宽带接收机中的非均匀采样技术研究之OMP算法(2018/8/20)(第七篇)

给出论文地址:宽带接收机中的非均匀采样技术研究
上篇博文的地址:宽带接收机中的非均匀采样技术研究之非均匀采样器(NUS) 采样模型(2018/8/19)(第六篇)
关于OMP算法,之前的博文也有涉及,并且有一个相关的实例,本不该再次提出,但是为了内容的完整性,还是根据论文的思路在来一次吧,参考:《基于压缩传感的匹配追踪重建算法研究》读书笔记
文中推荐的论文,对于研究恢复算法很有帮助。
匹配追踪(MP)算法是比较早的一种贪婪算法,该算法以观测矩阵 Φ 作为完备原子集,从原子集中找出和观测信号最匹配的原子对原始信号进行稀疏逼近,求出信号残差并更新索引集。然后继续选择,寻找和上一次计算出的残差最匹配的原子,反复迭代,直到残差小于一定门限时,结束迭代操作。这样一来,原始信号就可以用较少的原子对其进行近似表示。但是,MP 算法在利用迭代选择原子集合时,并不能保证原始信号在所选集合上的垂直投影是正交的。这就不能保证每次选择的结果都是最优的。
正交匹配追踪(OMP)算法是对 MP 算法的一种改进算法。其改进之处就在于,在每一次的迭代选择中,都对所选择的原子完成正交化处理。虽然这两种算法都采用的是原子选择的方法,但是 OMP 算法在每次迭代时都将选择好的原子集进行正交化,从而确保每次迭代的结果都是最优的,从而减少了迭代所需的次数,最大限度上保证了信号重构的准确性。
OMP 算法的主要思想是对观测矩阵的列进行选择,让被选择的列和当前向量尽可能的相关,然后再从这些观测向量中减去相关的部分,反复进行这个迭代操作,当迭代次数达预设的稀疏度 K 时,停止迭代。
OMP算法的基本步骤
OMP 算法的实现可以分为以下六步,图 2.10 为 OMP 算法的流程图:



关于这个算法,看到这里可以说整个人都是懵逼的,你不妨多看几遍,然后还会是懵逼的。
怎么办呢?补充自己的知识库呗,通过其他途径了解更多。上面这段全是论文上的内容,可谓是简洁到不知道如何才能懂!
我之前也简单的了解了下OMP算法,可以参看这篇博文:《基于压缩传感的匹配追踪重建算法研究》读书笔记
其实上面的步骤中也可能出现一些疏漏,下面贴出另一版步骤,供对照参看:


这里再贴出(沙威)的代码,这应该是给入门者的福利了:
-
% 1-D信号压缩传感的实现(正交匹配追踪法Orthogonal Matching Pursuit)
-
% 测量数M>=K*log(N/K),K是稀疏度,N信号长度,可以近乎完全重构
-
-
-
clc;clear;close all;
-
% 1. 时域测试信号生成
-
K = 7; % 稀疏度(做FFT可以看出来)
-
N = 256; % 信号长度
-
M = 64; % 测量数(M>=K*log(N/K),至少40,但有出错的概率)
-
f1 = 50; % 信号频率1
-
f2 = 100; % 信号频率2
-
f3 = 200; % 信号频率3
-
f4 = 400; % 信号频率4
-
fs = 800; % 采样频率
-
ts = 1/fs; % 采样间隔
-
Ts = 1:N; % 采样序列
-
x = 0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts); % 完整信号,由4个信号叠加而来
-
% 2. 时域信号压缩传感
-
Phi = randn(M,N); % 观测矩阵,(M*N)64*256的扁矩阵
-
y = Phi*x.'; % 获得观测向量y,(M*1)
-
% 3. 正交匹配追踪法重构信号(本质上是L_1范数最优化问题)
-
m = 2*K; % 算法迭代次数(m>=K),设x是K-sparse的
-
Psi = fft(eye(N,N))/sqrt(N); % 标准正交基字典(离散傅里叶变换标准正交基矩阵)x'=Psi'*s;(s = Psi*x')
-
T = Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵)
-
hat_s = zeros(1,N); % 待重构的谱域(变换域)向量(行向量1*N)
-
Aug_t = []; % 增量矩阵(初始值为空矩阵)
-
r_n = y; % 残差值
-
product = zeros(1,N);
-
for times = 1:m % 迭代次数
-
for col = 1:N % 恢复矩阵的所有列向量
-
product(col) = abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
-
end
-
[val,pos] = max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
-
Aug_t = [Aug_t,T(:,pos)]; % 矩阵扩充
-
-
T(:,pos) = zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
-
aug_s = (Aug_t'*Aug_t)^(-1)*Aug_t'*y; % 最小二乘,使残差最小
-
r_n = y-Aug_t*aug_s; % 残差
-
pos_array(times) = pos; % 纪录最大投影系数的位置
