【Verilog HDL 训练】第 13 天(存储器、SRAM)

存储器。
1. rom,ram,flash,ddr,sram,dram,mram..列举并解释一下这些名词。
2. 用verilog实现一个深度为16,位宽8bit的单端口SRAM。搭建一个仿真环境,完成初始化,读取,写入的操作。
3. 接第2题,如果同时对一个地址进行读和写操作,会怎样?实际中应该如何处理?
4. 使用单端口SRAM构造一个双端口同步FIFO。
解答:
1. rom,ram,flash,ddr,sram,dram,mram..列举并解释一下这些名词。
ROM、PROM、EPROM、EEPROM、RAM、SRAM、DRAM的区别
ROM内部的资料是在ROM的制造工序中,在工厂里用特殊的方法被烧录进去的,其中的内容只能读不能改,一旦烧录进去,用户只能验证写入的资料是否正确,不能再作任何修改。如果发现资料有任何错误,则只有舍弃不用,重新订做一份。ROM是在生产线上生产的,由于成本高,一般只用在大批量应用的场合。
由于ROM制造和升级的不便,后来人们发明了PROM(Programmable ROM,可编程ROM)。最初从工厂中制作完成的PROM内部并没有资料,用户可以用专用的编程器将自己的资料写入,但是这种机会只有一次,一旦写入后也无法修改,若是出了错误,已写入的芯片只能报废。PROM的特性和ROM相同,但是其成本比ROM高,而且写入资料的速度比ROM的量产速度要慢,一般只适用于少量需求的场合或是ROM量产前的验证。
EPROM(Erasable Programmable ROM,可擦除可编程ROM)芯片可重复擦除和写入,解决了PROM芯片只能写入一次的弊端。EPROM芯片有一个很明显的特征,在其正面的陶瓷封装上,开有一个玻璃窗口,透过该窗口,可以看到其内部的集成电路,紫外线透过该孔照射内部芯片就可以擦除其内的数据,完成芯片擦除的操作要用到EPROM擦除器。
鉴于EPROM操作的不便,后来出的主板上的BIOS ROM芯片大部分都采用EEPROM(Electrically Erasable Programmable ROM,电可擦除可编程ROM)。EEPROM的擦除不需要借助于其它设备,它是以电子信号来修改其内容的,而且是以Byte为最小修改单位,不必将资料全部洗掉才能写入,彻底摆脱了EPROM Eraser和编程器的束缚。
FLASH ROM则属于真正的单电压芯片,在使用上很类似EPROM,因此,有些书籍上便把FLASH ROM作为EPROM的一种。事实上,二者还是有差别的。FLASH ROM在擦除时,也要执行专用的刷新程序,但是在删除资料时,并非以Byte为基本单位,而是以Sector(又称Block)为最小单位,Sector的大小随厂商的不同而有所不同;只有在写入时,才以Byte为最小单位写入;FLASH ROM芯片的读和写操作都是在单电压下进行,不需跳线,只利用专用程序即可方便地修改其内容;FLASH ROM的存储容量普遍大于EPROM,约为512K到至8M KBit,由于大批量生产,价格也比较合适,很适合用来存放程序码,近年来已逐渐取代了EPROM,广泛用于主板的BIOS ROM,也是CIH攻击的主要目标。
