C库函数与系统函数

C库函数与系统函数
1. C库函数
2. 虚拟地址空间
3. 库函数与系统函数的关系
4. 系统文件操作相关函数
4.1 open函数
4.2 read函数和write函数
4.3 lseek函数
4.4 stat 函数
1. C库函数
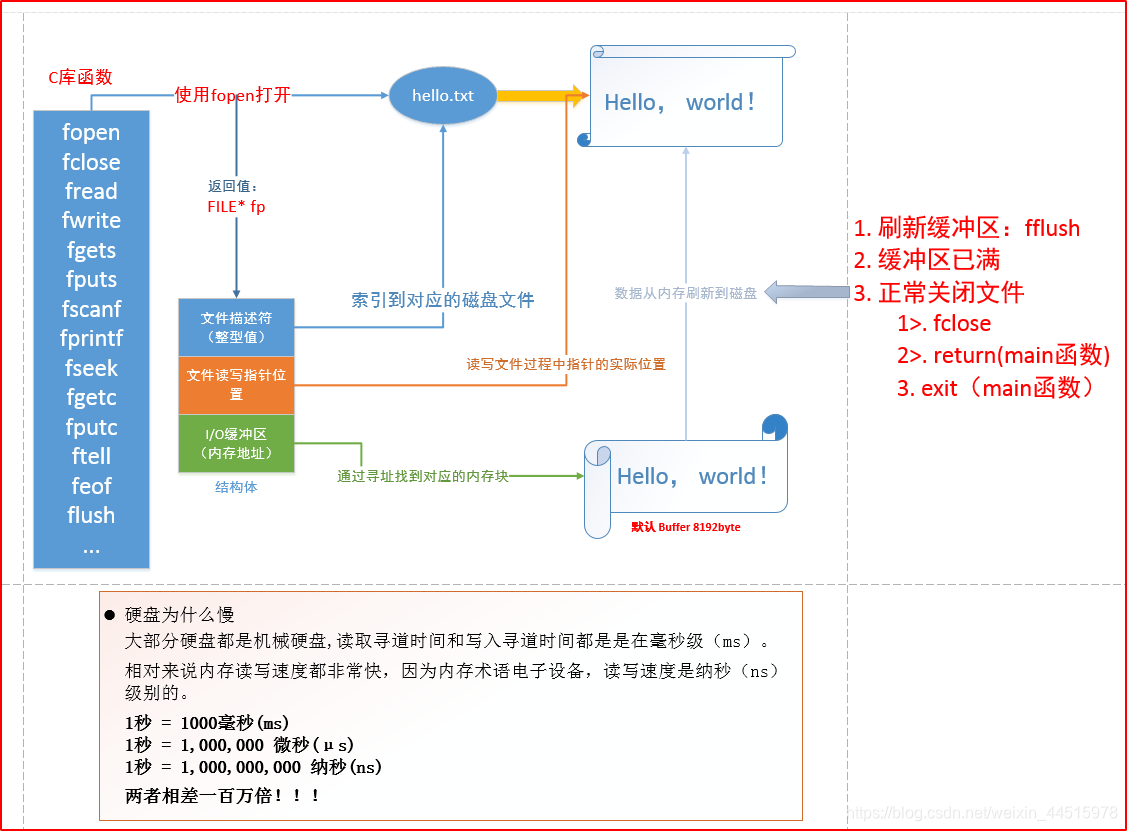
使用C库函数会返回一个FILE * 类型的结构体,结构体中包括以下三个部分:
- 文件描述符:用来标识文件在磁盘中的位置
- 文件读写指针位置:读写文件过程中指针的实际位置。在文件没有关闭时,文件指针在末尾,此时想要读取文件内容,需要用fseek重置文件指针位置到开头。
- IO缓冲区:保存的是内存地址,通过寻址找到对应的内存块,以减少对硬盘操作的次数,默认大小为8kb
eg: 用fgets读取字符时,先把字符放到缓冲区,当缓冲区存满时,再把字符通过fputs存入硬盘,而不是一个字符一个字符的操作
将数据从内存刷新到磁盘的几种方式
- 强制刷新缓冲区:fflush
- 缓冲区已满时
- 正常关闭文件
fclose
return (main函数)
exit (main函数)
2. 虚拟地址空间
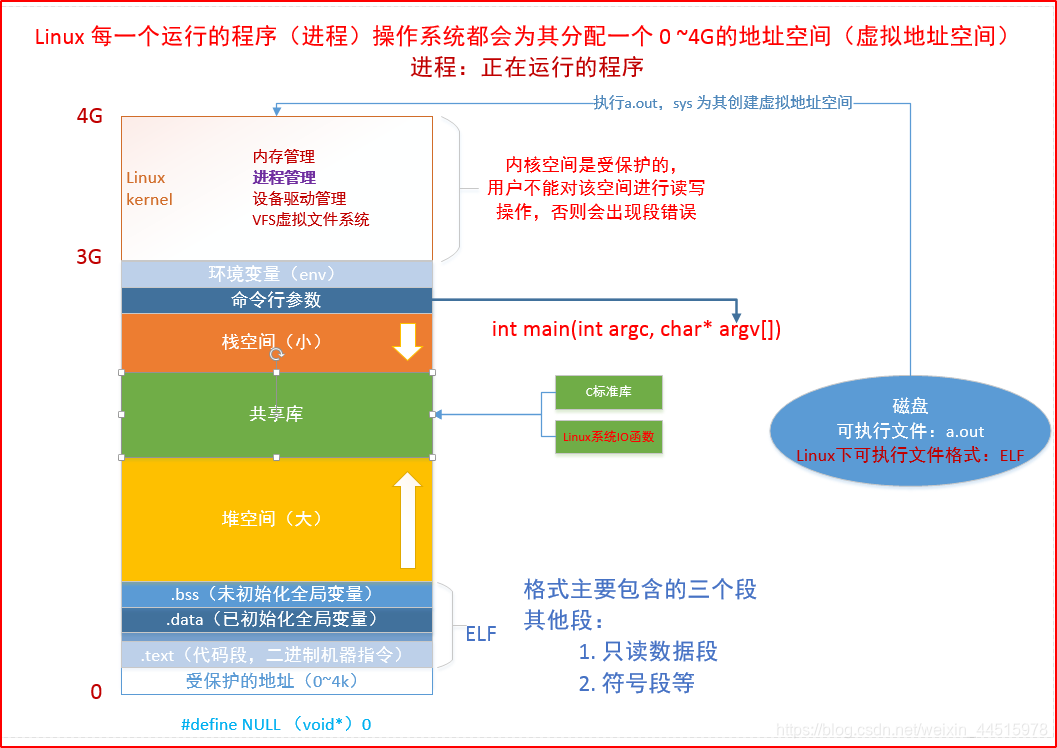
Linux下可执行文件格式:ELF
Linux下通过命令:file 文件名 查看文件格式

- #define NULL (void*) 0 : 指向的是受保护的地址段
- 栈空间分配是从上到下分配
- 堆空间分配是从下到上分配
- 共享库:动态库

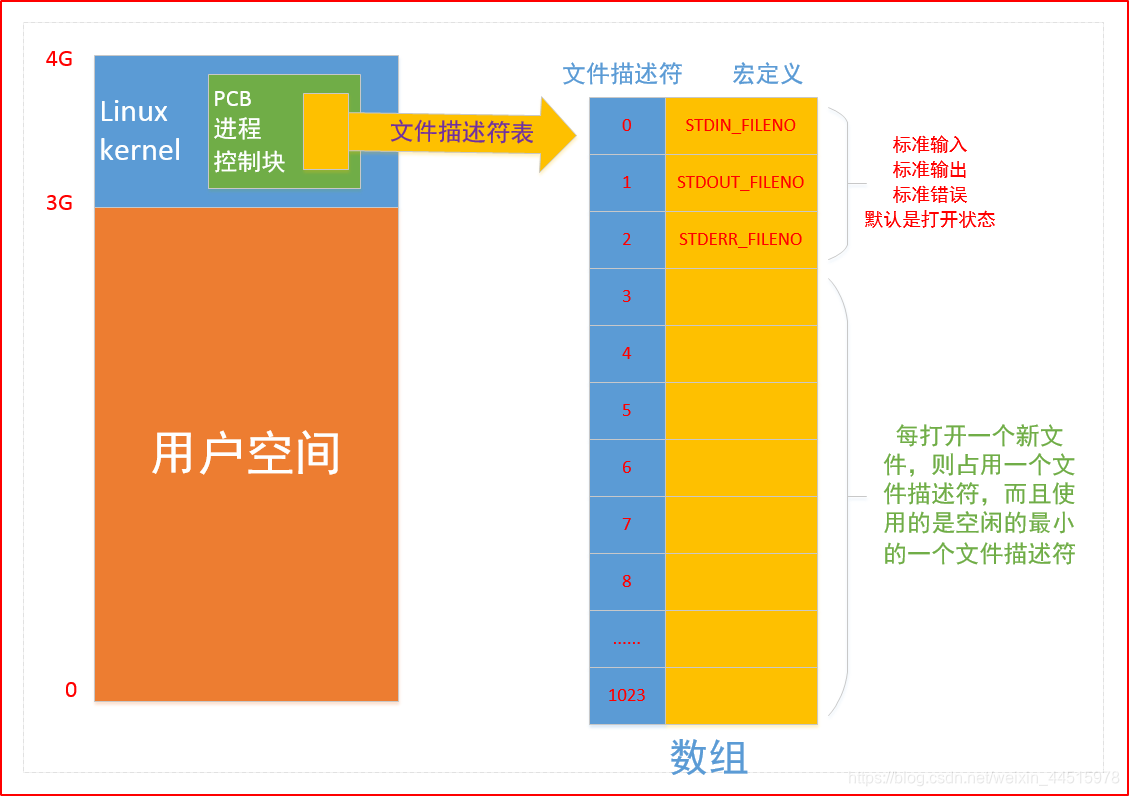
0-3G:用户区,3G-4G:内核区- 在内核区有一个PCB进程控制块,里面有一个文件描述符表,实际上是一个数组,有1024个位置(0-1023),每打开一个新的文件,则占用一个文件描述符。
cpu 为什么要使用虚拟地址空间与物理地址空间映射?解决了什么样的问题?
1.方便编译器和操作系统安排程序的地址分布。程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
