【点云处理】基于深度学习模型的不同处理方式

前言
点云数据由无序的数据点构成的一个集合;点与点之间是具有空间关系的;点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。
点云数据处理方式,通常有:将点云数据投影到二维平面(多视图法)、将点云数据划分到有空间依赖关系的voxel(体素法)、直接在点云数据上应用深度学习模型(点云法)。
一、点云数据特点
点云数据是在欧式空间下的点的一个子集,它具有以下三个特征:无序、点与点之间的空间关系、空间转换不变性。
1.1 无序
点云数据是一个集合,对数据的顺序是不敏感的。这使得处理点云数据的模型需要对数据的不同排列保持不变性。
为什么说点云数据是无序的??先看下图:
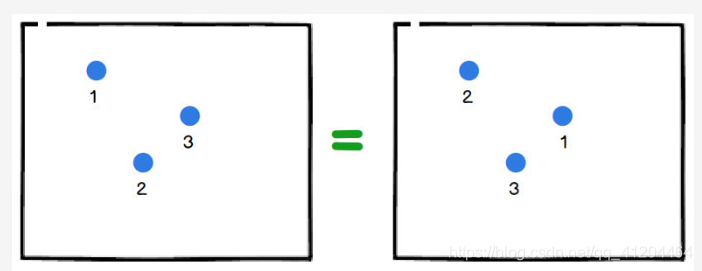
![]() 左边有三个点云,右边也有三个点云,虽然每个点的索引值不一样,但是它们的分布、形状等都是一样的;在分类或分割模型,对左、右两幅图应该输出同一个结果(看起像三角形)。
左边有三个点云,右边也有三个点云,虽然每个点的索引值不一样,但是它们的分布、形状等都是一样的;在分类或分割模型,对左、右两幅图应该输出同一个结果(看起像三角形)。
再看看左边和右边的点云索引值不是对应的。
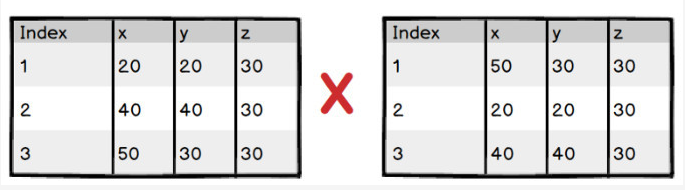
![]() 所以说:点云数据由无序的数据点构成一个集合来表示;分类或分割模型,不应该受点云数据集的顺序影响。
所以说:点云数据由无序的数据点构成一个集合来表示;分类或分割模型,不应该受点云数据集的顺序影响。
1.2 点与点之间的空间关系
一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。

![]()
1.3 不变性
点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。 如下图所示,同一个物体,在空间经过旋转或平移,还是原来那个物体。

![]()
二、点云数据处理方式
2.1 将点云数据投影到二维平面(多视图法)
此种方式不直接处理三维的点云数据,而是先将点云投影到某些特定视角再处理,如前视视角和俯视角,再使用2D-CNN进行分类或分割。
同时,也可以融合使用来自相机的图像信息。通过将这些不同视角的数据相结合,来实现点云数据的认知任务。比较典型的算法有MV3D和AVOD。
MV3D-Net 融合了视觉图像和激光雷达点云信息;输入数据有三种,分别是点云俯视图、点云前视图和RGB图像。通过特征提取、特征整合和特征融合,最终得到类别标签、3D边界框。这样的设计既能减少计算量,又保留了主要的特征信息。
AVOD-Net算是MV3D-Net的加强版,它也融合了视觉图像和激光雷达点云信息。但它去掉了激光点云的前视图输入、去掉了俯视图中的强度信息;输入数据有二种,分别是点云俯视图和RGB图像。AVOD-Net使用FPN来提取特征,同时添加边界框的几何约束,整体模型效果有提升。
详细可看看这两篇博客:
【论文解读】MV3D-Net 用于自动驾驶的多视图3D目标检测网络
【论文解读】AVOD-Net 用于自动驾驶的聚合视图3D对象检测网络
2.2 将点云数据划分到有空间依赖关系的voxel(体素法)
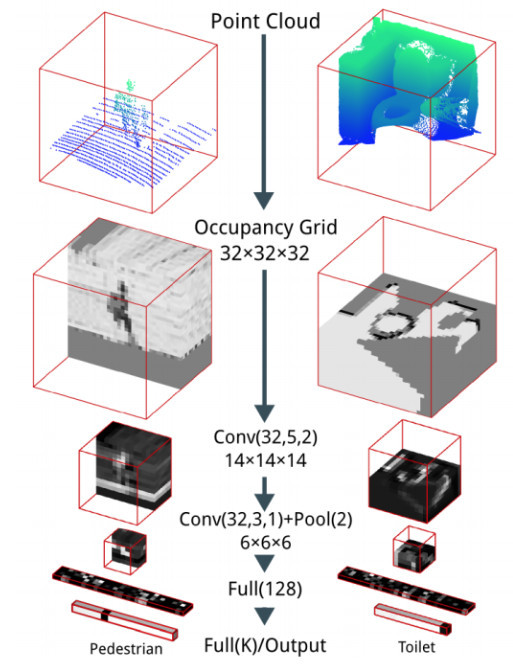
基于3D-CNN的体素模型:先将点云映射到体素空间上,再通过3D-CNN进行分类或者分割。
体素化网格是将 3D 对象拟合到网格中的最直观的方法,为了使其看起来像是像素图像,我们在这里将其称为体素voxel。在这种情况下,3D 图像由(x,y,z)坐标描述,它看起来就会像乐高一样。
![]()
此种方式通过分割三维空间,引入空间依赖关系到点云数据中,再使用3D卷积等方式来进行处理。经典的网络有:VoxNet。
缺点1:计算量受限制,目前最好的设备也大致只能处理32×32×32的体素;另外由于体素网格的立方体性质,点云表面很多特征都没有办法被表述出来,因此模型效果差。
缺点2:由于是三维的数据量,时间和空间复杂度都非常高,目前已经不是主流的方法了。
2.3 直接在点云数据上应用深度学习模型(点云法)
直接使用点云数据,比较经典的有PointNet、PointNet++。
F-PointNet 也是直接处理点云数据的方案,但它在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。
F-PointNet的思路是:
- 基于图像2D目标检测。
- 基于图像生成锥体区域。
- 在锥体内,使用 PointNet/PointNet++ 网络进行点云实例分割。
详细可看看这篇博客:【论文解读】F-PointNet 使用RGB图像和Depth点云深度 数据的3D目标检测
特点:直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割。
参考:https://zhuanlan.zhihu.com/p/44809266
https://club.leiphone.com/page/TextTranslation/737
【论文解读】MV3D-Net 用于自动驾驶的多视图3D目标检测网络

- 点赞
- 收藏
- 关注作者
评论(0)