你知道Kafka创建Topic这个过程做了哪些事情吗?(附视频) (上)

【kafka源码】kafka-topics.sh之创建Topic源码解析
日常运维 、问题排查 怎么能够少了滴滴开源的
滴滴开源LogiKM一站式Kafka监控与管控平台
配套视频:
https://www.bilibili.com/video/BV1uf4y1V75V?share_source=copy_web
脚本参数
sh bin/kafka-topic -help 查看更具体参数
下面只是列出了跟--create 相关的参数
| 参数 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服务 |
指定连接到的kafka服务; 如果有这个参数,则 --zookeeper可以不需要 |
–bootstrap-server localhost:9092 |
--zookeeper |
弃用, 通过zk的连接方式连接到kafka集群; | –zookeeper localhost:2181 或者localhost:2181/kafka |
--replication-factor |
副本数量,注意不能大于broker数量;如果不提供,则会用集群中默认配置 | –replication-factor 3 |
--partitions |
分区数量 | 当创建或者修改topic的时候,用这个来指定分区数;如果创建的时候没有提供参数,则用集群中默认值; 注意如果是修改的时候,分区比之前小会有问题 |
--replica-assignment |
副本分区分配方式;创建topic的时候可以自己指定副本分配情况; | --replica-assignment BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本 |
--config<String: name=value> |
用来设置topic级别的配置以覆盖默认配置;只在–create 和–bootstrap-server 同时使用时候生效; 可以配置的参数列表请看文末附件 | 例如覆盖两个配置 --config retention.bytes=123455 --config retention.ms=600001 |
--command-config <String: command 文件路径> |
用来配置客户端Admin Client启动配置,只在–bootstrap-server 同时使用时候生效; | 例如:设置请求的超时时间 --command-config config/producer.proterties; 然后在文件中配置 request.timeout.ms=300000 |
--create |
命令方式; 表示当前请求是创建Topic | --create |
创建Topic脚本
zk方式(不推荐)
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
需要注意的是–zookeeper后面接的是kafka的zk配置, 假如你配置的是localhost:2181/kafka 带命名空间的这种,不要漏掉了
kafka版本 >= 2.2 支持下面方式(推荐)
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test
