。主干网络的作用就是用来提取图片特征的,这个不是一成不变的,可以替换,比如使用残差网络ResNet。
VGG-16网络中的16代表的含义是含有参数的有16个层,分别是13个卷积层+3个全连接层。下面看看VGG-16的网络结构:
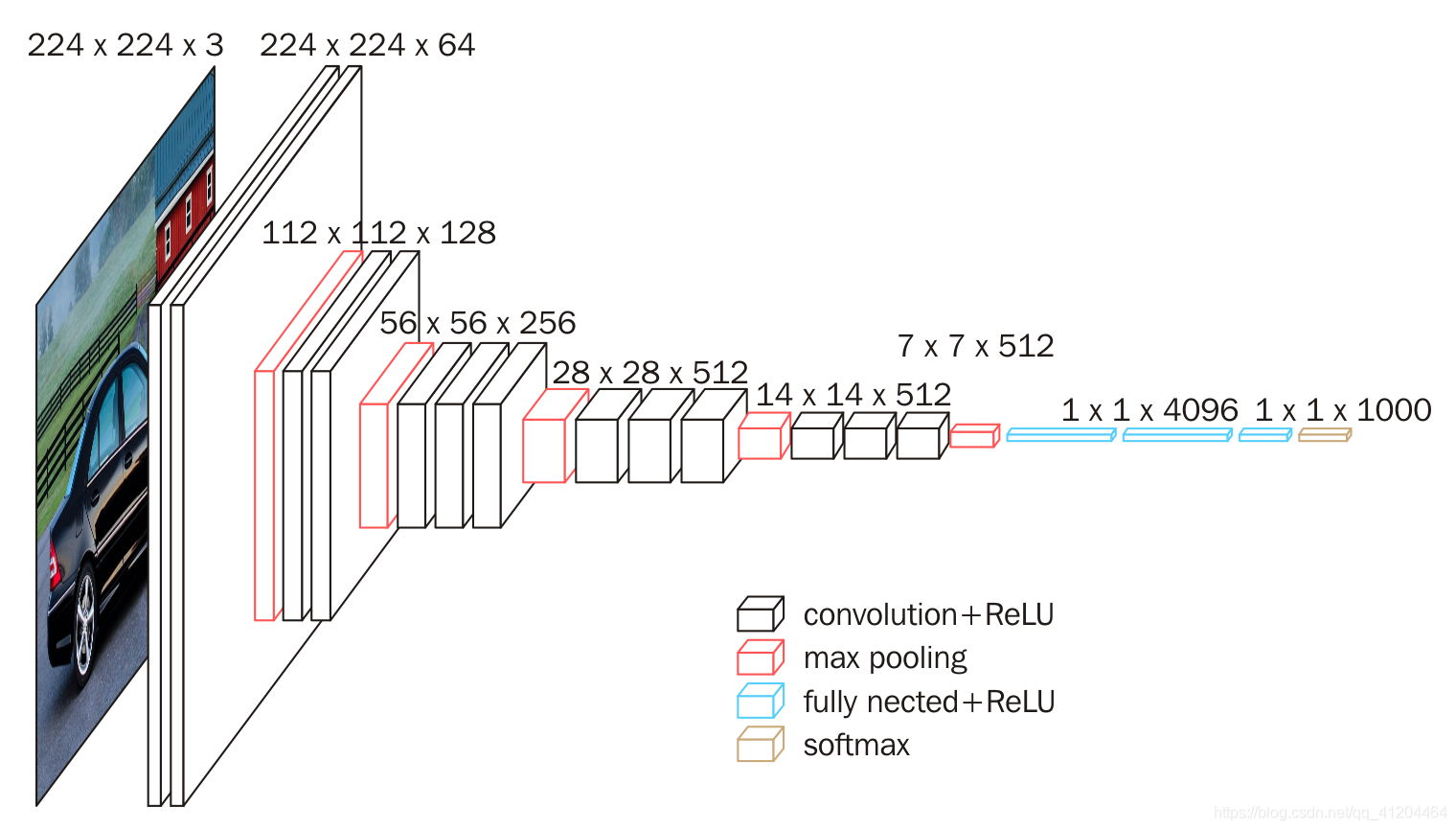
其中,13层的卷积层就是在不断地提取特征,池化层就是使图片的尺寸不断在变小。
四、RPN网络提取候选框
RPN全称是Region Proposal Network,也可理解为区域生成网络,或区域候选网络;它是用来提取候选框的。
4.1、RPN思路流程
RPN网络的任务是找到proposals。输入:feature map。输出:proposal。
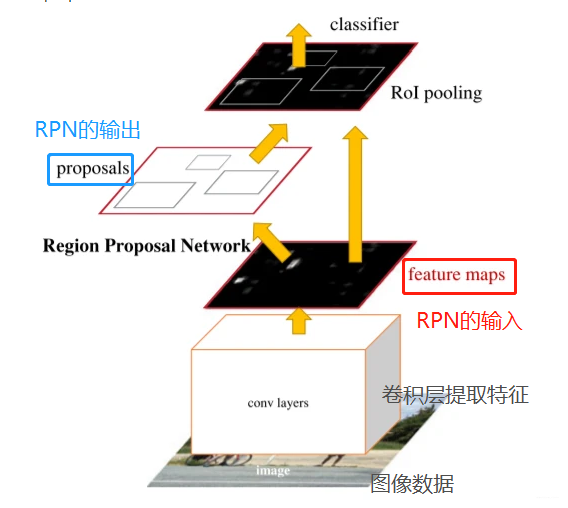
RPN总体流程:
- 生成anchors(anchor boxes)。
- 判断每个 anchor box 为 foreground(包含物体) 或者 background(背景) ,二分类;softmax分类器提取positvie anchors 。
- 边界框回归(bounding box regression) 对 anchor box 进行微调,使得 positive anchor 和真实框(Ground Truth Box)更加接近。
- Proposal Layer生成proposals。
4.2、feature maps与锚框 anchor boxes
feature maps 的每一个点都配9个锚框,作为初始的检测框。重要的事说三遍:
锚框作为初始的检测框!、 锚框作为初始的检测框!、 锚框作为初始的检测框!
虽然这样得到的检测框很不准确,但后面可通过 bounding box regression 来修正检测框的位置。
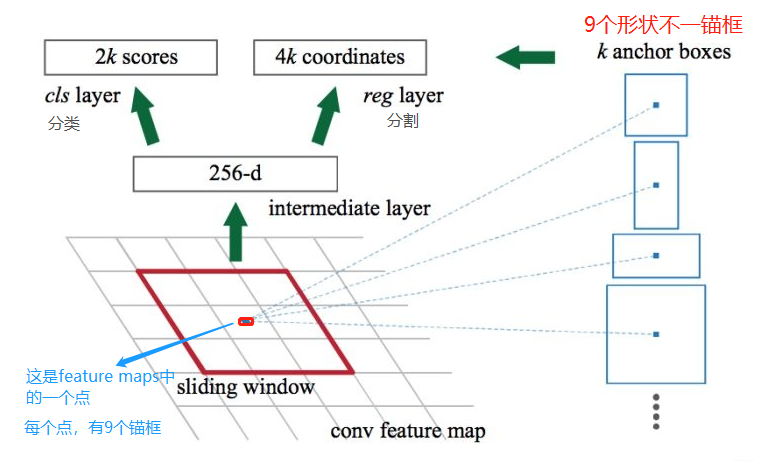
下面介绍那9个anchor boxes 锚框,先看看它的形状:
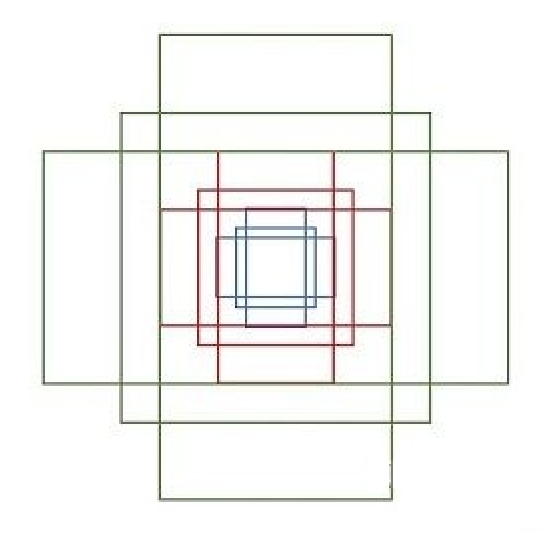
这里一共有9个框框,绿色3个,红色3个,蓝色3个。有3种形状,长宽比分别是1:1, 1:2, 2:1
4.3、判断anchor boxes是否包含物体
在feature map上,设置了密密麻麻的候选anchor boxes 锚框。为什么会有这么多?因为 feature maps 的每一个点都配9个锚框,如果一共有1900个点,那一共有1900*9=17100个锚框了。
