基于昇腾CANN的卡通图像生成可在线体验啦!十分钟带你了解CANN应用开发全流程

2021年7月8日,第四届世界人工智能大会在上海召开。华为轮值董事长胡厚崑在开幕式发表演讲,其中提到:华为推出了异构计算架构CANN(Compute Architecture for Neural Networks),CANN作为昇腾AI处理器的发动机,支持业界多种主流的AI框架,包括MindSpore、TensorFlow、Pytorch、Caffe等,并提供1200多个基础算子。同时,CANN具有开放易用的ACL(Ascend Computing Language)编程接口,并提供了网络模型的图级和算子级的编译优化、自动调优等功能。CANN对上支持多种AI框架,对下服务AI处理器与编程,是提升昇腾AI处理器计算效率的关键平台。
如何理解CANN,如何使用CANN,特别是如何基于CANN开放易用的ACL编程接口实现神经网络的快速部署呢?
相信我们大部分开发者对于训练一个模型并不陌生,但对于将该模型部署到边缘侧,做成一个应用落地,去产生价值(或者叫帮你赚钱?),可能就不是特别清楚了。但,一旦谈到可以帮你去帮你赚钱,我相信你一定会感兴趣的,对吗?
什么?赚钱!说到这个事儿,我就知道你不困了哈!
我们发现在昇腾社区上已经提供了不少可在线体验的案例,这些案例不但可以在线体验效果,还可以进行在线实验,同时开放了源代码,可以通过开源社区提供的资源进行学习并给基于这些案例进行二次开发,真真正正的体验、学习、开发三步走啊!
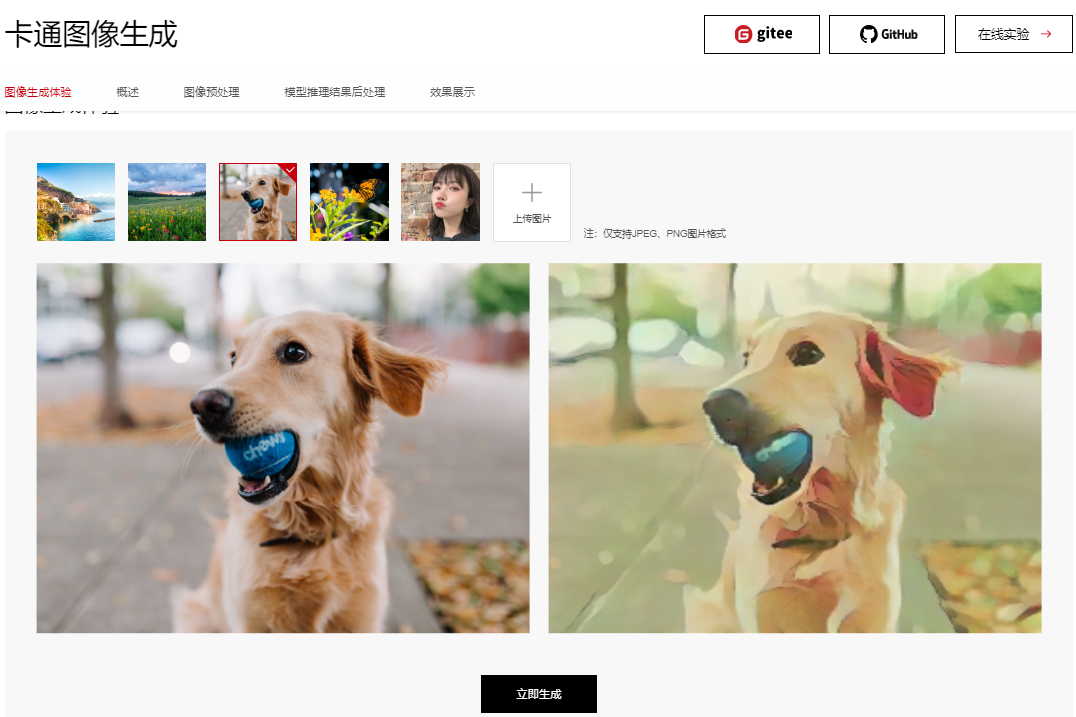