更多TopicCommand相关命令请看
当前分析的kafka源码版本为 kafka-2.5
创建Topic 源码分析
温馨提示: 如果阅读源码略显枯燥,你可以直接看源码总结以及后面部分
首先我们找到源码入口处, 查看一下 kafka-topic.sh脚本的内容
exec $(dirname $0)/kafka-run-class.sh kafka.admin.TopicCommand "$@"
最终是执行了kafka.admin.TopicCommand这个类,找到这个地方之后就可以断点调试源码了,用IDEA启动
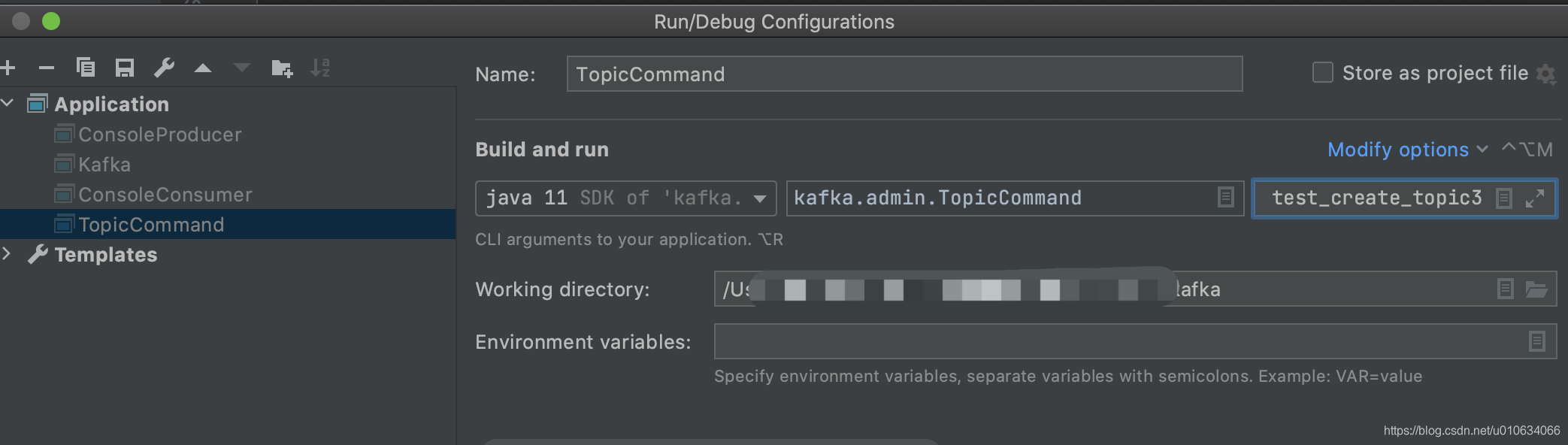
记得配置一下入参
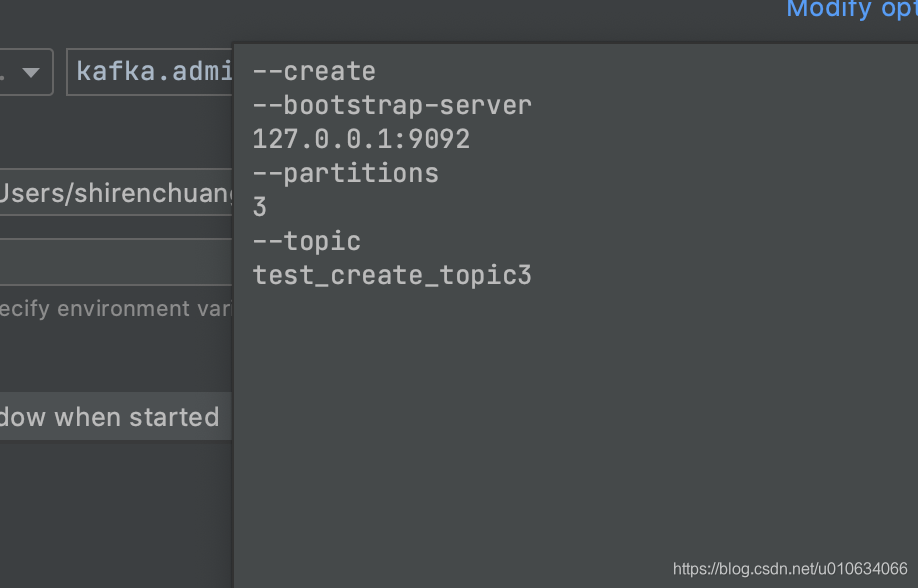
比如: --create --bootstrap-server 127.0.0.1:9092 --partitions 3 --topic test_create_topic3
1. 源码入口
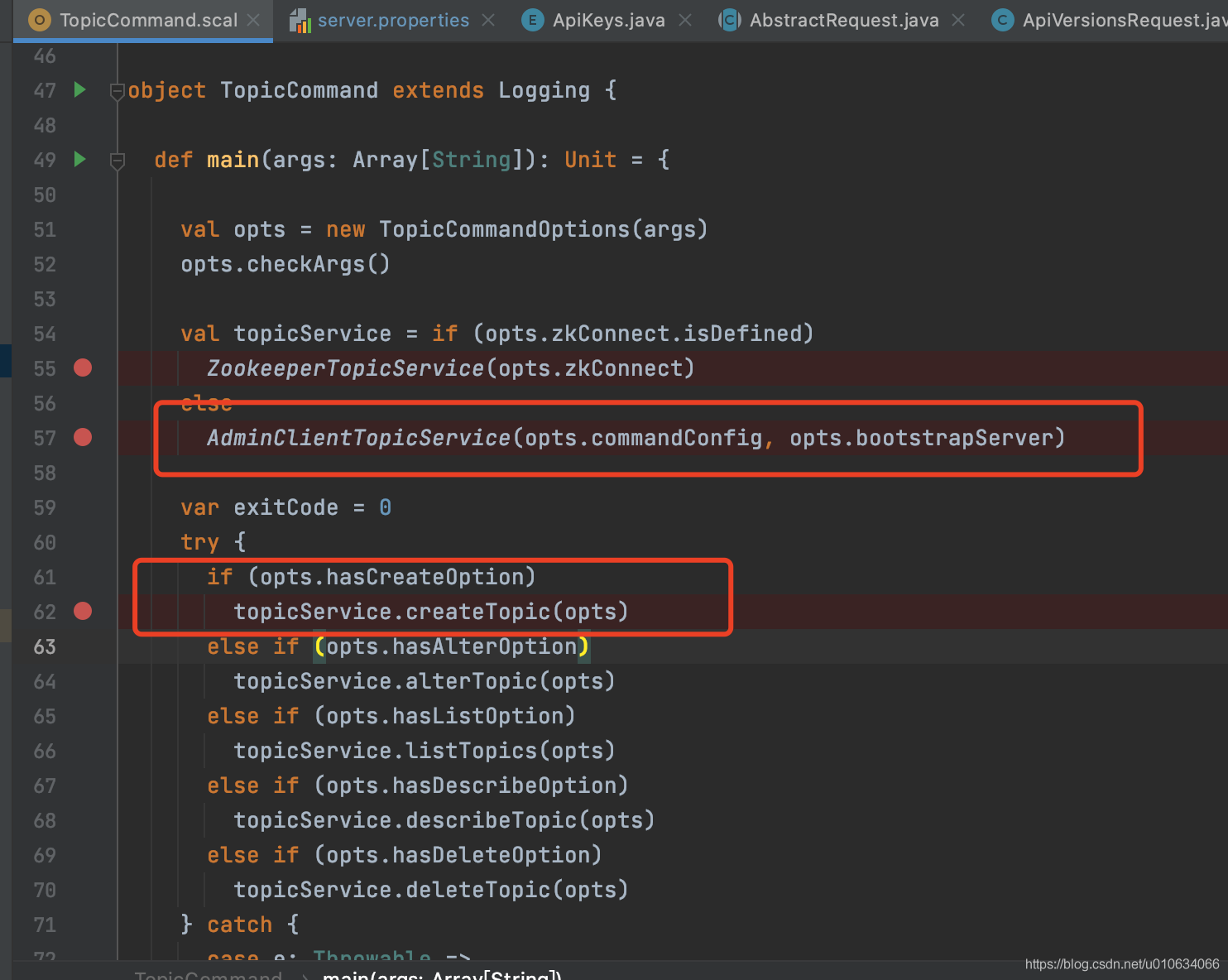
上面的源码主要作用是
- 根据是否有传入参数
--zookeeper来判断创建哪一种 对象topicService
如果传入了--zookeeper则创建 类ZookeeperTopicService的对象
否则创建类AdminClientTopicService的对象(我们主要分析这个对象) - 根据传入的参数类型判断是创建topic还是删除等等其他 判断依据是 是否在参数里传入了
--create
2. 创建AdminClientTopicService 对象
val topicService = new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))
2.1 先创建 Admin
object AdminClientTopicService {
def createAdminClient(commandConfig: Properties, bootstrapServer: Option[String]): Admin = {
bootstrapServer match {
case Some(serverList) => commandConfig.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, serverList)
case None =>
}
Admin.create(commandConfig)
}
def apply(commandConfig: Properties, bootstrapServer: Option[String]): AdminClientTopicService =
new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))
}
- 如果有入参
--command-config,则将这个文件里面的参数都放到mapcommandConfig里面, 并且也加入bootstrap.servers的参数;假如配置文件里面已经有了bootstrap.servers配置,那么会将其覆盖 - 将上面的
commandConfig作为入参调用Admin.create(commandConfig)创建 Admin; 这个时候调用的Client模块的代码了, 从这里我们就可以看出,我们调用kafka-topic.sh脚本实际上是kafka模拟了一个客户端Client来创建Topic的过程;