设 feature maps 的尺寸为 W*H,那么总共有 W*H*9个锚框。(W:feature maps的宽;H:feature maps 的高。)
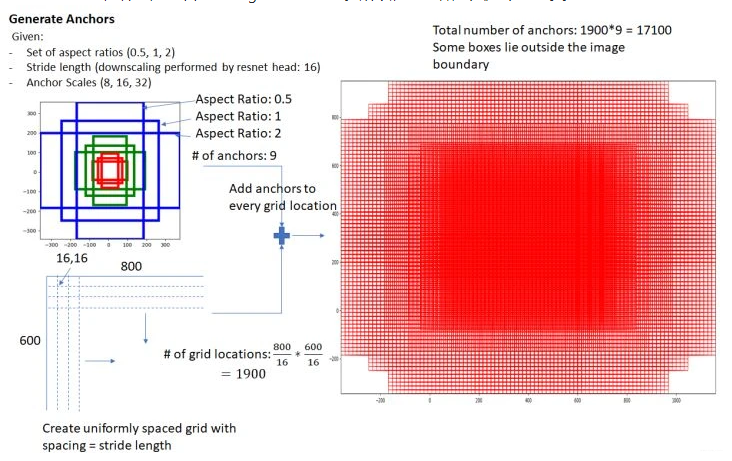
然后用cnn去判断哪些anchor box是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,RPN做的只是个二分类。
关于cnn的模型结构,可以参考下图:
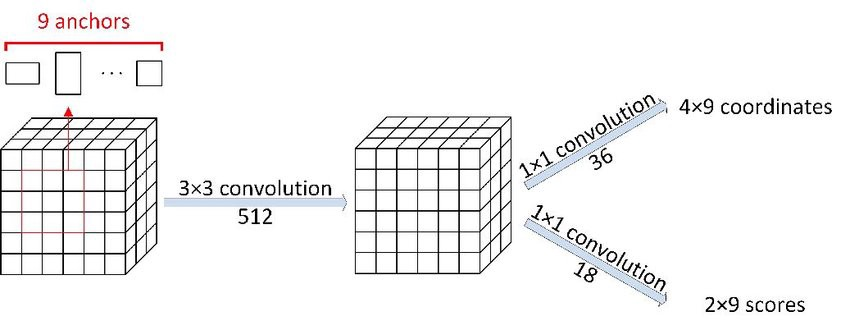
4.4、修正边界框
已知anchor box 包含物体称为positive anchors,那怎么调整,才能使得 anchor box 与 ground truth 更接近?
图中红框为positive anchors,绿框为真实框(Ground Truth Box,简称GT)

positive anchors 和GT的梯度可以有dx, dy, dw, dh四个变换表示,bounding box regression通过线性回归学习到这个四个梯度,使positive anchors 不断逼近GT,从而获得更精确的proposal。
bounding box regression 思路,简单一点的,可以先做平移,再做缩放,最终包含物体anchor box和真实框很接近。
4.5、Proposal(最有可能包含物体的区域)
通过上面的判断anchor boxes是否包含物体,对有物体的anchor boxes通过回归进行修正它的尺子,最终包含物体anchor box和真实框很接近。RPN会输出一些框框,和这些框框包含物体的概率。
总结一下,Proposal 的输入有三个:
- softmax 分类矩阵
- Bounding Box Regression 坐标矩阵
- im_info 保存了缩放的信息
输出为:
- rpn_rois: RPN 产生的 ROIs (Region of Interests,感兴趣的区域)
- rpn_roi_probs: 表示 ROI 包含物体的概率
RPN 只挑选出了可能包含物体的区域(rpn_rois)以及其包含物体的概率(rpn_roi_probs)。在后续处理中,设定一个阈值 threshold,如果某个ROI包含物体的概率的概率大于阈值,再判断其类别;否则直接忽略。