随机访问内存(RAM)相当于PC机上的移动存储,用来存储和保存数据的。在任何时候都可以读写,RAM通常用作操作系统或其他正在运行的程序的临时存储介质(可称作系统内存)。不过,当电源关闭时时RAM不能保留数据,如果需要保存数据,就必须把它们写入到一个长期的存储器中(例如硬盘)。正因为如此,有时也将RAM称作"可变存储器"。RAM内存可以进一步分为静态RAM(SRAM)和动态内存(DRAM)两大类。
静态随机存取存储器(Static Random-Access Memory,SRAM)是随机存取存储器的一种。所谓的“静态”,是指这种存储器只要保持通电,里面储存的数据就可以恒常保持。相对之下,动态随机存取存储器(DRAM)里面所储存的数据就需要周期性地更新。然而,当电力供应停止时,SRAM储存的数据还是会消失(被称为volatile memory),这与在断电后还能储存资料的ROM或闪存是不同的。
SRAM不需要刷新电路即能保存它内部存储的数据。而DRAM(Dynamic Random Access Memory)每隔一段时间,要刷新充电一次,否则内部的数据即会消失,因此SRAM具有较高的性能,但是SRAM也有它的缺点,即它的集成度较低,功耗较DRAM大 ,相同容量的DRAM内存可以设计为较小的体积,但是SRAM却需要很大的体积。同样面积的硅片可以做出更大容量的DRAM,因此SRAM显得更贵。
参考文献:百度百科
2. 用verilog实现一个深度为16,位宽8bit的单端口SRAM。搭建一个仿真环境,完成初始化,读取,写入的操作。
方式一:手写代码
参考:Verilog极简教程
-
module mini_sp_ram #(
-
parameter ADDR_BITS=4
-
)(
-
input clk,
-
input [ 7:0] addr,
-
input [ 7:0] din,
-
input ce,
-
input we,
-
output reg [ 7:0] dout
-
);
-
-
localparam MEM_DEPTH= 1<<ADDR_BITS;
-
-
reg [7:0] mem[MEM_DEPTH-1:0];
-
-
// synopsys_translate_off
-
integer i;
-
initial begin
-
for(i=0; i<MEM_DEPTH;i=i+1) begin
-
mem[i] = 8'h00;
-
end
-
end
-