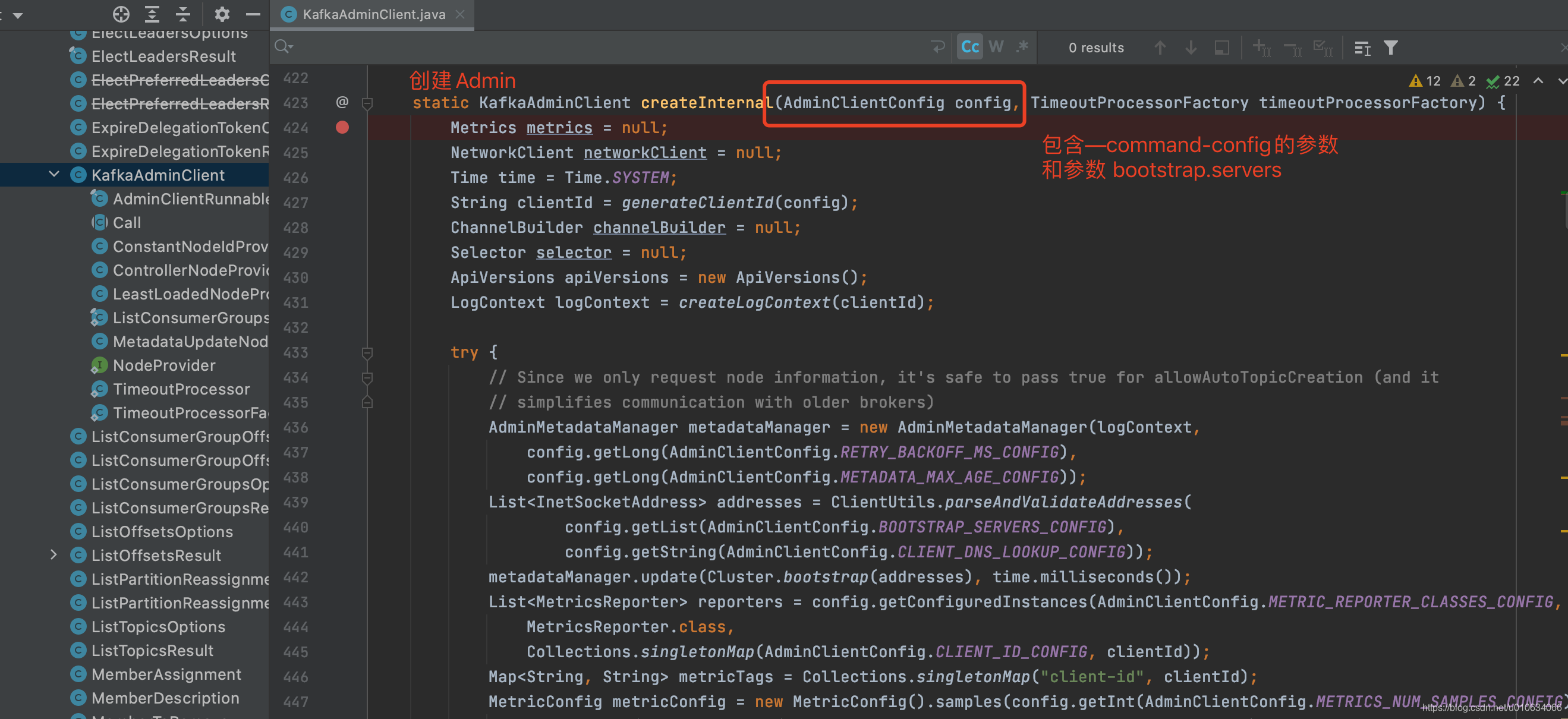
3. AdminClientTopicService.createTopic 创建Topic
topicService.createTopic(opts)
case class AdminClientTopicService private (adminClient: Admin) extends TopicService {
override def createTopic(topic: CommandTopicPartition): Unit = {
//如果配置了副本副本数--replication-factor 一定要大于0
if (topic.replicationFactor.exists(rf => rf > Short.MaxValue || rf < 1))
throw new IllegalArgumentException(s"The replication factor must be between 1 and ${Short.MaxValue} inclusive")
//如果配置了--partitions 分区数 必须大于0
if (topic.partitions.exists(partitions => partitions < 1))
throw new IllegalArgumentException(s"The partitions must be greater than 0")
//查询是否已经存在该Topic
if (!adminClient.listTopics().names().get().contains(topic.name)) {
val newTopic = if (topic.hasReplicaAssignment)
//如果指定了--replica-assignment参数;则按照指定的来分配副本
new NewTopic(topic.name, asJavaReplicaReassignment(topic.replicaAssignment.get))
else {
new NewTopic(
topic.name,
topic.partitions.asJava,
topic.replicationFactor.map(_.toShort).map(Short.box).asJava)
}
// 将配置--config 解析成一个配置map
val configsMap = topic.configsToAdd.stringPropertyNames()
.asScala
.map(name => name -> topic.configsToAdd.getProperty(name))
.toMap.asJava
newTopic.configs(configsMap)
//调用adminClient创建Topic
val createResult = adminClient.createTopics(Collections.singleton(newTopic))
createResult.all().get()
println(s"Created topic ${topic.name}.")
