AVOD-Net 用于自动驾驶的聚合视图3D对象检测网络

前言
AVOD-Net和MV3D-Net比较像,AVOD-Net算是MV3D-Net的加强版。该论文通过聚合不同视角的数据,实现了自动驾驶场景下3D物体的实时检测。
论文地址:Joint 3D Proposal Generation and Object Detection from View Aggregation
开源代码:https://github.com/kujason/avod
一、框架了解
先看下总体网络结构:(可以点击图片放大查看)
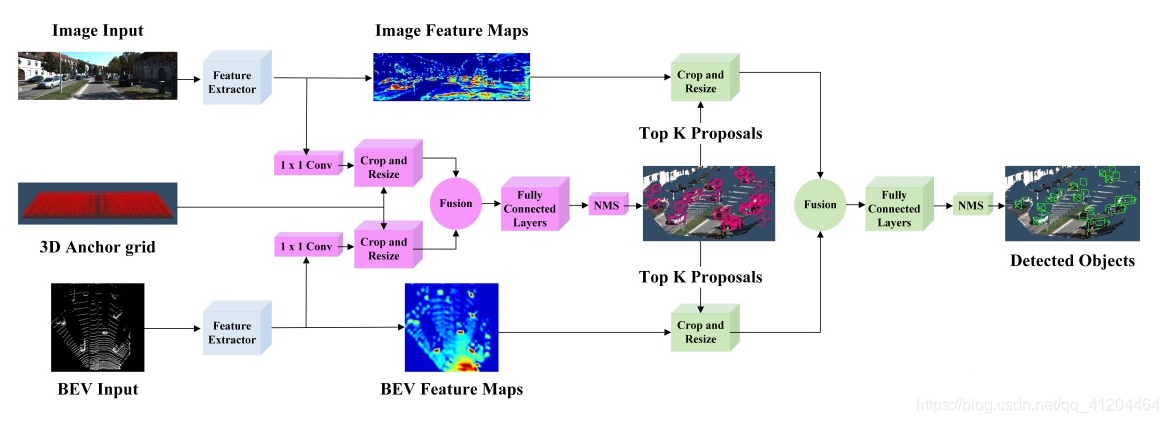
输入的数据:有二种,分别是点云俯视图和二维RGB图像。输出数据:类别标签、3D边界框。
相对于MV3D-Net的改进措施:
- 1)去掉了激光点云的前视图输入。
- 2)在俯视图中去掉了强度信息。
去掉这两个信息仍然能取得号的效果,就说明俯视图和图像信息已经能够完整诠释三维环境了。
二、提取特征
先看一下AVOD-Net如何提取特征的。

![]()
它主要提取出二部分数据,分别是图像特征、点云俯视图特征,其中图像+点云俯视图融合特征,在数据整合起到作用。后面将这二种特征进行融合。
它使用了全分辨率特征,所以为了在整合时降低维度,先进性了1X1的卷积。
AVOD使用的是FPN,包含了encoder和decoder,它可以在保证特征图相对于输入是全分辨率的,而且还能结合底层细节信息和高层语义信息,因此能显著提高物体特别是小物体的检测效果。(对比:MV3D-Net 是使用的VGG16做特征提取。)

![]()
三、数据整合
再看看数据整合。

AVOD使用的是裁剪和调整(crop and resize)。
四、3D Bounding Box的编码上添加了几何约束
MV3D, Axis Aligned, AVOD三种不同的3D Bounding Box编码方式如下图所示,

- AVOD利用一个底面以及高度约束了3D Bounding Box的几何形状,即要求其为一个长方体。
- MV3D只是给出了8个顶点,没有任何的几何约束关系。
此外,MV3D中8个顶点需要一个24维(3x8)的向量表示,而AVOD只需要一个10维(2x4+1+1)的向量即可,做到了很好的编码降维工作。
五、模型效果
与其他模型的对比:
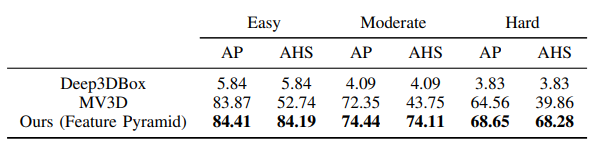
在KITTI上,AVOD目前(2018.7.23)名列前茅,在精度和速度上都表现较好,与MV3D, VoxelNet, F-PointNet对比的结果如下表所示。

![]()
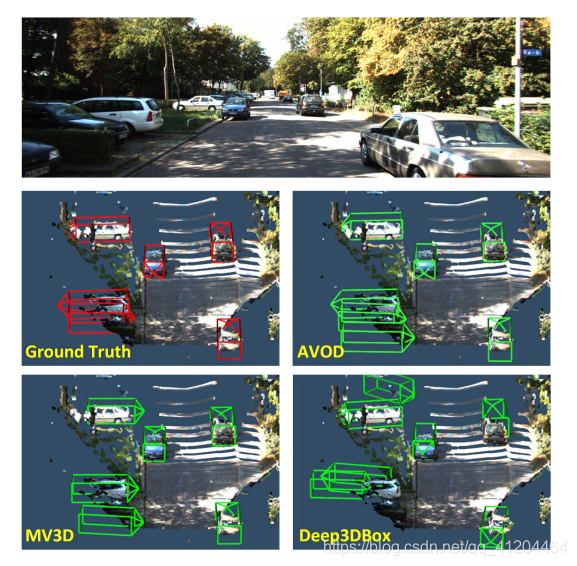
模型预测效果:

本文参考:https://zhuanlan.zhihu.com/p/86340957、https://zhuanlan.zhihu.com/p/40271319

论文地址:Joint 3D Proposal Generation and Object Detection from View Aggregation
开源代码:https://github.com/kujason/avod
本文只提供参考学习,谢谢。

- 点赞
- 收藏
- 关注作者
评论(0)