【论文解读】LaneNet 基于实体分割的端到端车道线检测

前言
这是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型。
LanNet 是一种多任务模型,它将 实例分割 任务拆解成“语义分割”和“对像素进行向量表示”,然后将两个分支的结果进行聚类,得到实例分割的结果。
H-Net 是个小网络,负责预测变换矩阵 H,使用转换矩阵 H 对同属一条车道线的所有像素点进行重新建模。即:学习给定输入图像的透视变换参数,该透视变换能够对坡度道路上的车道线进行良好地拟合。
整体的网络结构如下:
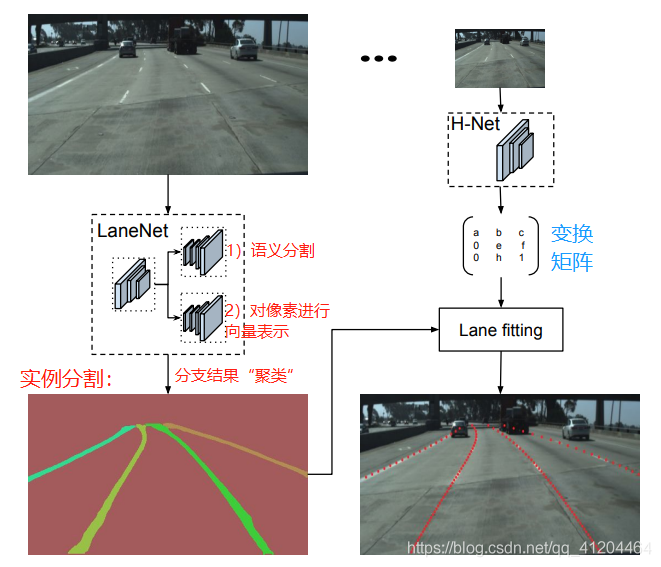
![]()
论文地址:Towards End-to-End Lane Detection: an Instance Segmentation Approach
开源数据集TuSimple:https://github.com/TuSimple/tusimple-benchmark/issues/3
开源代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
一、LanNet
LanNet 对输入图像进行实例分割,其中网络结构分为两个方向,一个是语义分割,另一个是对像素进行向量表示,最后将两个分支的结果进行聚类,得到实例分割的结果。LaneNet输出实例分割的结果,为每个车道线像素分配一个车道线ID。
1.1 网络结构
先看看网络结构:
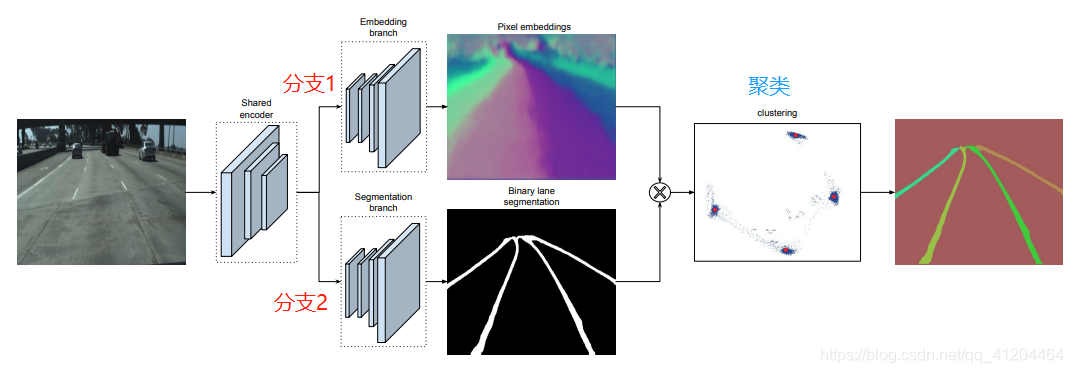
![]() 分支1 语义分割,Segmentation,对像素进行二分类,判断像素属于车道线还是背景;
分支1 语义分割,Segmentation,对像素进行二分类,判断像素属于车道线还是背景;
分支2 对像素进行向量,Embedding,对像素进行嵌入式表示,把图像特征表示为嵌入空间中,特征之间的关系映射在嵌入空间。
聚类,基于Mean-Shift 算法实现的,把将两个分支的结果进行聚类,得到实例分割的结果。