2.方便进程之间隔离。不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程使用的物理内存。
3.方便OS使用内存。程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
3. 库函数与系统函数的关系
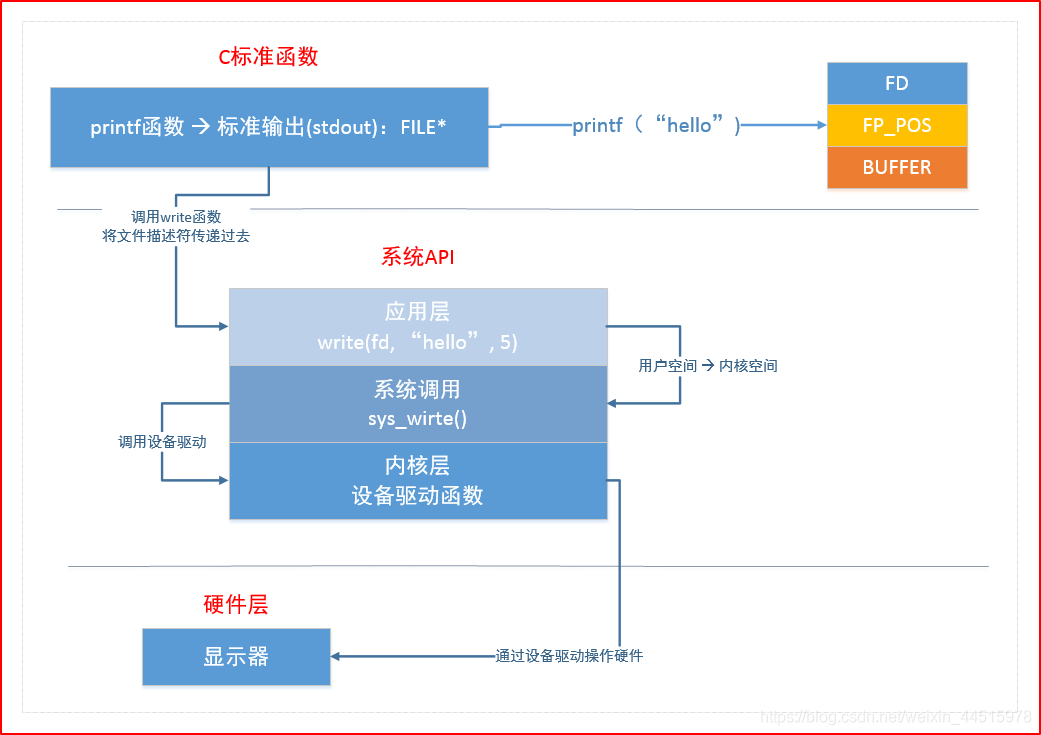
应用层操作0-3G,系统调用操作3G-4G。
4. 系统文件操作相关函数
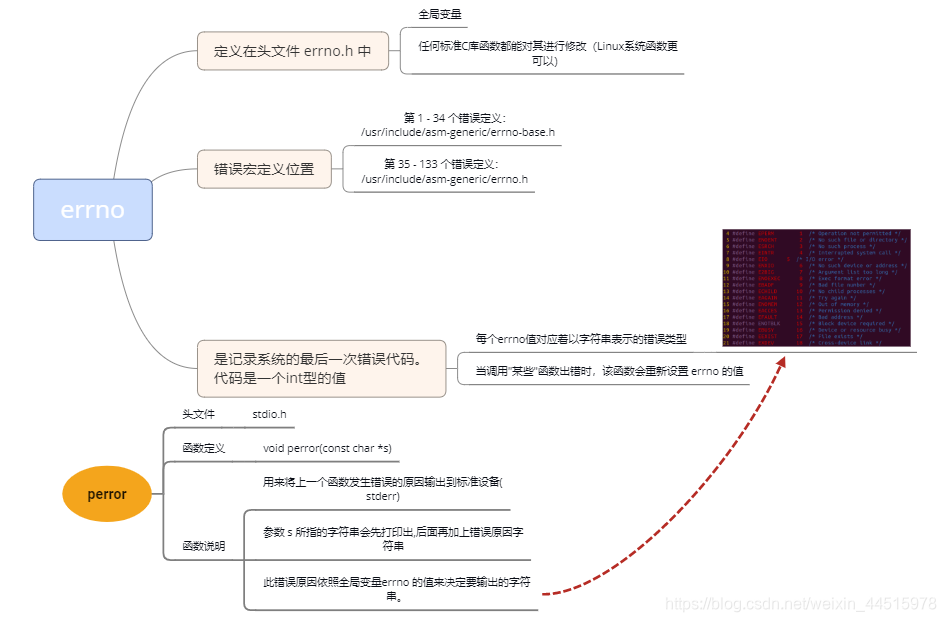
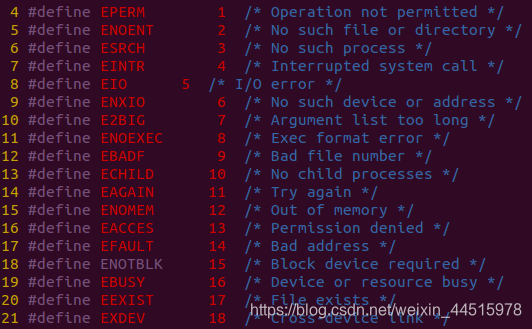
4.1 open函数
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);打开方式(flags):
- 必选项:
O_RDONLY
O_WRONLY
O_RDWR
- 可选项:
- O_CREAT
文件权限: 本地有一个掩码,用命令umask可查看,可修改:umask 掩码
文件的实际权限: 本地掩码(取反) & 实际的文件权限
002(取反) & 777 = 775(111111101 & 111111111 = 111111101)
O_TRUNC:将文件截断为0,就是将文件清空
O_EXCL:判断文件是否存在,与O_CREAT一起使用
O_APPEND
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h> //前三个为open()需要包含的头文件
#include <unistd.h> //close() 需要包含的头文件
#include <stdlib.h> //exit()
#include <stdio.h> //perror()
#include <iostream>
using namespace std;
int main(){
int fd;//定义文件标识符
//打开已有文件
// fd = open("ceshi",O_RDWR);
//创建新文件