// synopsys_translate_on
-
-
always @(posedge clk) begin
-
if(ce & we) begin
-
mem[addr] <= din;
-
end
-
end
-
-
always @(posedge clk) begin
-
if(ce && (!we)) begin
-
dout <= mem[addr];
-
end
-
end
-
-
endmodule
这段代码有一段:
// synopsys_translate_off
integer i;
initial begin
for(i=0; i<MEM_DEPTH;i=i+1) begin
mem[i] = 8'h00;
end
end
// synopsys_translate_on
可能会让人疑惑,这能综合吗?
后来特意查了下,原来是我等太为浅薄:
引导语句“// synopsys translate_off”
以前一直没弄懂,以为就是个简单的注释完事,原来还可以用来引导综合过程:
设计者在写设计代码时,有时可能针对仿真写一些语句,这些语句可能是不为DC所接受,也不希望DC接受;设计者如果不对这些语句进行特殊说明,DC读入设计代码时就会产生语法错误。
另一种情况是,设计者在写设计代码,有些设计代码是为专有的对象写的(如公司内部),这些专有的设计代码可能不希望被综合。
Synopsys提供了引导语句,设计者可以使用这些引导语句控制DC综合的对象。
在设计代码中,引导语句“// synopsys translate_off”后直到“// synopsys translate_on”之间的语句被DC忽略。
测试文件(参考:https://halftop.github.io/post/verilog-day13/):
-
`timescale 1ns / 1ps
-
//
-
// Company:
-
// Create Date: 2019/05/16 21:04:57
-
// Design Name:
-
// Module Name: SRAM_tb
-
//
-
-
-
module sram_tb(
-
);
-
-
-
reg [3 : 0] addr;
-
reg [7 : 0]data_in;
-
reg clk;
-
reg we;
-
reg ce;
-
wire [7 : 0] data_out;
-
integer i;
-
-
//clock generation
-
initial begin
-
clk = 0;
-
forever
-
#4 clk = ~clk;
-
end
-
-
-
-
initial begin
-
ce = 1'b0;
-
we = 1'b0;
-
addr = 4'd0;
-
data_in = 8'h00;
-
#20
-