整个RPN的作用就是:
- 用神经网络回归检测框,并且对检测框进行二分类(positive、negative);
- 输出过滤后的positive检测框(RoI)。
RPN输出的proposals, 一个表示所有ROI的N×5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标,坐标信息是对应原图中的绝对坐标。
五、ROI pooling
ROI就是region of interest,指的是感兴趣区域;如果输入是原图,roi就是目标;如果输入是feature maps,roi就是特征图像中目标的特征了。pooling就是池化。
Roi Pooling层收集输入的feature maps 和 proposals(最有可能包含物体的区域),综合这些信息提取proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位。
Rol pooling层有2个输入:
- 原始的feature maps;(cnn卷积出来后的用于共享的那个特征图)
- RPN输出的proposal boxes(proposals、大小各不相同)。
RPN在特征图中会产生尺寸不一致的Proposal区域,而在Faster RCNN中,之后的分类网络输入尺寸固定为7*7,所以对于任意大小的输入,都用7*7的网格覆盖原区域。
如下图所示,能看到红色框、绿色框虽然它们的尺寸不是一样的,但是它们都是7*7的;
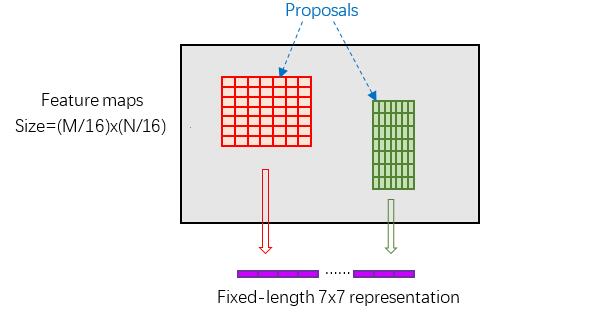
在7*7中每个格子上,取当前格子覆盖区域内的最大值(max pooling);这里对应紫色的部分。
六、指定区域进行分类
此部分输入是:从RoI Pooling获取到7x7=49大小的proposal feature maps(包含物体的特征图)
引用《一文读懂Faster RCNN》中的分类结构图:
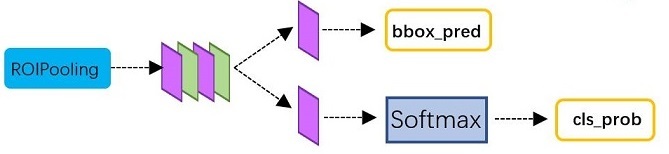
![]() 处理过程:
处理过程:
- 通过全连接层与softmax计算每个proposal具体属于那个类别,输出cls_prob概率向量。
- 同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
七、Faster RCNN损失函数