fd = open("hello.txt",O_RDWR|O_CREAT,0777);
if(fd == -1){
perror("open file");
exit(1);
}
cout << "fd = " << fd << endl;
//关闭文件
int ret = close(fd);
cout << "ret = " << ret << endl;
if(ret == -1){
perror("close file ");
exit(1);
}
return 0;
}
4.2 read函数和write函数
ssize_t read(int fd, void *buf, size_t count); ssize_t :有符号整型
ssize_t write(int fd, const void *buf, size_t count);read 返回值
- -1 读文件失败
- 0 文件读写完毕
- 大于0 :读取的字节数
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h> //read,write
#include <iostream>
using namespace std;
int main(){
//打开一个以及存在的文件
int fd = open("hello.txt",O_RDONLY);
if(fd == -1){
perror("文件打开失败");
exit(1);
}
//创建一个新文件
int fd1 = open("newfile.txt",O_CREAT | O_WRONLY,0777);
if(fd1 == -1){
perror("创建失败");
exit(1);
}
//读文件
char buf[2048] = {0};
int count = read(fd,buf,sizeof(buf));
if(count == -1){
perror("读文件失败");
exit(1);
}
while(count){
//将读出的数据写入到另一个文件中
int ret = write(fd1,buf,count);
cout << "write bytes: " << ret << endl;
count = read(fd,buf,sizeof(buf));
}
//关闭文件
close(fd);
close(fd1);
return 0;
}4.3 lseek函数
功能:
- 获取文件大小
- 移动文件指针
- 文件拓展
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <iostream>
using namespace std;
int main(){
//打开一个以及存在的文件
int fd = open("hello.txt",O_RDWR);
if(fd == -1){
perror("文件打开失败");
exit(1);
}
//获取文件大小
int ret = lseek(fd,0,SEEK_END);
cout << "文件大小为:" << ret << endl;
//文件拓展
ret = lseek(fd,2000,SEEK_END);
cout << "ret = " << ret << endl;
//实现文件拓展,还需要做一步写操作
write(fd,"a",1);
//关闭文件
close(fd);
return 0;
}4.4 stat 函数
可使用命令:stat 文件名
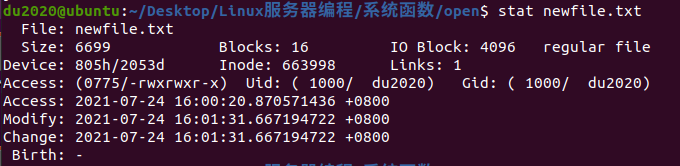
索引节点inode:
- 保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。
- 例如:文件大小,设备标识符,用户标识符,用户组标识符,文件模式,扩展属性,文件读取或修改的时间戳,链接数量,指向存储该内容的磁盘区块的指针,文件分类等等。
- ( 注意数据分成:元数据+数据本身 )
注意inode怎样生成的
- 每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定(现代OS可以动态变化),一般每2KB就设置一个inode。一般文件系统中很少有文件小于2KB的,所以预定按照2KB分,一般inode是用不完的。所以inode在文件系统安装的时候会有一个默认数量,后期会根据实际的需要发生变化。