那么我们选择一些有意思的案例带大家学习下基于CANN的昇腾AI应用开发过程,今天要给大家介绍的就是这个能够吸引到你的卡通图像生成应用,无论是漂亮的小姐姐还是可爱的小萌宠都能帮你秒级生成,如下图,选择预置图片或者是上传自己的私照,点击“立即生成”即可体验。
首先介绍下如何找到该应用:
进昇腾社区https://www.hiascend.com/
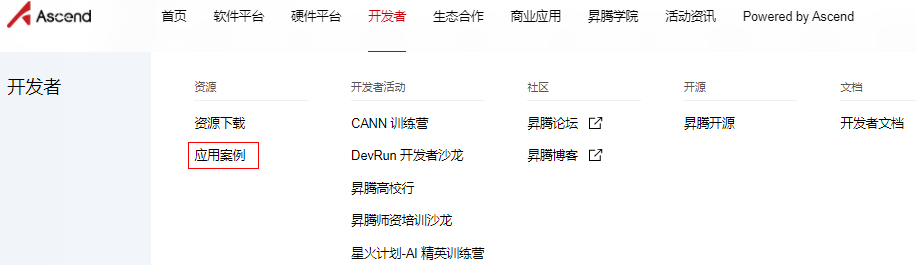
开发者->应用案例,Ok,你已经可以看到那个狗狗了,案例标题是“卡通图像生成”,点击进去你就看到了。

体验就不说了,左边选择需要处理的图片,也可以上传自己的图片,然后点击生成就可以了,图片会上传到华为云昇腾AI计算资源上,推理后再回传到前端展示,相隔千里却仍能提供秒级体验,这里要给个大赞!
那么接下来言归正传,带你了解基于CANN的应用开发流程。完整开发流程如下:
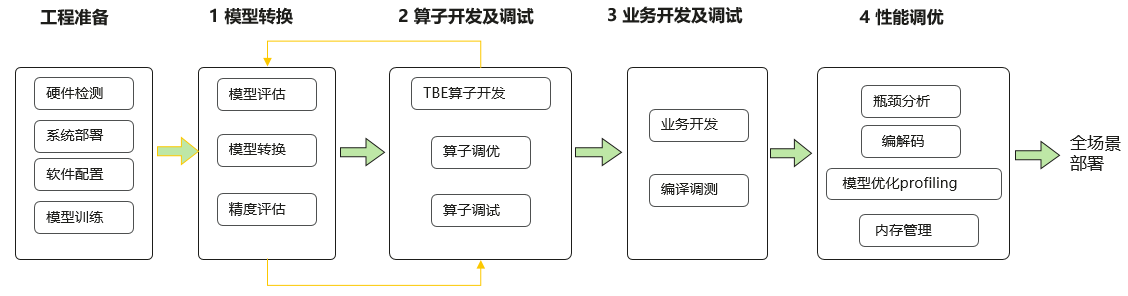
0) 工程准备
硬件:服务器及推理卡准备就绪, 安装操作系统,配置网络。
训练后的模型:Caffe、MindSpore、TensorFlow模型;
1)模型转换
离线模型:Ascend310算子列表, ATC转换工具。
2) 算子开发及调试
自定义算子开发:TBE DSL,TBE TIK等算子开发工具。
3) 业务开发及调试
ACL接口:资源初始化,数据传输,数据预处理,模型推理,数据后处理等。
4)性能调优
性能优化:瓶颈分析,内存优化,模型优化等。
看起来还挺复杂的,对吧??但是我们呢,是来解决主要矛盾的(先完成应用开发),其他的优化过程(精度、性能等)留着以后慢慢消化,来日方长,不是么?