} else {
throw new IllegalArgumentException(s"Topic ${topic.name} already exists")
}
}
- 检查各项入参是否有问题
adminClient.listTopics(),然后比较是否已经存在待创建的Topic;如果存在抛出异常;- 判断是否配置了参数
--replica-assignment; 如果配置了,那么Topic就会按照指定的方式来配置副本情况 - 解析配置
--config配置放到configsMap中;configsMap给到NewTopic对象 - 调用
adminClient.createTopics创建Topic; 它是如何创建Topic的呢?往下分析源码
3.1 KafkaAdminClient.createTopics(NewTopic) 创建Topic
@Override
public CreateTopicsResult createTopics(final Collection<NewTopic> newTopics,
final CreateTopicsOptions options) {
//省略部分源码...
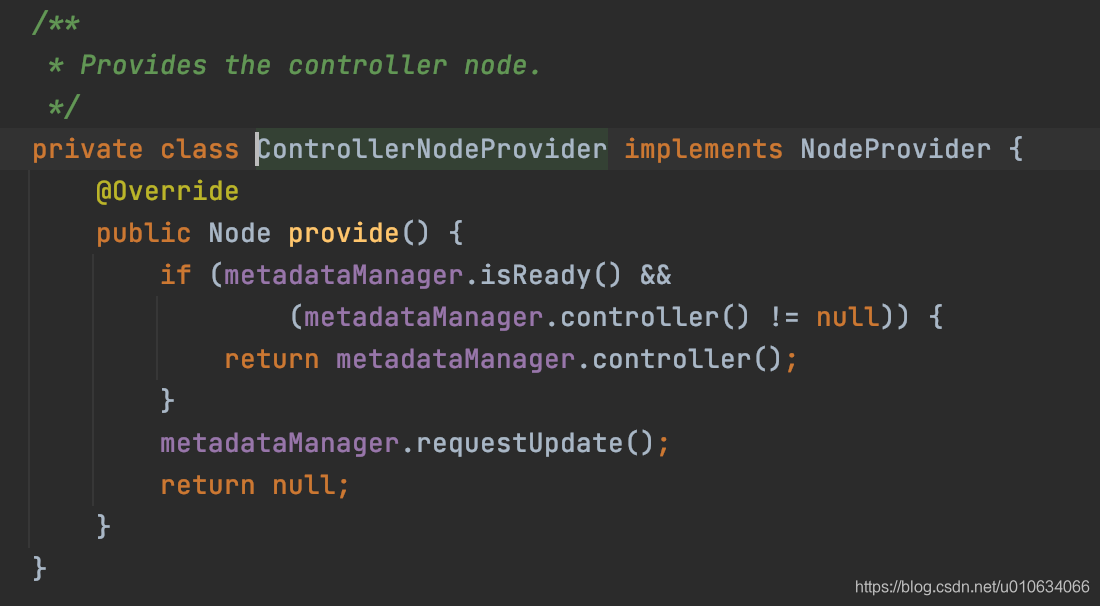
Call call = new Call("createTopics", calcDeadlineMs(now, options.timeoutMs()),
new ControllerNodeProvider()) {
@Override
public CreateTopicsRequest.Builder createRequest(int timeoutMs) {
return new CreateTopicsRequest.Builder(
new CreateTopicsRequestData().
setTopics(topics).
setTimeoutMs(timeoutMs).
setValidateOnly(options.shouldValidateOnly()));
}
@Override
public void handleResponse(AbstractResponse abstractResponse) {
//省略
}
@Override
void handleFailure(Throwable throwable) {
completeAllExceptionally(topicFutures.values(), throwable);
}
};
}
这个代码里面主要看下Call里面的接口; 先不管Kafka如何跟服务端进行通信的细节; 我们主要关注创建Topic的逻辑;
createRequest会构造一个请求参数CreateTopicsRequest例如下图
- 选择ControllerNodeProvider这个节点发起网络请求
可以清楚的看到, 创建Topic这个操作是需要Controller来执行的;


4. 发起网络请求
5. Controller角色的服务端接受请求处理逻辑
首先找到服务端处理客户端请求的 源码入口 ⇒ KafkaRequestHandler.run()
主要看里面的 apis.handle(request) 方法; 可以看到客户端的请求都在request.bodyAndSize()里面
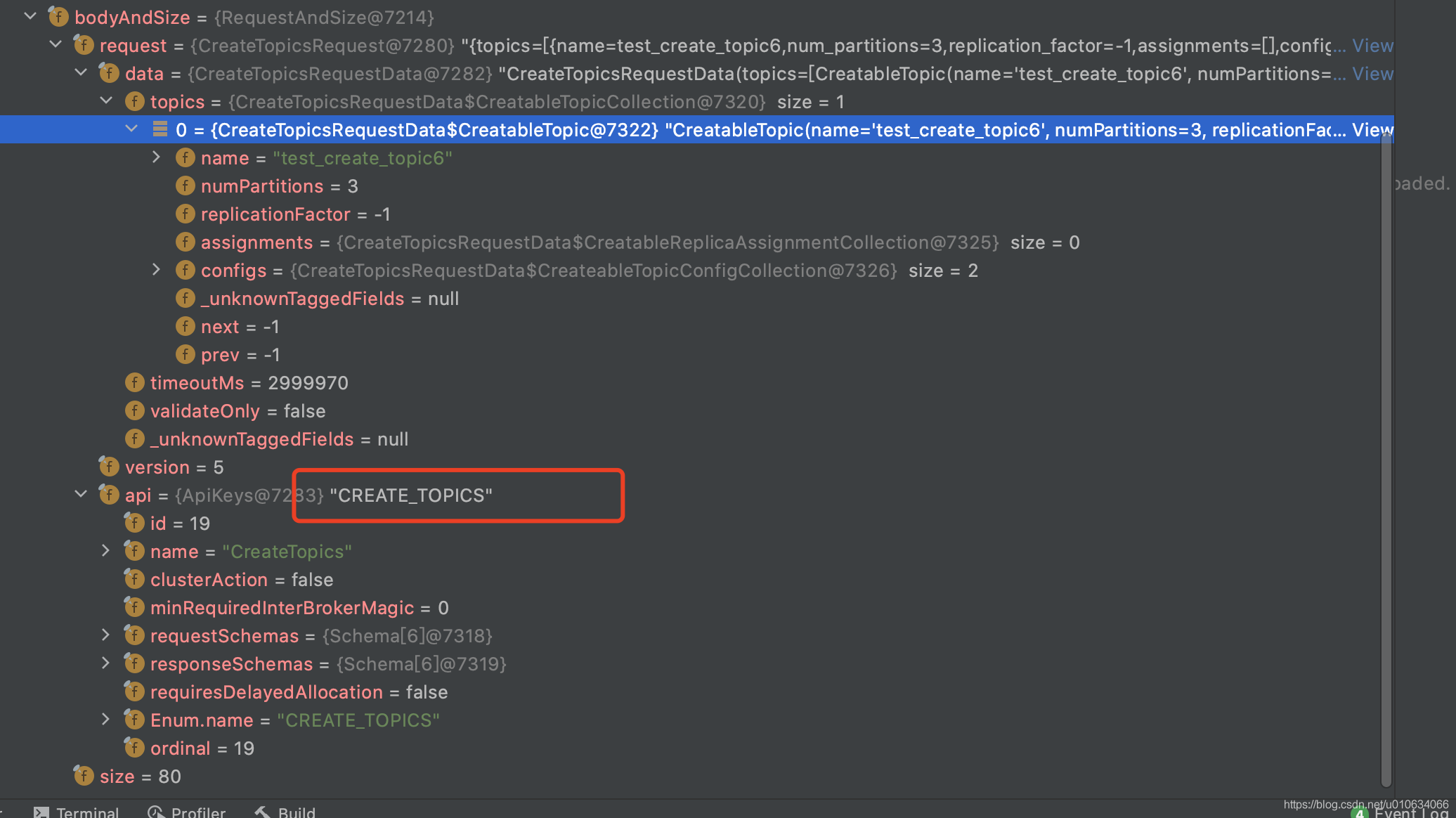
5.1 KafkaApis.handle(request) 根据请求传递Api调用不同接口
进入方法可以看到根据request.header.apiKey 调用对应的方法,客户端传过来的是CreateTopics