@(negedge clk)//read
-
ce = 1'b1;
-
-
for (i = 0; i<16; i=i+1) begin
-
@(negedge clk)
-
addr = i;
-
end
-
-
@(negedge clk)//write
-
we = 1'b1;
-
for (i = 0; i<16; i=i+1) begin
-
@(negedge clk) begin
-
addr = i;
-
data_in = data_in + 'h01;
-
end
-
end
-
@(negedge clk)//read
-
we = 1'b0;
-
for (i = 0; i<16; i=i+1) begin
-
@(posedge clk)
-
addr = i;
-
end
-
-
@(negedge clk)
-
ce = 1'b0;
-
-
//#100 $finish;
-
#100 $stop;
-
end
-
-
-
-
-
-
sram #( .ADDR_BITS(4) ) u_sram(
-
.clk(clk),
-
.ce(ce),
-
.we(we),
-
.addr(addr),
-
.din(data_in),
-
.dout(data_out)
-
-
);
-
-
-
-
endmodule
行为仿真时序图:
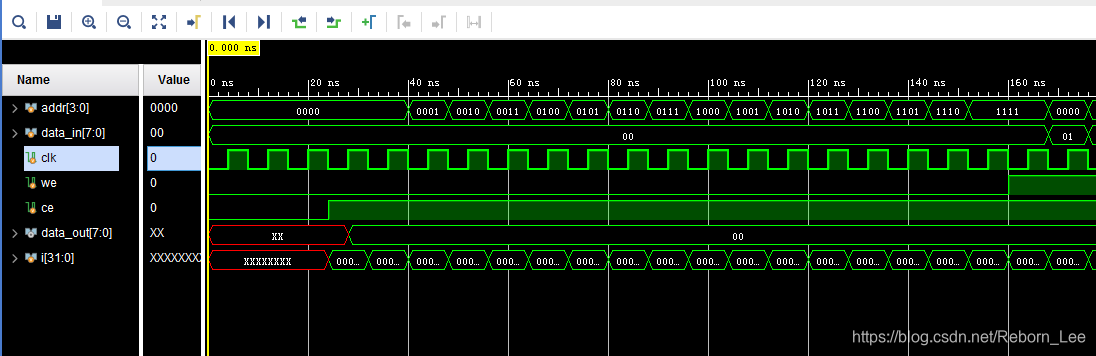
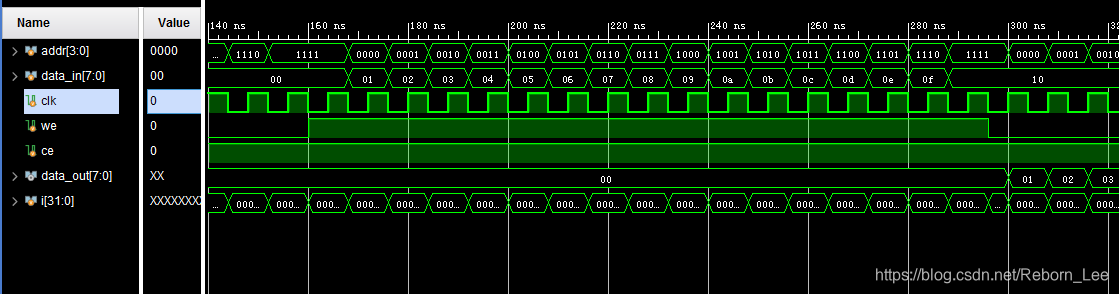
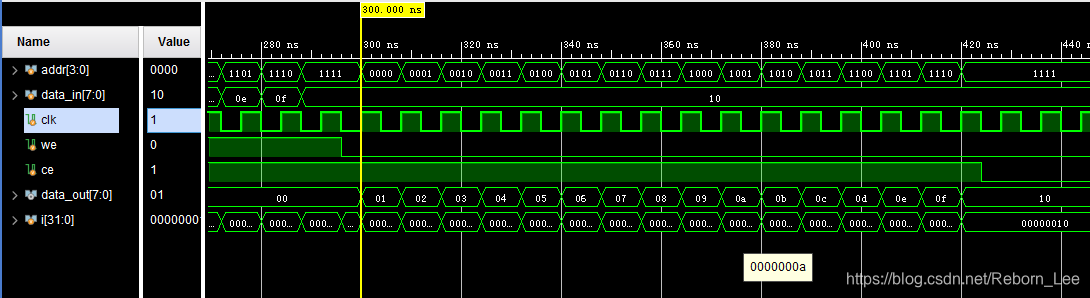
方式二(用FPGA的IP核生成):
可以采用Distributed RAM以及Block RAM生成,这里采用Distributed RAM生成:
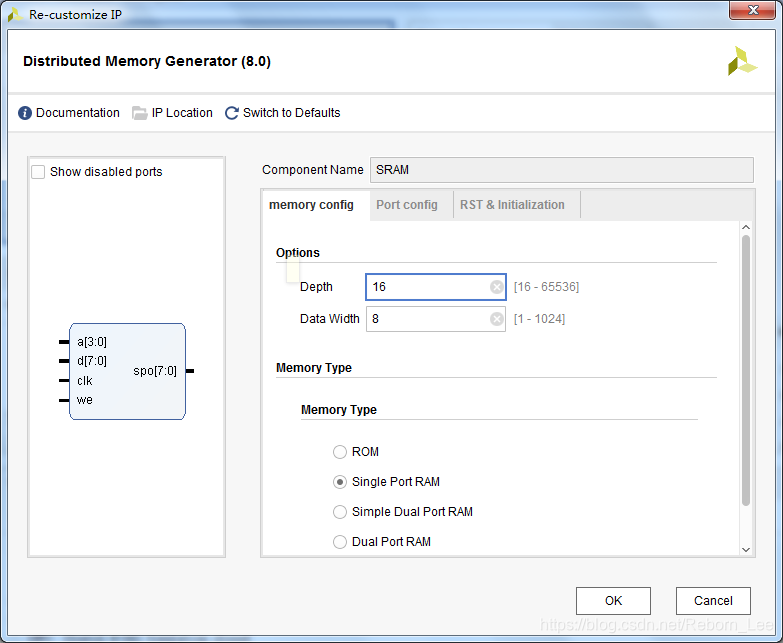
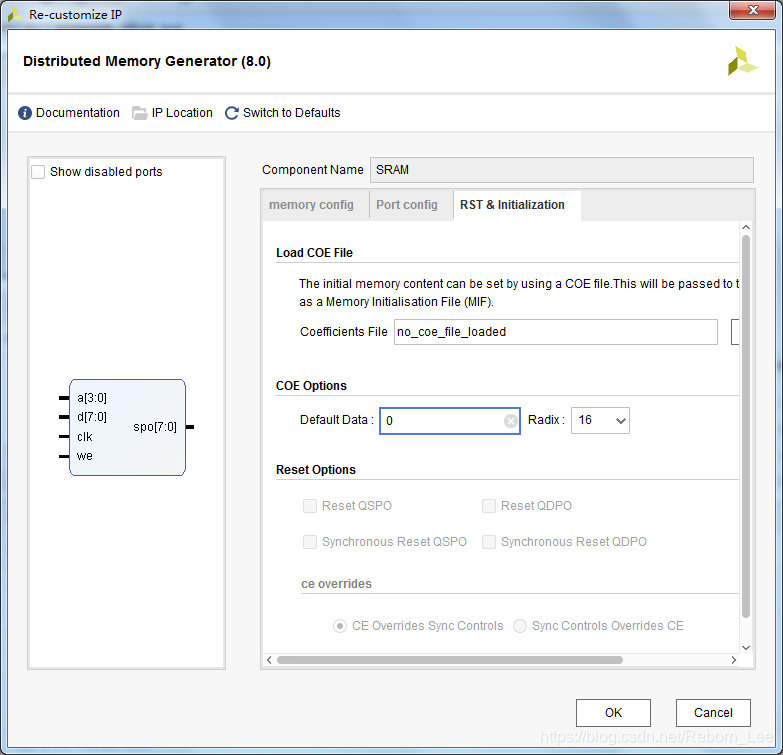
生成的模板:
SRAM your_instance_name (
.a(a), // input wire [3 : 0] a
.d(d), // input wire [7 : 0] d
.clk(clk), // input wire clk
.we(we), // input wire we
.spo(spo) // output wire [7 : 0] spo
);
仿真文件:
-
`timescale 1ns / 1ps
-
//
-
// Company:
-
// Create Date: 2019/05/16 21:04:57
-
// Design Name:
-
// Module Name: SRAM_tb
-
//
-
-
-
module SRAM_tb(
-
);
-
-
-