损失函数
RPN网络与分类网络,输出都是“坐标回归数值”与“分类数值”,所以两个网络的Loss函数都可以用如下式子表达:
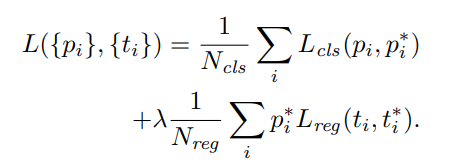
其中, 是分类损失函数,在RNP网络中使用二分类损失函数,在分类网络中使用多分类损失函数。
是分类损失函数,在RNP网络中使用二分类损失函数,在分类网络中使用多分类损失函数。
是一个用来平衡分类与回归loss比例的因子。前面的控制了:只有正例框才会产生检测框回归loss。 (正例框:包含了物体的框)
正例框有两种情况:(1)IoU数值大于0.7;这个可以找到很多的正例框。(2)IoU最高的anchor box;是用来防止一些IoU很小的罕见的检测框;比如IoU都小于0.6时,这时选择个IoU最高的框。
是回归损失函数,原文中作者使用robust loss(smooth L1),表达式如下:
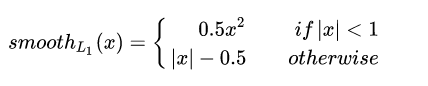
八、模型效果
模型数据:
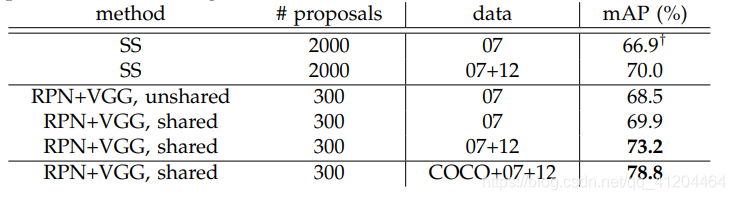
![]()
模型效果1如下:

模型效果2如下:

九、开源代码
开源代码:https://github.com/endernewton/tf-faster-rcnn
用于目标检测的Faster RCNN。该版本代码支持VGG16、Resnet V1和Mobilenet V1模型。
代码的运行环境:
系统:ubuntu 16.04(x64)
语言:Python3.5
深度框架:TensorFlow1.0(GPU 版本)
其他依赖库:cv2、cython、easydict=1.6、numpy等。
本文参考:https://zhuanlan.zhihu.com/p/31426458
https://zhuanlan.zhihu.com/p/82185598
https://blog.csdn.net/LLyj_/article/details/87521925

![]()
论文地址:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network
开源代码:https://github.com/endernewton/tf-faster-rcnn
本文只提供参考学习,谢谢。

- 点赞
- 收藏
- 关注作者
评论(0)