5.2 KafkaApis.handleCreateTopicsRequest 处理创建Topic的请求
def handleCreateTopicsRequest(request: RequestChannel.Request): Unit = {
// 部分代码省略
//如果当前Broker不是属于Controller的话,就抛出异常
if (!controller.isActive) {
createTopicsRequest.data.topics.asScala.foreach { topic =>
results.add(new CreatableTopicResult().setName(topic.name).
setErrorCode(Errors.NOT_CONTROLLER.code))
}
sendResponseCallback(results)
} else {
// 部分代码省略
}
adminManager.createTopics(createTopicsRequest.data.timeoutMs,
createTopicsRequest.data.validateOnly,
toCreate,
authorizedForDescribeConfigs,
handleCreateTopicsResults)
}
}
- 判断当前处理的broker是不是Controller,如果不是Controller的话直接抛出异常,从这里可以看出,CreateTopic这个操作必须是Controller来进行, 出现这种情况有可能是客户端发起请求的时候Controller已经变更;
- 鉴权 【Kafka源码】kafka鉴权机制
- 调用
adminManager.createTopics()
5.3 adminManager.createTopics()
创建主题并等等主题完全创建,回调函数将会在超时、错误、或者主题创建完成时触发
该方法过长,省略部分代码
def createTopics(timeout: Int,
validateOnly: Boolean,
toCreate: Map[String, CreatableTopic],
includeConfigsAndMetatadata: Map[String, CreatableTopicResult],
responseCallback: Map[String, ApiError] => Unit): Unit = {
// 1. map over topics creating assignment and calling zookeeper
val brokers = metadataCache.getAliveBrokers.map { b => kafka.admin.BrokerMetadata(b.id, b.rack) }
val metadata = toCreate.values.map(topic =>
try {
//省略部分代码
//检查Topic是否存在
//检查 --replica-assignment参数和 (--partitions || --replication-factor ) 不能同时使用
// 如果(--partitions || --replication-factor ) 没有设置,则使用 Broker的配置(这个Broker肯定是Controller)
// 计算分区副本分配方式
createTopicPolicy match {
case Some(policy) =>
//省略部分代码
adminZkClient.validateTopicCreate(topic.name(), assignments, configs)
if (!validateOnly)
