FPGA时序案例分析【Vivado版】

时序问题一直是一个难以理解的难点,这里通过一个简单的实际案例来学习下时序分析,以及解决的方案。
本博文使用Vivado来进行测试分析。
下面给出测试代码:
-
`timescale 1ns / 1ps
-
//
-
// Company:
-
// Engineer:
-
//
-
// Create Date: 2019/03/19 09:58:03
-
// Design Name:
-
// Module Name: time_analyze
-
//
-
//
-
-
-
module time_analyze(
-
input [4:0] data_in,
-
input clk,
-
input reset,
-
output reg [4:0] data_out
-
);
-
-
reg [4:0] data_tmp_in;
-
wire [4:0] data_tmp_out;
-
wire [4:0] data_tmp2,data_tmp3,data_tmp4,data_tmp5,data_cal_out;
-
-
always@ (posedge clk) begin
-
if(reset) data_tmp_in <= 0;
-
else data_tmp_in <= data_in;
-
end
-
-
//连续乘法,增加逻辑门数量
-
assign data_tmp2 = data_tmp_in * 3;
-
assign data_tmp3 = data_tmp2 * data_tmp_in;
-
assign data_tmp4 = data_tmp3 * data_tmp2;
-
assign data_tmp5 = data_tmp4 * data_tmp3;
-
assign data_cal_out = data_tmp5;
-
-
always@ (posedge clk) begin
-
if(reset) data_out <= 0;
-
else data_out <= data_cal_out;
-
end
-
-
-
endmodule
代码说明:
从测试代码可以看出,本测试故意使用多级乘法来增加逻辑延迟,故意让时序尽可能不满足。
assign data_tmp2 = data_tmp_in * 3;
assign data_tmp3 = data_tmp2 * data_tmp_in;
assign data_tmp4 = data_tmp3 * data_tmp2;
assign data_tmp5 = data_tmp4 * data_tmp3;
assign data_cal_out = data_tmp5;
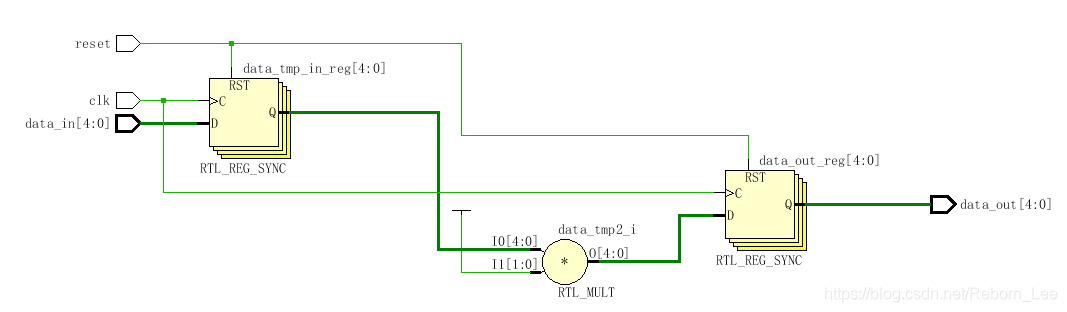
对代码进行RTL分析,得原理图:

可见,两边为寄存器,中间为一系列的组合逻辑。
之后进行综合、实现:
如下图:

在Design Runs状态栏里,看到impl_1前面有一个感叹号,这就表示布线的时序不通过。
继续查看:

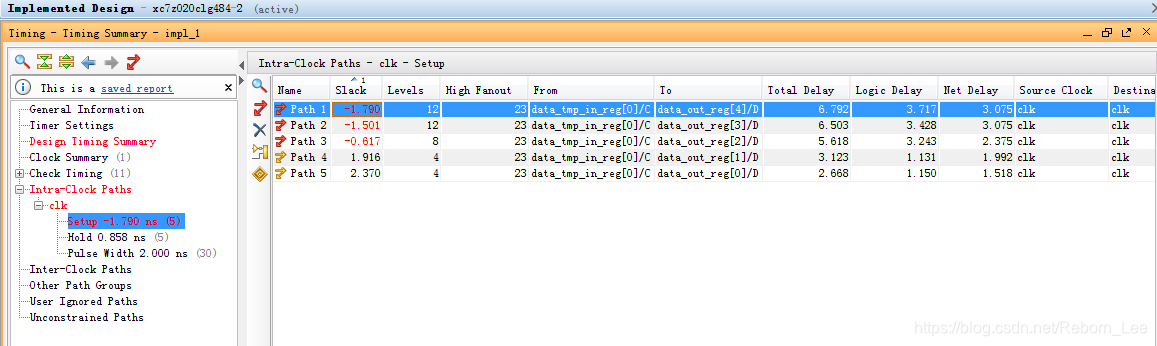


由以上信息可知,建立时间不满足,以路径1为例,裕量为-1.790ns。单击-1.790可见,弹出对话框表示,这条路径需要数据在9.422ns到达第二个触发器的输入,但实际消耗了11.212ns,导致建立时间不足。
数据到达时间太长,易知是逻辑延迟以及布线延迟等引起,下面我们提供几种方案解决本例中的时序不满足问题。
时序优化:
(1)简化逻辑
简单粗暴一点,通过减少器件的数目,来减少逻辑延迟,使之能够符合时序要求。
更改后代码如下:
-
`timescale 1ns / 1ps
-
//
-
// Company:
-
// Engineer:
-
//
-
// Create Date: 2019/03/19 09:58:03
-
// Design Name:
-
// Module Name: time_analyze
-
//
-
-
-
module time_analyze(
-
input [4:0] data_in,
-
input clk,
-
input reset,
-
output reg [4:0] data_out
-
);
-
-
reg [4:0] data_tmp_in;
-
wire [4:0] data_tmp_out;
-
wire [4:0] data_tmp2,data_tmp3,data_tmp4,data_tmp5,data_cal_out;
-
-
always@ (posedge clk) begin
-
if(reset) data_tmp_in <= 0;
-
else data_tmp_in <= data_in;
-
end
-
-
//连续乘法,增加逻辑门数量
-
assign data_tmp2 = data_tmp_in * 3;
-
/* assign data_tmp3 = data_tmp2 * data_tmp_in;
-
assign data_tmp4 = data_tmp3 * data_tmp2;
-
assign data_tmp5 = data_tmp4 * data_tmp3;*/
-
assign data_cal_out = data_tmp2;
-
-
always@ (posedge clk) begin
-
if(reset) data_out <= 0;
-
else data_out <= data_cal_out;
-
end
-
-
-
endmodule
RTL电路图如下:
可见:


时序便没有了问题。
(2)插入触发器
在组合逻辑中间插入触发器,将原本需要一个周期完成的逻辑转换成两个周期完成,分散了时序的压力,从而使时序达到要求。当然,这会使数据多出一个周期的延迟。
修改例子中的组合逻辑,插入以一级触发器,代码如下:
-
`timescale 1ns / 1ps
-
//
-
// Company:
-
// Engineer:
-
//
-
// Create Date: 2019/03/19 09:58:03
-
// Design Name:
-
// Module Name: time_analyze
-
//
-
//
-
-
-
module time_analyze(
-
input [4:0] data_in,
-
input clk,
-
input reset,
-
output reg [4:0] data_out
-
);
-
-
reg [4:0] data_tmp_in;
-
wire [4:0] data_tmp_out;
-
wire [4:0] data_tmp2,data_tmp3,data_tmp5,data_cal_out;
-
reg [4:0] data_tmp4;
-
always@ (posedge clk) begin
-
if(reset) data_tmp_in <= 0;
-
else data_tmp_in <= data_in;
-
end
-
-
//连续乘法,增加逻辑门数量
-
assign data_tmp2 = data_tmp_in * 3;
-
assign data_tmp3 = data_tmp2 * data_tmp_in;
-
-
always@ (posedge clk) begin
-
if(reset) data_tmp4 <= 0;
-
else data_tmp4 <= data_tmp3 * data_tmp2;
-
end
-
-
assign data_tmp5 = data_tmp4 * data_tmp3;
-
assign data_cal_out = data_tmp5;
-
-
always@ (posedge clk) begin
-
if(reset) data_out <= 0;
-
else data_out <= data_cal_out;
-
end
-
-
-
endmodule
RTL原理图如下:

实现后:

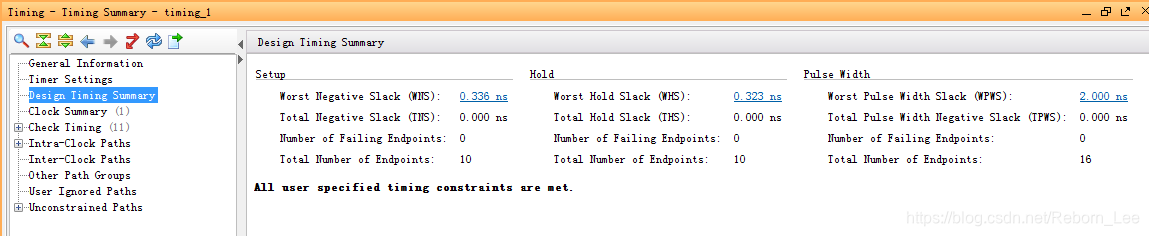
时序没有问题。
(3)用低频时钟
将时序约束的时钟改变如下:
create_clock -name clk -period 40.000 [get_ports clk]
Verilog HDL 代码用最原始的代码。
实现后:


可见时序余量很大了,没有问题。
这里只是一个例子,提供一种参考,时钟频率这里改的太低了。实际应用中,自己斟酌。
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/88657645

- 点赞
- 收藏
- 关注作者
评论(0)