-
end
-
hat_s(pos_array)=aug_s; % 重构的谱域向量
-
hat_x=real(Psi'*hat_s.'); % 做逆傅里叶变换重构得到时域信号
-
-
%% 4. 恢复信号和原始信号对比
-
figure(1);
-
hold on;
-
plot(hat_x,'k.-') % 重建信号
-
plot(x,'r') % 原始信号
-
legend('Recovery','Original')
-
norm(hat_x.'-x)/norm(x)
这个代码,虽然基础但是还是有几处难点的,我想讲解以上这个代码之前我门先把各个向量的维数弄明白再说:

然后我改了上面的几行代码,并运行了一下,看看结果:
更改后的代码:
% 1-D信号压缩传感的实现(正交匹配追踪法Orthogonal Matching Pursuit)
% 测量数M>=K*log(N/K),K是稀疏度,N信号长度,可以近乎完全重构
clc;clear;close all;
% 1. 时域测试信号生成
K = 7; % 稀疏度(做FFT可以看出来)
N = 256; % 信号长度
M = 64; % 测量数(M>=K*log(N/K),至少40,但有出错的概率)
f1 = 50; % 信号频率1
f2 = 100; % 信号频率2
f3 = 200; % 信号频率3
f4 = 400; % 信号频率4
fs = 800; % 采样频率
ts = 1/fs; % 采样间隔
Ts = 1:N; % 采样序列
x = 0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts);% 完整信号,由4个信号叠加而来% 2. 时域信号压缩传感
Phi = randn(M,N); % 观测矩阵,(M*N)64*256的扁矩阵
y = Phi*x.'; % 获得观测向量y,(M*1)
% 3. 正交匹配追踪法重构信号(本质上是L_1范数最优化问题)
m = 2*K; % 算法迭代次数(m>=K),设x是K-sparse的
Psi = fft(eye(N,N))/sqrt(N); % 标准正交基字典(离散傅里叶变换标准正交基矩阵)x'=Psi'*s;(s = Psi*x')
T = Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵)
hat_s = zeros(1,N); % 待重构的谱域(变换域)向量(行向量1*N)
Aug_t = []; % 增量矩阵(初始值为空矩阵)
r_n = y; % 残差值
product = zeros(1,N); % 该变量用于存放內积
for times = 1:m % 迭代次数
for col = 1:N % 恢复矩阵的所有列向量
product(col) = abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos] = max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t = [Aug_t,T(:,pos)]; % 矩阵扩充
T(:,pos) = zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
aug_s = (Aug_t'*Aug_t)^(-1)*Aug_t'*y; % 最小二乘,使残差最小
r_n = y-Aug_t*aug_s; % 残差
pos_array(times) = pos; % 纪录最大投影系数的位置
end
hat_s(pos_array)=aug_s; % 重构的谱域向量
hat_x=real(Psi'*hat_s.'); % 做逆傅里叶变换重构得到时域信号
%% 4. 恢复信号和原始信号对比subplot(3,1,1);
plot(hat_x,'k.-') % 重建信号
title('recovery');
subplot(3,1,2);
plot(x,'r') % 原始信号
title('original');subplot(3,1,3);
% figure(1);
hold on;
plot(hat_x,'k.-') % 重建信号
plot(x,'r') % 原始信号legend('Recovery','Original')
norm(hat_x.'-x)/norm(x)
结果:

第二幅图是原始信号x,第一幅图是恢复出来的原始信号,第三幅图是二者画到同一副图上的样子,可见恢复出来的信号是十分的完美的。
下面我们正式的讲解代码,其实注释的已经很清楚了,但是还会有几处难点,我来讲解一下自己的理解,重要的点我会用红色加粗标出:
clc;clear;close all;
% 1. 时域测试信号生成
K = 7; % 稀疏度(做FFT可以看出来)
N = 256; % 信号长度
M = 64; % 测量数(M>=K*log(N/K),至少40,但有出错的概率)
f1 = 50; % 信号频率1
f2 = 100; % 信号频率2
f3 = 200; % 信号频率3
f4 = 400; % 信号频率4
fs = 800; % 采样频率
ts = 1/fs; % 采样间隔
Ts = 1:N; % 采样序列