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
case None =>
if (validateOnly)
//校验创建topic的参数准确性
adminZkClient.validateTopicCreate(topic.name, assignments, configs)
else
//把topic相关数据写入到zk中
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
}
}
-
做一些校验检查
①.检查Topic是否存在
②. 检查--replica-assignment参数和 (--partitions || --replication-factor) 不能同时使用
③.如果(--partitions || --replication-factor) 没有设置,则使用 Broker的配置(这个Broker肯定是Controller)
④.计算分区副本分配方式 -
createTopicPolicy根据Broker是否配置了创建Topic的自定义校验策略; 使用方式是自定义实现org.apache.kafka.server.policy.CreateTopicPolicy接口;并 在服务器配置create.topic.policy.class.name=自定义类; 比如我就想所有创建Topic的请求分区数都要大于10; 那么这里就可以实现你的需求了 -
createTopicWithAssignment把topic相关数据写入到zk中; 进去分析一下
5.4 写入zookeeper数据
我们进入到adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)看看有哪些数据写入到了zk中;
def createTopicWithAssignment(topic: String,
config: Properties,
partitionReplicaAssignment: Map[Int, Seq[Int]]): Unit = {
validateTopicCreate(topic, partitionReplicaAssignment, config)
// 将topic单独的配置写入到zk中
zkClient.setOrCreateEntityConfigs(ConfigType.Topic, topic, config)
// 将topic分区相关信息写入zk中
writeTopicPartitionAssignment(topic, partitionReplicaAssignment.mapValues(ReplicaAssignment(_)).toMap, isUpdate = false)
}
源码就不再深入了,这里直接详细说明一下
写入Topic配置信息
- 先调用
SetDataRequest请求往节点/config/topics/Topic名称写入数据; 这里
一般这个时候都会返回NONODE (NoNode);节点不存在; 假如zk已经存在节点就直接覆盖掉 - 节点不存在的话,就发起
CreateRequest请求,写入数据; 并且节点类型是持久节点
这里写入的数据,是我们入参时候传的topic配置--config; 这里的配置会覆盖默认配置
写入Topic分区副本信息
- 将已经分配好的副本分配策略写入到
/brokers/topics/Topic名称中; 节点类型 持久节点
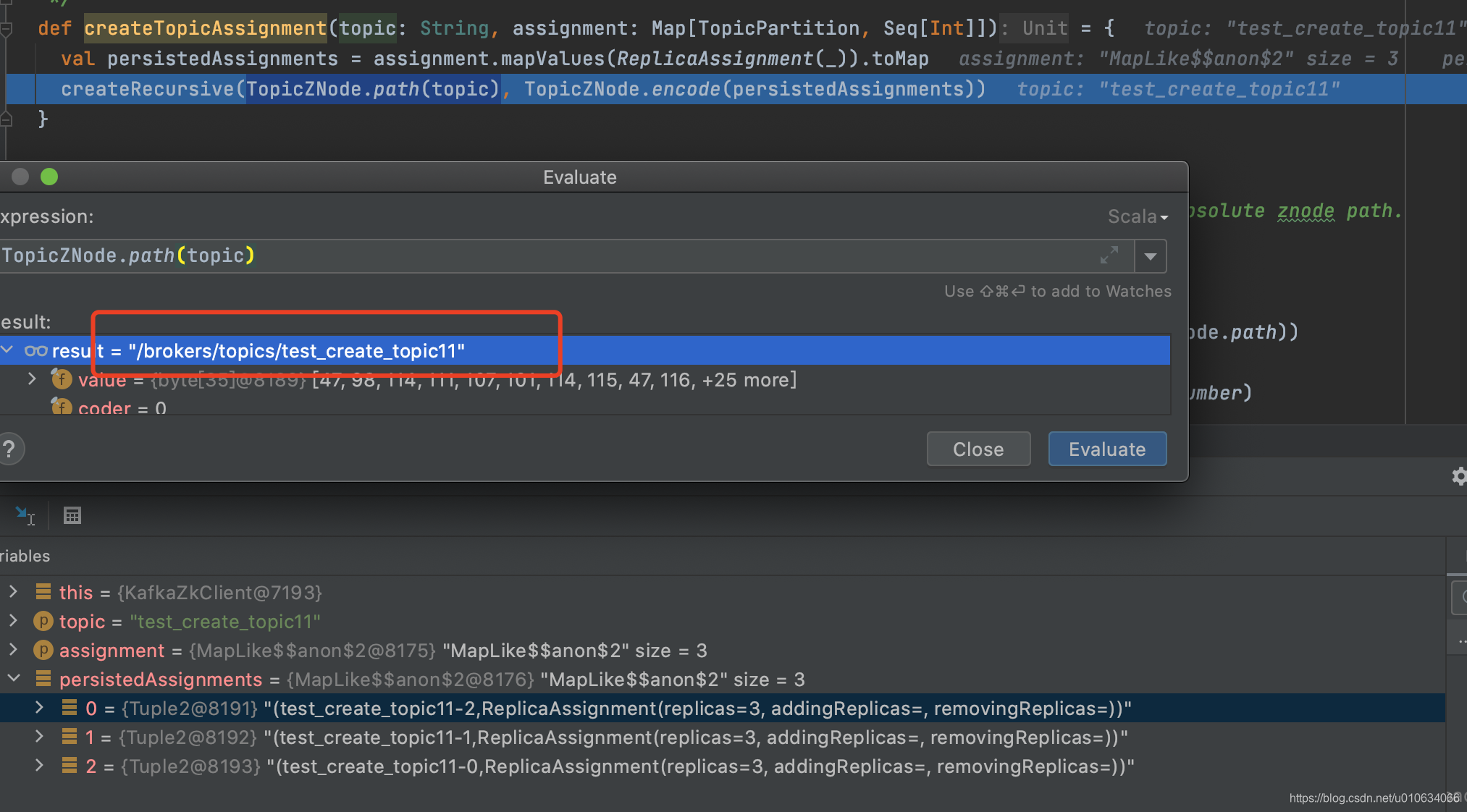
具体跟zk交互的地方在
ZookeeperClient.send() 这里包装了很多跟zk的交互;