LaneNet是基于ENet的encoder-decoder模型,如下图所示,ENet由5个stage组成,其中stage2和stage3基本相同,stage1,2,3属于encoder,stage4,5属于decoder。
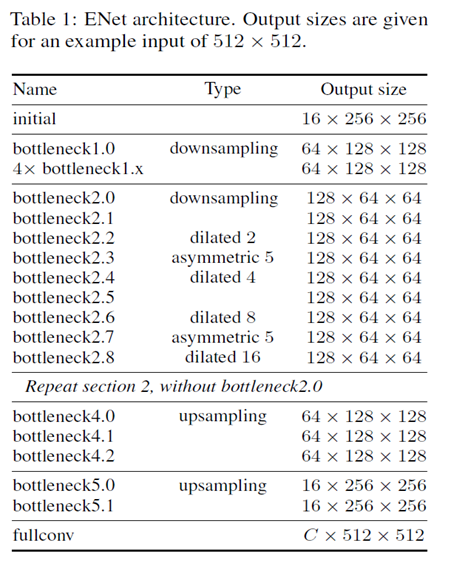
1.2 语义分割
这部分是对像素进行二分类,判断像素属于车道线还是背景;并且高度不平衡,因此参考了ENet,损失函数使用的是标准的交叉熵损失函数。
设计语义分割模型时,为了处理遮挡问题,论文对被车辆遮挡的车道线和虚线进行了还原(估计);
Loss 使用 softmax_cross_entropy,为了解决样本分布不均衡的问题,使用了 bounded inverse class weight 对 loss 进行加权:
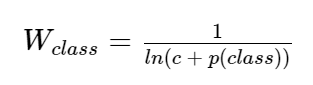
其中,p 为对应类别在总体样本中出现的概率,c 是超参数。
Loss的设计参考了:论文ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
1.3 像素映射到嵌入空间
当分割识别得到车道后,为了知道哪些像素归这条车道,哪些归那条车道,需要训练一个车道instance embedding分支网络。它能输出一个车道线像素点距离,归属同一车道的像素点距离近,反之远,基于这个策略,可聚类得到各条车道线。
为了区分车道线上的像素属于哪条车道, 为每个像素初始化一个 embedding 向量,并且在设计 loss 时,使属同一条车道线的表示向量距离尽可能小,属不同车道线的表示向量距离尽可能大。
这部分的 loss 函数是由三部分组成:方差损失、距离损失、回归损失:
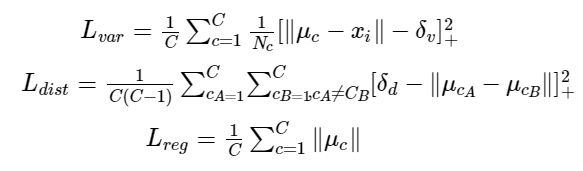
其中,C 是车道线数量,Nc是属同一条车道线的像素点数量,μc是车道线的均值向量,xi是像素向量(pixel embedding)。