x = 0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts);% 完整信号,由4个信号叠加而来
首先是这一小段代码,是用来定义原始信号的,假设一个原始的信号是一个正弦信号,由于我们已经知道了这个原始信号,所以可以通过做FFT得到它的频谱图,从频谱图或者频域上看出它的稀疏度,这个离散的原始信号是由模拟的正弦信号经过均匀采样得到的,采样率满足奈奎斯特采样率。
既然该信号可以在频域表示为稀疏的信号,那么稀疏基也就是离散傅里叶变换(DFT或者FFT)标准正交基。
% 2. 时域信号压缩传感
Phi = randn(M,N); % 观测矩阵,(M*N)64*256的扁矩阵
y = Phi*x.'; % 获得观测向量y,(M*1)
这两行代码的意思是产生一个观测矩阵,并由此得到观测向量。
重构的实质就是 解y = Phi*x.'这个病态方程,为什么这么说呢?因为Phi本身是一个M*N的矩阵,且M<<N,那么M个方程,N个未知数方程组肯定是有无数个解的,这数学中这是一个病态方程。
可是压感为什么需要解这个病态的方程呢?这就是压感另辟蹊径,虽然这是一个病态方程,可是原始信号x可以进行稀疏表示,如果是K稀疏的话,K<<M,就是x的稀疏表示x = Psi* alpha;这个alpha中仅有K个元素不为0,且分布在alpha的不确定的位置上。如果这个观测矩阵和稀疏基满足一定的条件,这个方程就有唯一解,也就是能够重构出x。
继续往下看:
% 3. 正交匹配追踪法重构信号(本质上是L_1范数最优化问题)
m = 2*K; % 算法迭代次数(m>=K),设x是K-sparse的
Psi = fft(eye(N,N))/sqrt(N); % 标准正交基字典(离散傅里叶变换标准正交基矩阵)x'=Psi'*s;(s = Psi*x')
T = Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵)
hat_s = zeros(1,N); % 待重构的谱域(变换域)向量(行向量1*N)
Aug_t = []; % 增量矩阵(初始值为空矩阵)
r_n = y; % 残差值
product = zeros(1,N); % 该变量用于存放內积
for times = 1:m % 迭代次数
for col = 1:N % 恢复矩阵的所有列向量
product(col) = abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos] = max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t = [Aug_t,T(:,pos)]; % 矩阵扩充
T(:,pos) = zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
aug_s = (Aug_t'*Aug_t)^(-1)*Aug_t'*y; % 最小二乘,使残差最小
r_n = y-Aug_t*aug_s; % 残差
pos_array(times) = pos; % 纪录最大投影系数的位置
end
这么一段代码就比较刺激了,它完成的是OMP算法的那个迭代的过程,这需要结合迭代步骤来看:
m = 2*K; % 算法迭代次数(m>=K),设x是K-sparse的
Psi = fft(eye(N,N))/sqrt(N); % 标准正交基字典(离散傅里叶变换标准正交基矩阵)x'=Psi'*s;(s = Psi*x')
T = Phi*Psi'; % 恢复矩阵(测量矩阵*正交反变换矩阵)
算法的迭代次数,至少为K次,这里也产生了一个稀疏基,它在这里的具体环境下是一个标准正交基,然后有稀疏基和观测矩阵得到一个恢复矩阵。
hat_s = zeros(1,N); % 待重构的谱域(变换域)向量(行向量1*N)
Aug_t = []; % 增量矩阵(初始值为空矩阵)
r_n = y; % 残差值
product = zeros(1,N); % 该变量用于存放內积
hat_s是x的稀疏表示,这里是x在频域的表示形式,在恢复算法中,它是要恢复的对象,恢复出来之后与稀疏基相乘就可以得到原始信号了。这里是迭代的准备过程,所以初始化为一个1行N列的元素全零的行向量。
for times = 1:m % 迭代次数
for col = 1:N % 恢复矩阵的所有列向量
product(col) = abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
[val,pos] = max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t = [Aug_t,T(:,pos)]; % 矩阵扩充
T(:,pos) = zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
aug_s = (Aug_t'*Aug_t)^(-1)*Aug_t'*y; % 最小二乘,使残差最小
r_n = y-Aug_t*aug_s; % 残差
pos_array(times) = pos; % 纪录最大投影系数的位置
end