reg [3 : 0] addr;
-
reg [7 : 0]data_in;
-
reg clk;
-
reg we;
-
wire [7 : 0] data_out;
-
integer i;
-
-
//clock generation
-
initial begin
-
clk = 0;
-
forever
-
#4 clk = ~clk;
-
end
-
-
-
-
initial begin
-
we = 1'b0;
-
addr = 4'd0;
-
data_in = 8'h00;
-
#20
-
@(negedge clk)//read
-
for (i = 0; i<16; i=i+1) begin
-
@(negedge clk)
-
addr = i;
-
end
-
@(negedge clk)//write
-
we = 1'b1;
-
for (i = 0; i<16; i=i+1) begin
-
@(negedge clk) begin
-
addr = i;
-
data_in = data_in + 'h01;
-
end
-
end
-
@(negedge clk)//read
-
we = 1'b0;
-
for (i = 0; i<16; i=i+1) begin
-
@(posedge clk)
-
addr = i;
-
end
-
-
// #100 $finish;
-
#100 $stop;
-
end
-
-
-
-
-
-
SRAM U0_SRAM (
-
.a(addr), // input wire [3 : 0] a
-
.d(data_in), // input wire [7 : 0] d
-
.clk(clk), // input wire clk
-
.we(we), // input wire we
-
.spo(data_out) // output wire [7 : 0] spo
-
);
-
-
-
endmodule
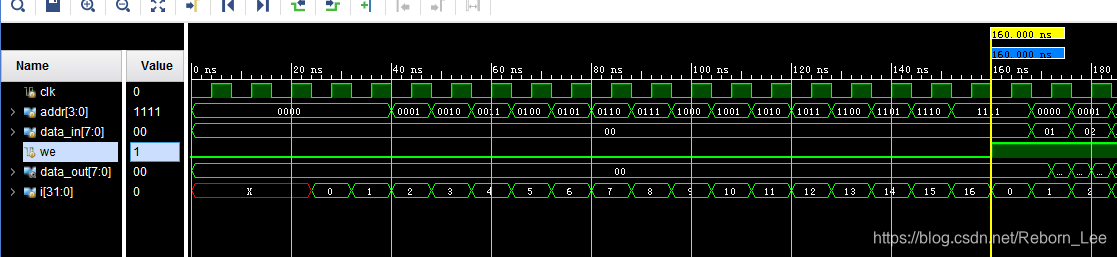
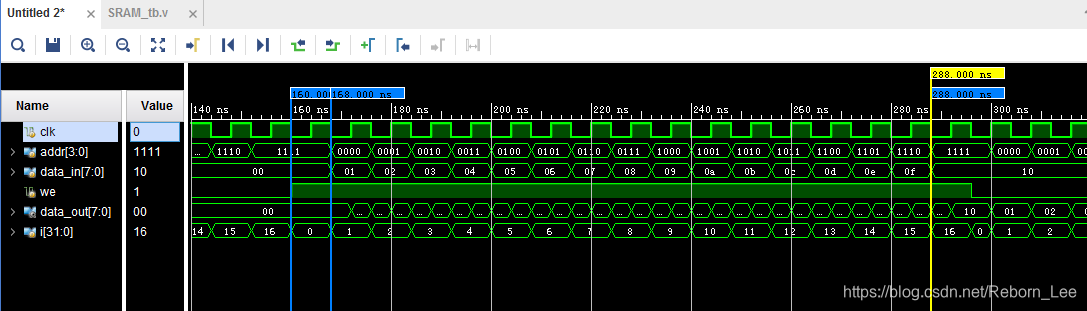
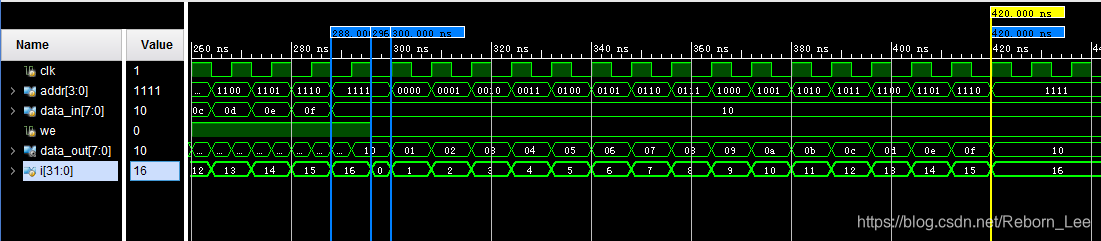
3. 接第2题,如果同时对一个地址进行读和写操作,会怎样?实际中应该如何处理?
单端口SRAM,不能同时读写!
但第4题用单端口SRAM构造一个双端口同步FIFO,可以同时读写。
4. 使用单端口SRAM构造一个双端口同步FIFO。
算了吧,暂时实力不足,时间也不允许这样搞,费点资源搞直接点。
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/90257218

- 点赞
- 收藏
- 关注作者
评论(0)