该 loss 函数源自于论文 《Semantic Instance Segmentation with a Discriminative loss function》
方差loss(Lvar) :当像素向量(pixel embedding)xi与对应车道线均值向量μc的距离大于δv时,模型会进行更新,使得xi 靠近μc ;
距离loss(Ldist) :当不同车道线均值向量 μca和μcb之间的距离小于δd 时,模型会进行更新,使得μca与μcb远离彼此;
方差loss(Lvar)使得像素向量向车道线的均值向量 μc 靠近,距离loss(Ldist)则会推动聚类中心远离彼此。
1.4 聚类
embedding(像素映射到嵌入空间)已经为聚类提供好的特征向量了,利用这些特征向量我们可以利用任意聚类算法来完成实例分割的目标。
聚类是基于Mean-Shift 算法实现的,把将两个分支的结果进行聚类,得到实例分割的结果。
首先使用 mean shift 聚类,使得簇中心沿着密度上升的方向移动,防止将离群点选入相同的簇中;之后对像素向量进行划分,直到将所有的车道线像素分配给对应的车道。
二、H-Net
LaneNet的输出是每条车道线的像素集合,还需要根据这些像素点回归出一条车道线。传统的做法是将图片投影到俯视图(鸟瞰图)中,然后使用 2 阶或者 3 阶多项式进行拟合。在这种方法中,变换矩阵 H 只被计算一次,所有的图片使用的是相同的变换矩阵,这会导致地平面(山地,丘陵)变化下的误差。
为了解决这个问题,论文训练了一个可以预测变换矩阵 H 的神经网络 H-Net,网络的输入是图片,输出是变换矩阵 H:
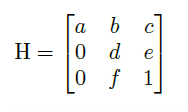
通过置 0 对转置矩阵进行约束,即水平线在变换下保持水平。(即坐标 y 的变换不受坐标 x 的影响)
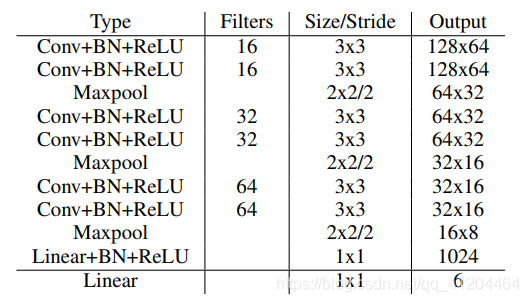
由上式可以看出,转置矩阵 H 只有6个参数,因此H-Net的输出是一个 6 维的向量。H-Net 由 6 层普通卷积网络和一层全连接网络构成,其网络结构如图所示:
![]()
三、模型效果
车道线检测效果,与其他模型对比
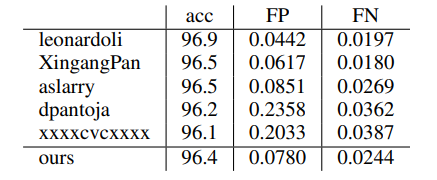
![]() 模型的精度高达96.4%,这个效果挺不错了。
模型的精度高达96.4%,这个效果挺不错了。
模型速度:
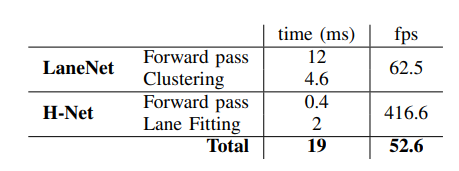
![]()
2018年:在 NVIDIA 1080 TI 上测得的 512X256 图像的速度。总的来说,车道检测可以以 52 FPS 的速度运行。检测速度比较快了,实时性较高。
2020年:添加实时分割模型 BiseNetV2 作为 Lanenet 主干,新模型在单幅图像推理过程中可以达到 78 fps。可以在此处找到基于 BiseNetV2 训练的新 Lanenet 模型。
模型效果:

![]()
四、开源代码
开源代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
该开源代码是使用LaneNet深度神经网络模型,进行实时车道检测(非官方版)
该模型由编码器-解码器阶段、二进制语义分割阶段和使用判别损失函数进行实时车道检测任务的实例语义分割组成。
代码的运行环境:(以下是亲测的)
系统:ubuntu 16.04(x64)
语言:Python3.6
深度框架:TensorFlow1.15.0(GPU 版本)
其他依赖库:cv2、matplotlib、scikit_learn、numpy等。
实践过程:
1)创建conda环境
2)进入刚才创建的环境
3)根据 requirements.txt 要求去安装相关的依赖库(这里我也阿里云加速安装了)
tensoflow重复了:tensorflow_gpu==1.15.0、tensorflow==1.15.0,根据使用情况删除一个,我是准确使用GPU加速的,于是删掉tensorflow==1.15.0。
4)安装英伟达的cudatoolkit 10.0版本