废话不多说了,假定模型我们已经有了,也符合我们的需求,模型呢也是昇腾AI处理器已经支持的模型(无需做算子开发),我们现在要做的就是理解模型,分析其前处理过程(给模型准备数据),后处理过程(结果展示),进行模型转换得到离线模型,然后就是代码开发了(其实就是调用CANN ACL的各种API完成模型加载、推理的过程而已), 这里选用python,CANN的pyACL用起来。
总结一下,在本例中我们只需要搞定如下过程:
- 理解模型 2. 模型转换 3. 基于CANN ACL接口进行代码开发
1、理解模型
Yang Chen、Yong-Jin LIU等人提出的算法 CartoonGAN: Generative Adversarial Networks for Photo Cartoonization基于GAN网络,迭代训练生成器和判别器,由判别器提供的对抗性损失约束,最终将自然图片转换为具有卡通风格的图片,效果惊艳。
下图为卡通图像生成的整体框架:
以Generative Adversarial Networks(GAN)为基础,其架构包括一个生成器(Generator)和一个判别器(Discriminator),通过迭代训练两个网络,由判别器提供的对抗性损失约束,最终使得网络能够将自然图片转换为具有卡通风格的图片结果,并且保持原图片的内容信息。
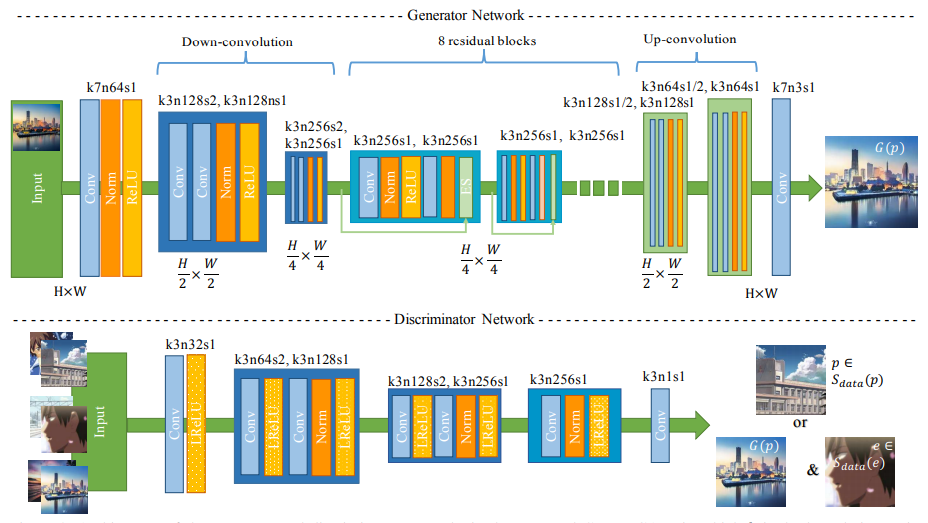
图1 卡通图像生成整体架构
生成器结构
生成器采用自编码器,为全卷积结构,包括编码器如图3,解码器如图4。
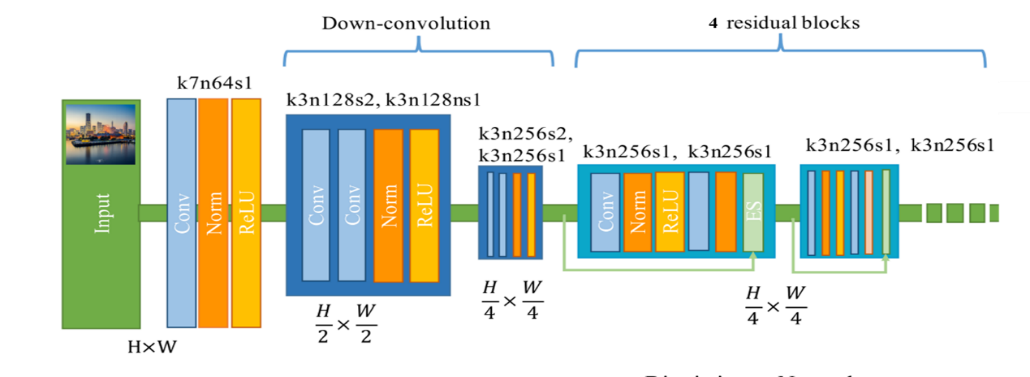
图3 编码器结构
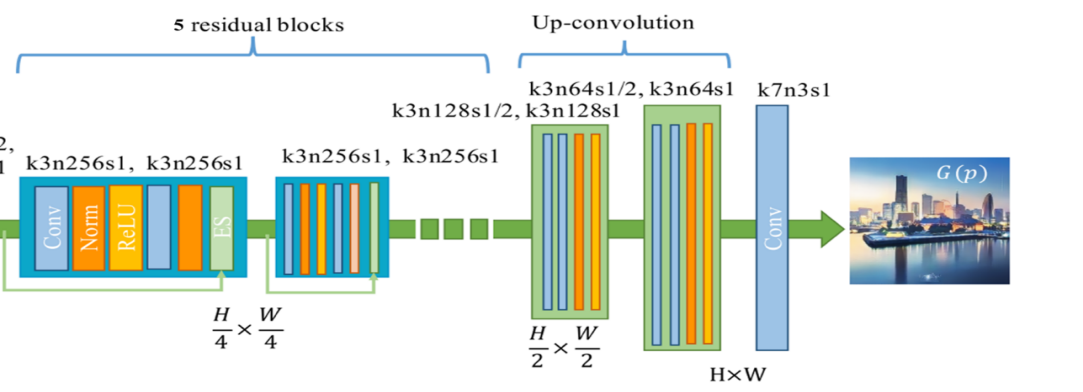
图4 解码器结构
编码器输入为真实图片,其架构由7×7的卷积核,步长为1的卷积层开始,随后紧跟两个步长为2的降采样块,进行特征提取,对风格图片生成有用的信息将在这个过程中被提取。然后紧接4个残差块(Residual Block),用来重建内容特征。
解码器架构由5个残差块开始,通过两个上采样块(步长为2)来实现对不同风格特征的重建,最后在添加一层使用7×7卷积核、步长为1的卷积层,得到最终输出生成的卡通图片结果。
由于当前我们的目标是将训练好的模型做成一个AI应用,所以这里只需要了解生成器就够了,从上面的结构中可以看出,该模型的输入是图像,输出也是图像,那么预处理和后处理过程呢?
原始模型预处理和后处理
在Github能够找到其测试脚本:https://github.com/taki0112/CartoonGAN-Tensorflow/tree/890decc647fbfd90a5314290b2771c496562ada8
