【FPGA】单端口RAM的设计(异步读、同步写)

【摘要】 上篇博文讲到了:单端口同步读写RAM的设计,那里对RAM的读写采用的是同步的方式,也就是和时钟同步,读写都依赖于时钟。
这篇博文,我们的写依然是同步的,但是读是异步的,所谓的异步就是指不依赖于时钟,这点我们在后面的代码设计中可以清晰的看出。
截取出来:
// Memory Read Block // Read Operation : When we =...
上篇博文讲到了:单端口同步读写RAM的设计,那里对RAM的读写采用的是同步的方式,也就是和时钟同步,读写都依赖于时钟。
这篇博文,我们的写依然是同步的,但是读是异步的,所谓的异步就是指不依赖于时钟,这点我们在后面的代码设计中可以清晰的看出。
截取出来:
// Memory Read Block
// Read Operation : When we = 0, oe = 1, cs = 1
always @ (address or cs or we or oe)
begin : MEM_READ
if (cs && !we && oe) begin
data_out = mem[address];
end
end
可见与时钟无关,是一个组合逻辑。
Verilog HDL描述:
-
`timescale 1ns / 1ps
-
//
-
// Engineer: LJS
-
// Create Date: 2019/05/28 15:21:03
-
// Design Name:
-
// Module Name: ram_sp_ar_sw
-
//
-
-
module ram_sp_ar_sw (
-
clk , // Clock Input
-
address , // Address Input
-
data , // Data bi-directional
-
cs , // Chip Select
-
we , // Write Enable/Read Enable
-
oe // Output Enable
-
);
-
-
parameter DATA_WIDTH = 8 ;
-
parameter ADDR_WIDTH = 8 ;
-
parameter RAM_DEPTH = 1 << ADDR_WIDTH;
-
-
//--------------Input Ports-----------------------
-
input clk ;
-
input [ADDR_WIDTH-1:0] address ;
-
input cs ;
-
input we ;
-
input oe ;
-
-
//--------------Inout Ports-----------------------
-
inout [DATA_WIDTH-1:0] data ;
-
-
//--------------Internal variables----------------
-
reg [DATA_WIDTH-1:0] data_out ;
-
reg [DATA_WIDTH-1:0] mem [0:RAM_DEPTH-1];
-
-
-
-
//initialization
-
-
// synopsys_translate_off
-
integer i;
-
initial begin
-
for(i=0; i < RAM_DEPTH; i = i + 1) begin
-
mem[i] = 8'h00;
-
end
-
end
-
// synopsys_translate_on
-
-
-
//--------------Code Starts Here------------------
-
-
// Tri-State Buffer control
-
// output : When we = 0, oe = 1, cs = 1
-
assign data = (cs && oe && !we) ? data_out : 8'bz;
-
-
// Memory Write Block
-
// Write Operation : When we = 1, cs = 1
-
always @ (posedge clk)
-
begin : MEM_WRITE
-
if ( cs && we ) begin
-
mem[address] = data;
-
end
-
end
-
-
// Memory Read Block
-
// Read Operation : When we = 0, oe = 1, cs = 1
-
always @ (address or cs or we or oe)
-
begin : MEM_READ
-
if (cs && !we && oe) begin
-
data_out = mem[address];
-
end
-
end
-
-
endmodule // End of Module ram_sp_ar_sw
下面进行仿真,仿真的重点是读,我们为了区别它与同步读之间的关系,我们看看给地址的时候,是不是立即就能读出数据,而不必等待时钟的上升沿。
测试文件与上一篇博文测试文件一致,我们需要关注的是读写入数据之后的数据,看看是否是给地址后立即给数据即可:

确实如此,为了形成对比,我们取上一篇博文(同步读写)此时刻的读数据波形图:
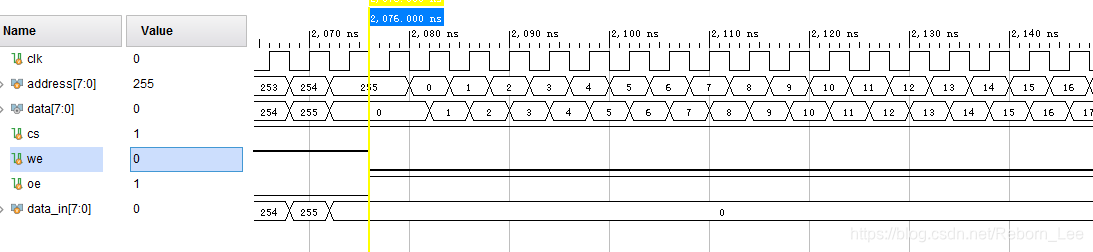
可见,即使给了数据也只能在时钟上升沿读出数据,这就是同步的。
最后还是粘贴出测试文件吧:
-
`timescale 1ns / 1ps
-
//
-
// Create Date: 2019/05/21 16:00:12
-
// Design Name:
-
// Module Name: ram_sp_ar_sw_tb
-
//
-
-
-
module ram_sp_ar_sw_tb(
-
-
);
-
-
reg clk; // Clock Input
-
reg [7 : 0] address; // address Input
-
wire [7 : 0] data; // Data bi-directional
-
reg cs; // Chip Select
-
reg we; // Write Enable/Read Enable
-
reg oe; // Output Enable
-
-
reg [7 : 0] data_in;
-
assign data = (cs && we && !oe) ? data_in : 8'dz;
-
-
integer i;
-
-
initial begin
-
clk = 0;
-
forever
-
#2 clk = ~clk;
-
end
-
-
-
initial begin
-
-
cs = 1'b0;
-
we = 1'b0;
-
oe = 1'b0;
-
address = 8'd0;
-
data_in = 8'h00;
-
#20
-
@(negedge clk) begin//read
-
cs = 1'b1;
-
oe = 1'b1;
-
end
-
-
for (i = 0; i < 256; i = i + 1) begin
-
@(negedge clk)
-
address = i;
-
end
-
-
@(negedge clk) begin//write
-
we = 1'b1;
-
oe = 1'b0;
-
end
-
-
for (i = 0; i < 256; i = i + 1) begin
-
@(negedge clk) begin
-
address = i;
-
//此处如何给输入数据?
-
data_in = data_in + 1;
-
end
-
end
-
-
@(negedge clk) begin//read
-
we = 1'b0;
-
oe = 1'b1;
-
end
-
-
for (i = 0; i < 256; i = i + 1) begin
-
@(negedge clk)
-
address = i;
-
end
-
-
@(negedge clk)
-
cs = 1'b0;
-
//#100 $finish;
-
#100 $stop;
-
-
-
-
-
-
-
end
-
-
-
ram_sp_ar_sw u_ram(
-
.clk(clk) , // Clock Input
-
.address(address) , // address Input
-
.data(data) , // Data bi-directional
-
.cs(cs) , // Chip Select
-
.we(we) , // Write Enable/Read Enable
-
.oe(oe) // Output Enable
-
);
-
-
-
endmodule
最后给出参考文献:
Single Port RAM Asynch Read, Synch Write
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/90640318

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)