conda install cudatoolkit=10.05)安装英伟达深度学习软件包7.6版本
conda install cudnn=7.6.56)设置lanenet_model 环境变量
7)下载模型
链接:https://pan.baidu.com/s/1-av2fK7BQ05HXjKMzraBSA 提取码:1024
一共4个文件,30M左右。
然后在 lanenet-lane-detection目录下,新建一个子目录,名为model_weights,存在这个4个模型文件,待会用到。
8)测试模型
![]()
语义分割和像素嵌入效果:
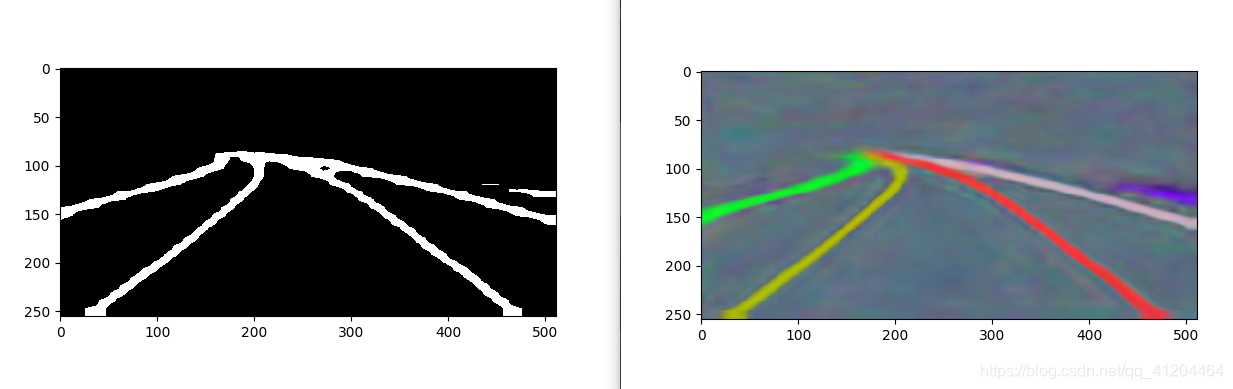
![]()
实体分割效果:
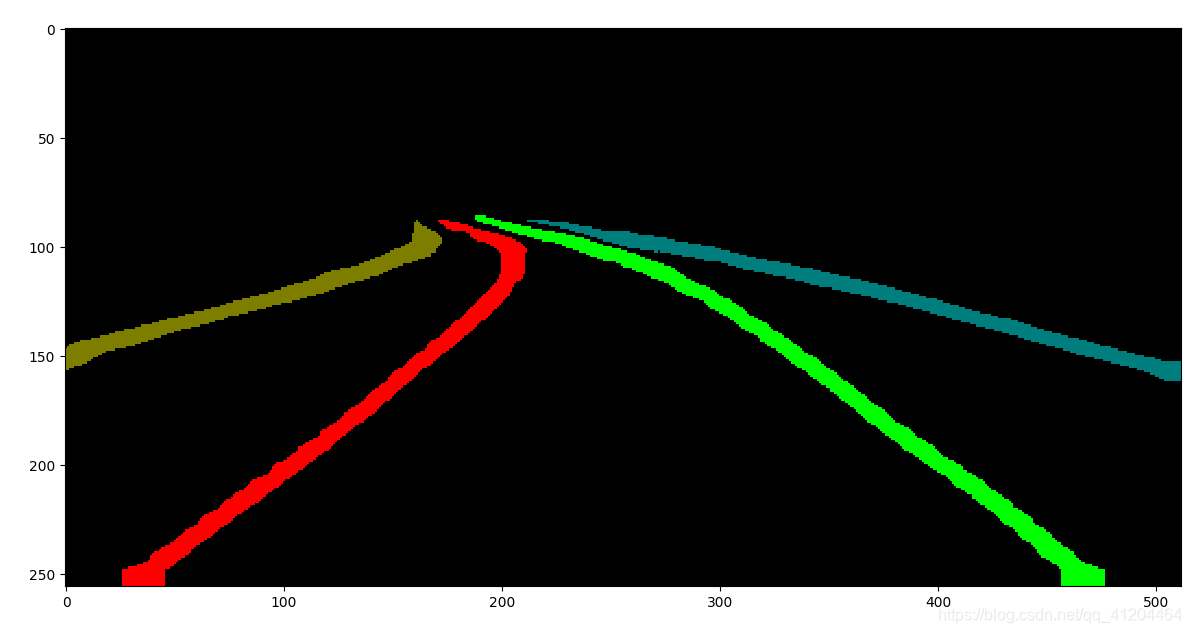
![]()
模型效果:
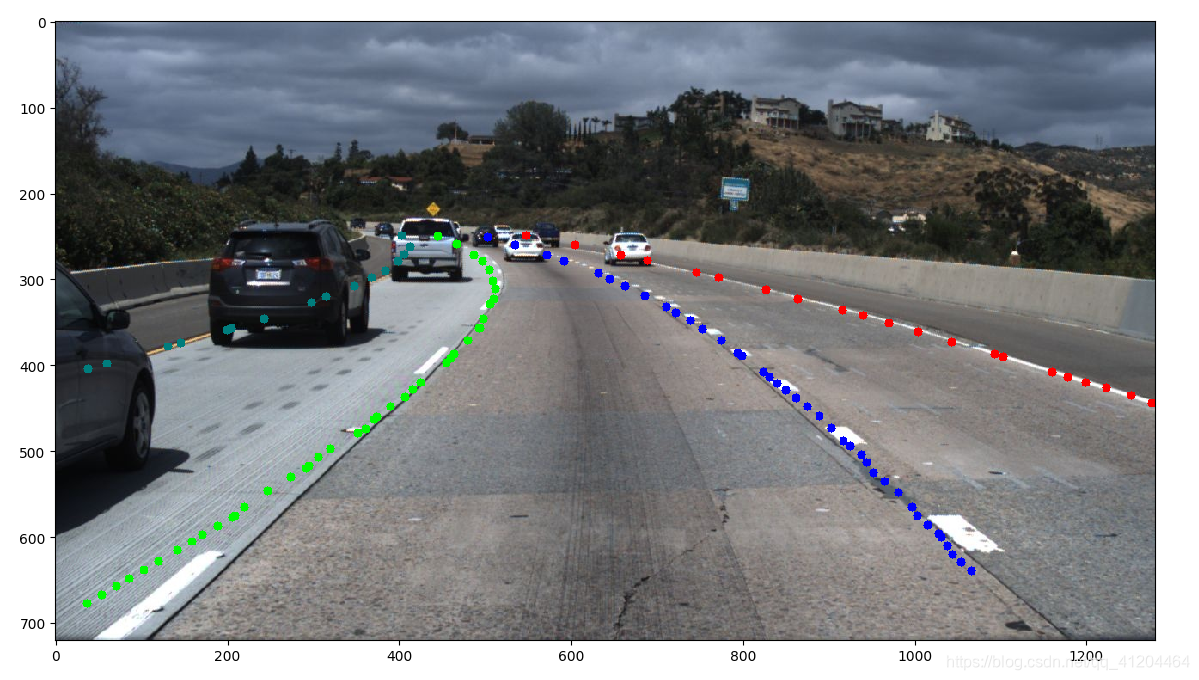
参考:https://www.jianshu.com/p/c6d38d648509
https://www.cnblogs.com/xuanyuyt/p/11523192.html
LaneNet: Towards End-to-End Lane Detection: an Instance Segmentation Approach
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Discriminative Loss: Semantic Instance Segmentation with a Discriminative loss function

![]()
论文地址:Towards End-to-End Lane Detection: an Instance Segmentation Approach
开源代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
本文只提供参考学习,谢谢。

- 点赞
- 收藏
- 关注作者
评论(0)