注意inode号
- inode号是唯一的,表示不同的文件。其实在Linux内部的时候,访问文件都是通过inode号来进行的,所谓文件名仅仅是给用户容易使用的。当我们打开一个文件的时候,首先,系统找到这个文件名对应的inode号;然后,通过inode号,得到inode信息,最后,由inode找到文件数据所在的block,现在可以处理文件数据了。
inode和文件的关系
- 当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。inodes最大数量就是文件的最大数量。
功能:获取文件属性信息
函数原型:int stat(const char *pathname, struct stat *statbuf);
特性:能够穿透(跟踪)符号链接
struct stat {
dev_t st_dev; //文件的设备编号
ino_t st_ino; //节点
mode_t st_mode; //文件的类型和存取的权限
nlink_t st_nlink; //连到该文件的硬连接数目,刚建立的文件值为1
uid_t st_uid; //用户ID
gid_t st_gid; //组ID
dev_t st_rdev; //(设备类型)若此文件为设备文件,则为其设备编号
off_t st_size; //文件字节数(文件大小)
blksize_t st_blksize; //块大小(文件系统的I/O 缓冲区大小)
blkcnt_t st_blocks; //块数
time_t st_atime; //最后一次访问时间
time_t st_mtime; //最后一次修改时间
time_t st_ctime; //最后一次改变时间(指属性)
};版权声明:本文为CSDN博主「贪心的鬼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44515978/article/details/119057049

- 点赞
- 收藏
- 关注作者
评论(0)