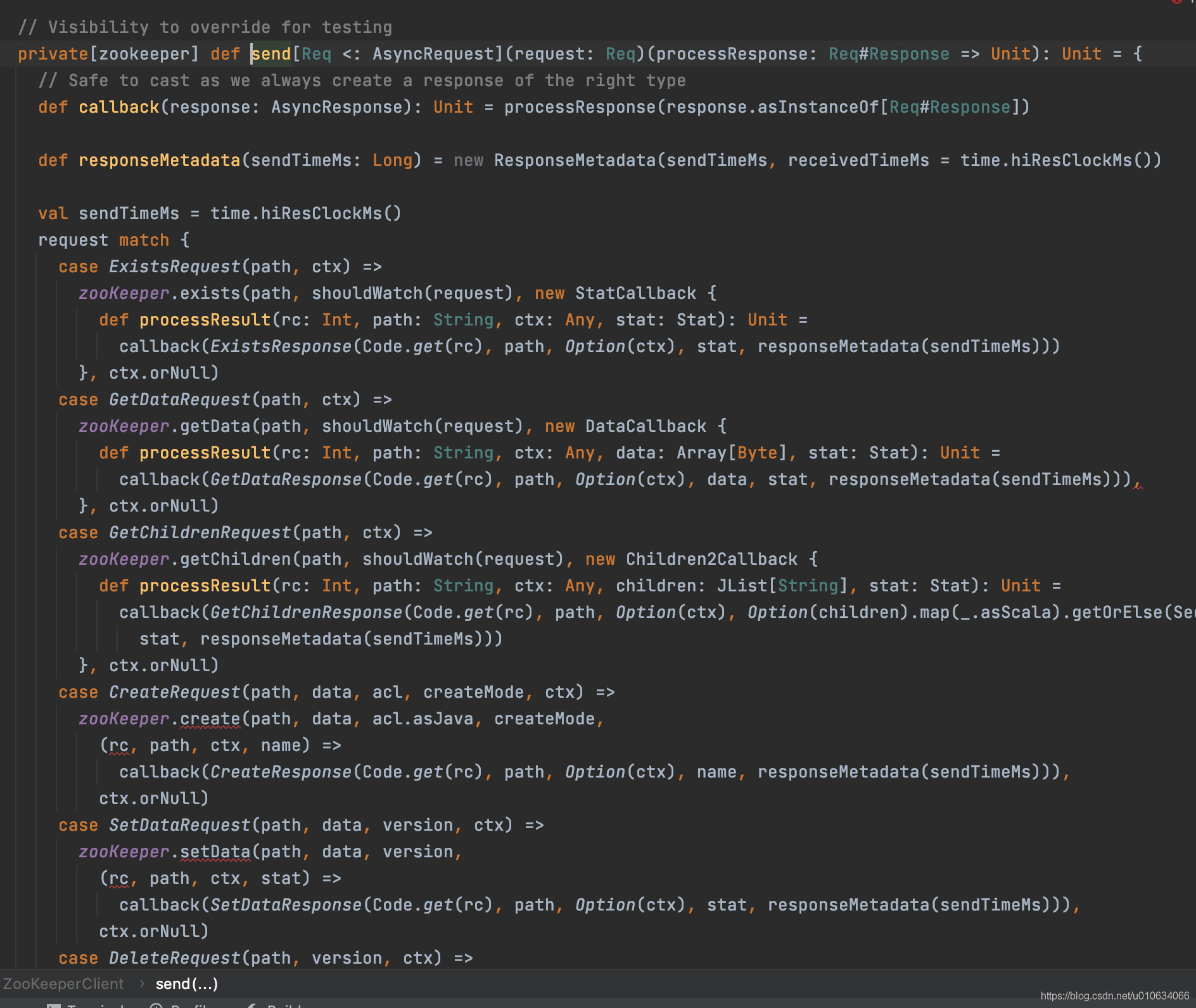
6. Controller监听 /brokers/topics/Topic名称, 通知Broker将分区写入磁盘
Controller 有监听zk上的一些节点; 在上面的流程中已经在zk中写入了
/brokers/topics/Topic名称; 这个时候Controller就监听到了这个变化并相应;
KafkaController.processTopicChange
private def processTopicChange(): Unit = {
//如果处理的不是Controller角色就返回
if (!isActive) return
//从zk中获取 `/brokers/topics 所有Topic
val topics = zkClient.getAllTopicsInCluster
//找出哪些是新增的
val newTopics = topics -- controllerContext.allTopics
//找出哪些Topic在zk上被删除了
val deletedTopics = controllerContext.allTopics -- topics
controllerContext.allTopics = topics
registerPartitionModificationsHandlers(newTopics.toSeq)
val addedPartitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(newTopics)
deletedTopics.foreach(controllerContext.removeTopic)
addedPartitionReplicaAssignment.foreach {
case (topicAndPartition, newReplicaAssignment) => controllerContext.updatePartitionFullReplicaAssignment(topicAndPartition, newReplicaAssignment)
}
info(s"New topics: [$newTopics], deleted topics: [$deletedTopics], new partition replica assignment " +
s"[$addedPartitionReplicaAssignment]")
if (addedPartitionReplicaAssignment.nonEmpty)
onNewPartitionCreation(addedPartitionReplicaAssignment.keySet)
}
-
从zk中获取
/brokers/topics所有Topic跟当前Broker内存中所有BrokercontrollerContext.allTopics的差异; 就可以找到我们新增的Topic; 还有在zk中被删除了的Broker(该Topic会在当前内存中remove掉) -
从zk中获取
/brokers/topics/{TopicName}给定主题的副本分配。并保存在内存中 -
执行
onNewPartitionCreation;分区状态开始流转
6.1 onNewPartitionCreation 状态流转
关于Controller的状态机 详情请看: 【kafka源码】Controller中的状态机
/**
* This callback is invoked by the topic change callback with the list of failed brokers as input.