下面就到这个大循环里面的内容了,这是整个迭代过程。
该大循环里面的小循环:
for col = 1:N % 恢复矩阵的所有列向量
product(col) = abs(T(:,col)'*r_n); % 恢复矩阵的列向量和残差的投影系数(内积值)
end
是为了找到恢复矩阵的所有列中与残差的內积值放到product这个向量中,例如恢复矩阵的第一列与残差的內积值放到product向量的第一个位置,依次类推。
[val,pos] = max(product); % 最大投影系数对应的位置,即找到一个其标记看上去与收集到的数据相关的小波
Aug_t = [Aug_t,T(:,pos)]; % 矩阵扩充
这两行代码中的第一行的意思是:上面既然把恢复矩阵的每一列与残差的內积值放到了product中,那么这一行代码就是找到那一个內积值最大,主要得到一个pos,这是內积值最大的恢复矩阵的那一列的位置。
至于第二行代码就是把恢复矩阵中恢复矩阵与残差內积值最大的那一列放到Aug_t中,形成一个新的矩阵,该矩阵的列出是不断变换的,随着迭代次数变化,如果迭代次数为times,那么Aug_t的维度为N*times。
T(:,pos) = zeros(M,1); % 选中的列置零(实质上应该去掉,为了简单我把它置零),在数据中去除这个标记的所有印迹
该行代码是把恢复矩阵中內积值最大的那一列去掉,或置零,主要是为了下一次迭代做准备,本次迭代找出了这一列,下一次肯定不能再用了呀。
(T(:,pos)=zeros(M,1); 这一句是为了下一次迭代做准备的,这次找到了与残差最相关的列,将残差更新后,下次再找与残差仅次于这一列的T的另外一列;)
下面的语句我参考这篇博文上的说法:压缩感知“Hello World”代码初步学习,人家说的很清楚了,我没必要说了。
aug_s=(Aug_t'*Aug_t)^(-1)*Aug_t'*y;
首先我们针对的是y=T*hat_s,现在是已知y求hat_s,现在假如说矩阵T为N*N方阵且满秩(即N个未知数,N个独立的方程),那么很容易知道hat_y=T^-1 * s,其中T^-1表示矩阵T的逆矩阵。但是现在T是一个M*N的扁矩阵,矩阵T没有常规意义上的逆矩阵,这里就有“广义逆”的概念,hat_y的解可能是不存在的,我们这里要求的是最小二乘解aug_s,最小二乘解aug_s将使y-T*aug_s这个列向量2范数最小。
对于用矩阵形式表达的线性方程组:
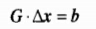
它的最小二乘解为:
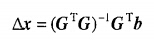
其中
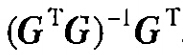
即为矩阵G的最小二乘广义逆(广义逆的一种)。
有了这些知识背景后代码就容易理解了,在第三步中,得到矩阵T中的与残差r_n最相关的列组成的矩阵Aug_t,而第四步实际上就是在求方程组Aug_t*aug_s=y的最小二乘解。
r_n=y-Aug_t*aug_s;这一句就是用求得的最小二乘解更新残差r_n,在下一次迭代中使用。注意最小二乘解的含义,它并不是使Aug_t*aug_s=y成立,而只是让y-Aug_t*aug_s的2范数最小,而r_n就是最小的值。
pos_array(times)=pos; 把与T中与残差最相关的列号记下来,恢复时使用。
到此,主要的for循环就说完了。
上面说了这么多,我想解释下残差是什么?我也是从代码中得到的概念,例如:
y = Aug_t*aug_s这个方程组的最小二乘解为aug_s,残差就是y - Aug_t*aug_s,目的是让这个最小二乘解尽量准确,使得y - Aug_t*aug_s,也就是残差值尽可能的小。这个迭代的目的也就是如此,迭代多次就是为了让残差尽可能的小。
hat_s(pos_array)=aug_s; % 重构的谱域向量
hat_x=real(Psi'*hat_s.'); % 做逆傅里叶变换重构得到时域信号
事实上,这两行代码才是我最想说的,从维数关系上看:
![]()
![]()
![]()
可见,aug_s是一个14*1的列向量,而pos_array是一个1*14的行向量,hat_s是一个1*256的行向量,然后pos_array作为hat_s的下标,将aug_s赋值给了hat_s,这是什么意思呢?
咋一看,是否有点荒唐。我寻遍各路英雄,才明白。
分享出来供大家参考呗:
首先我们得明白各个向量的含义,这个是重点,然后才知道MATLAB这个软件的强大(随意)。
pos_array的出处在:
pos_array(times) = pos; % 纪录最大投影系数的位置
含义是最大投影系数的位置,也就是恢复矩阵中的列与残差內积值最大的列的位置。
aug_s是最小二乘解,hat_s是需要恢复的频域的稀疏信号,把aug_s中的值按pos_array中元素的记录的位置赋值给hat_s,这就相当于把几个非零的信息,插入到hat_s中了,hat_s就是频域的一个稀疏信号了。之后再乘上稀疏基就得到了恢复出来的原始信号x。
不好用语言表达,只能这么说了。
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/81838129

- 点赞
- 收藏
- 关注作者
评论(0)