结合前面的理解,并通过对测试脚本的研读,能够理解其图像预处理和后处理的方法

昇腾CANN软件栈提供了两套专门用于数据预处理的工具,其中一套叫做AIPP(AI Preprocessing) ;另一套叫做DVPP(Digital Vision Preprocessing)。
DVPP是CANN软件栈中的数字视觉预处理模块,昇腾310 AI处理器支持抠图缩放、jpeg编解码、视频编解码、png解码等功能。详细请参考昇腾社区文档:
https://support.huaweicloud.com/devg-cannApplicationDev330/atlasapi_07_0131.html
AIPP用于在AI Core上完成图像预处理,包括色域转换(转换图像格式)、图像归一化(减均值/乘系数)和抠图(指定抠图起始点,抠出神经网络需要大小的图片)等,静态AIPP可以在ATC模型转换时通过设置参数完成,比较方便。详细请参考昇腾社区文档:https://support.huaweicloud.com/tg-cannApplicationDev330/atlasatc_16_0015.html
在这里,我们假设你已经了解了DVPP和AIPP,那么基于对原始模型的理解,在图像预处理时DVPP和AIPP如下分工(分工的原则:DVPP+AIPP的处理要等价于原始模型的预处理过程):
DVPP:
1.解码:JPEG图片先解码为YUV420SP,输出宽128,高16对齐,例如:若输入原始图像大小为(500, 375) 经过解码后图像大小变为(512, 384)
2.图像缩放:使用DVPP的VPC接口将图像缩放为模型要求的大小(256,256),要求宽16,高2对齐,将(512,384)图像中的有效数据(500,375)缩放到(256,256)
注:这里也可以考虑等比例缩放,但由于等比例缩放要涉及到用AIPP裁剪,后期再讲。
AIPP:
1.色域转换:YUV->RGB
2.图像标准化,AIPP配置mean_chn=[127.5,127.5,127.5] min_chn=[0.5,0.5,0.5] var_reci_chn=[0.007874,0.007874,0.007874]
2)后处理
根据原始模型图像后处理流程,将图像像素转换到[0,255],然后进行保存。该过程直接使用scipy库实现。
2、模型转换
原始网络模型是TensorFlow框架模型,而昇腾CANN软件栈需要的模型是.om离线模型,因此,需要通过ATC模型转换工具将.pb文件转换为Ascend 310处理器支持的Davinci模型文件。
ATC模型转换指令:
atc --output_type=FP32 --input_shape="train_real_A:1,256,256,3" --input_format=NHWC --output="./cartoonization" --soc_version=Ascend310 --insert_op_conf=./insert_op.cfg --framework=3 --model="./cartoonization.pb" --precision_mode=allow_fp32_to_fp16
重要参数说明:
--model:原始模型文件路径与文件名。
--output:转换后的离线模型的路径以及文件名。
--precision_mode=allow_fp32_to_fp16:设置网络模型的精度模式,优先保持原图精度,如果网络模型中算子支持float32,则保留原始精度float32;如果网络模型中算子不支持float32,则直接降低精度到float16。
--insert_op_conf:插入算子的配置文件路径与文件名,例如AIPP预处理算子。
AIPP配置文件,根据原始模型需处理进行AIPP文件配置,本模型的配置文件见下图:
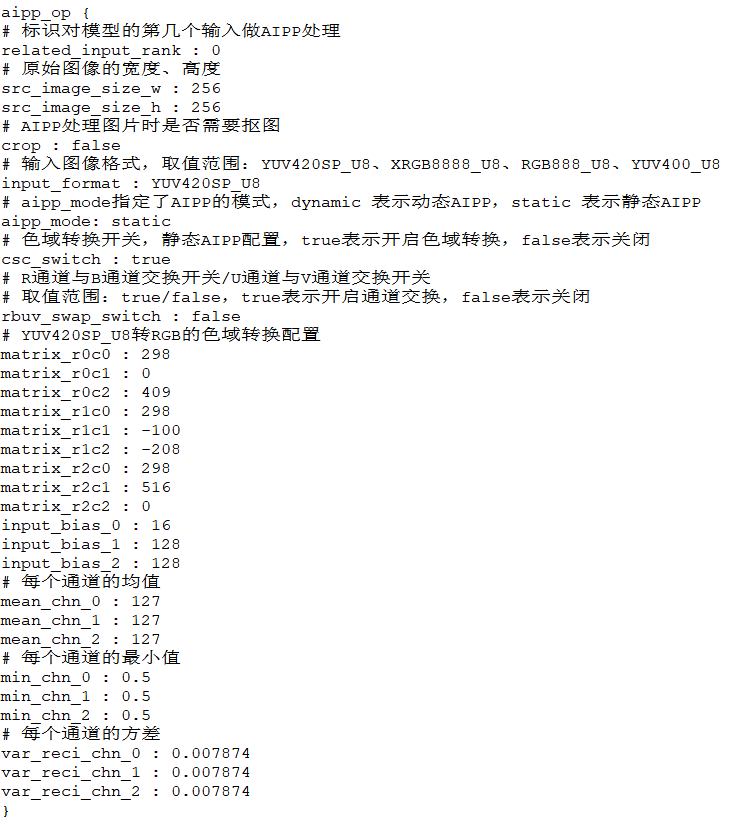
更多参数介绍可阅读:https://support.huaweicloud.com/atctool-cann502alpha5infer/atlasatc_16_0037.html
3、应用开发
应用采用了下图所示的模块化设计,通过各模块之间的协调配合完成一张图片的推理输出。

其中各个模块的主要功能点如下所示:
1.运行资源申请;
2.加载模型文件,申请模型输入输出内存;
3.数据获取,获取要进行推理的原始图像;
4.数据预处理,模型的输入图像进行预处理;
5.模型推理,将预处理后的数据输入到模型进行推理;
6.推理结果解析,将推理结果进行后处理。
源码就不在这里show了,昇腾社区提供了更好的学习路径,可以直接通过在线实验学习开发过程,直接点击右上侧的在线实验,即可免费体验。
体验完毕后,大家还可以移步开源仓库去获取源码,如果有任何问题,鼓励大家去提issue与开发人员直接交流。
https://gitee.com/ascend/samples/tree/master/python/contrib/cartoonGAN_picture
相关链接
模型论文参考链接如下:
原始模型部署链接如下:
https://gitee.com/syz825211943/cartoonization
相关源码可以在开源仓库如下地址中获取:
https://gitee.com/ascend/sample

- 点赞
- 收藏
- 关注作者
评论(0)