* It does the following -
* 1. Move the newly created partitions to the NewPartition state
* 2. Move the newly created partitions from NewPartition->OnlinePartition state
*/
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
partitionStateMachine.handleStateChanges(
newPartitions.toSeq,
OnlinePartition,
Some(OfflinePartitionLeaderElectionStrategy(false))
)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}
- 将待创建的分区状态流转为
NewPartition;
- 将待创建的副本 状态流转为
NewReplica;
- 将分区状态从刚刚的
NewPartition流转为OnlinePartition
0. 获取leaderIsrAndControllerEpochs; Leader为副本的第一个;
1. 向zk中写入/brokers/topics/{topicName}/partitions/持久节点; 无数据
2. 向zk中写入/brokers/topics/{topicName}/partitions/{分区号}持久节点; 无数据
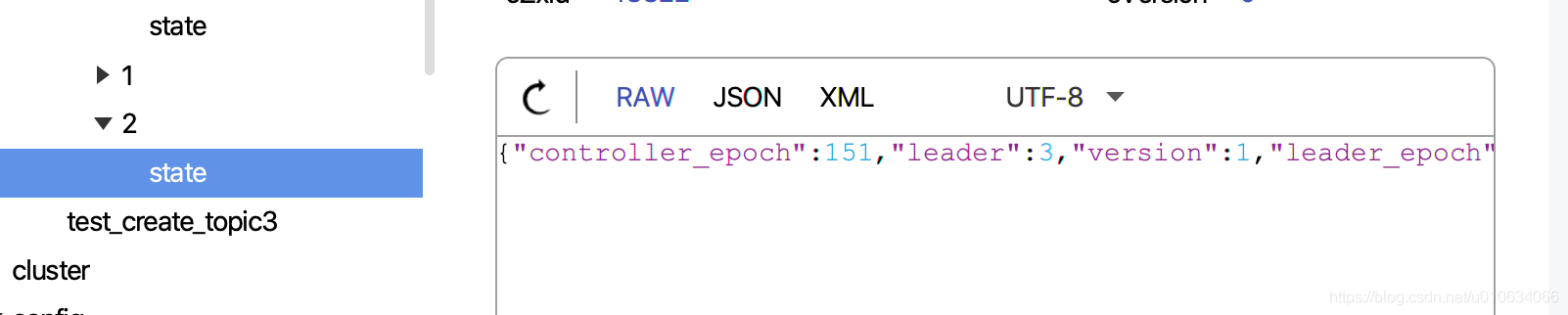
3. 向zk中写入/brokers/topics/{topicName}/partitions/{分区号}/state持久节点; 数据为leaderIsrAndControllerEpoch
- 向副本所属Broker发送
leaderAndIsrRequest请求 - 向所有Broker发送
UPDATE_METADATA请求
- 向副本所属Broker发送
- 将副本状态从刚刚的
NewReplica流转为OnlineReplica,更新下内存
关于分区状态机和副本状态机详情请看【kafka源码】Controller中的状态机
7. Broker收到LeaderAndIsrRequest 创建本地Log
上面步骤中有说到向副本所属Broker发送
leaderAndIsrRequest请求,那么这里做了什么呢
其实主要做的是 创建本地Log代码太多,这里我们直接定位到只跟创建Topic相关的关键代码来分析
KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog
/**
* 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出 KafkaStorageException
*/
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
// create the log if it has not already been created in another thread
if (!isNew && offlineLogDirs.nonEmpty)
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
val logDirs: List[File] = {
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (isFuture) {
if (preferredLogDir == null)
throw new IllegalStateException(s"Can not create the future log for $topicPartition without having a preferred log directory")
else if (getLog(topicPartition).get.dir.getParent == preferredLogDir)
throw new IllegalStateException(s"Can not create the future log for $topicPartition in the current log directory of this partition")
}
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
val logDir = logDirs
.toStream // to prevent actually mapping the whole list, lazy map
.map(createLogDirectory(_, logDirName))
.find(_.isSuccess)
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
.get // If Failure, will throw
val log = Log(
dir = logDir,
config = config,
logStartOffset = 0L,
recoveryPoint = 0L,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (isFuture)
futureLogs.put(topicPartition, log)
else
currentLogs.put(topicPartition, log)
info(s"Created log for partition $topicPartition in $logDir with properties " + s"{${config.originals.asScala.mkString(", ")}}.")
// Remove the preferred log dir since it has already been satisfied
preferredLogDirs.remove(topicPartition)
log
}
}
}
- 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出
KafkaStorageException
Tips:如果关于本篇文章你有疑问,可以关注公众号留言解答


- 点赞
- 收藏
- 关注作者
评论(0)