FPGA之道(18)FPGA设计的编译过程

前言
这里所谓的FPGA设计的实现过程不是说等价于Implementation,而是整个FPGA设计从设计的描述、编译到最终配置文件形成的一整套过程。
下面根据《FPGA之道》的描述来看这个过程。
FPGA设计的实现过程
在FPGA顶层模块的门级仿真环节之前,甚至更早,编译器就介入到了FPGA项目的开发工作之中。前面介绍的所有环节,主要是为了保证HDL代码以及约束文件的正确性、可行性,但是将HDL代码和约束文件转换为FPGA芯片上实际的数字电路,即FPGA设计的实现这一工作,都是由编译器默默来完成。由此可见,FPGA项目的开发其实是人与编译器协同作战的一个过程。人常说,“不怕狼一样的敌人,只怕猪一样的队友”,既然我们和编译器是战友,那么就要好好进行配合,可是不了解战友的特点和脾性该怎么配合呢?之前,我们主要从自身的角度出发,来介绍FPGA项目的基本开发流程,那么现在通过本章节的学习,让我们来好好认识一下我们的这位战友——编译器,从而为今后长期的协同作战打好基础。
编译概述
虽说编译器的主要工作就是将HDL代码和约束文件转换为FPGA芯片上的实际数字电路,但是这种转换可不是一蹴而就的,事实上这是一个非常复杂且繁琐的过程。凭心而论,在一个FPGA项目的开发中,编译器的工作量远比人类要大得多,如果按照编译流程的先后顺序来看,编译器所做的工作大致可以概括为五大方面:综合、翻译融合、映射、布局布线和配置文件生成, 具体的工作内容我们将在接下来的小节中进行较为详细的介绍。
虽然编译器在FPGA设计的开发过程中功不可没,可是编译器归根到底也是软件,而软件都是人编写的,人又总是会犯错的,因此即使经历了N多个版本的升级,“小强”的生命力仍然相当的顽强,因此编译器软件中都多多少少会有一些BUG存在。除此以外,编译器有时也是比较懒惰、比较笨的,有些时候,它做一定次数的尝试后就会放弃,有时候它给出的结果也并不优秀(虽然它在不断地对设计进行优化)。因此,为了能够让编译器发挥更好的作用,我们能做的就是要尽量编写规范的代码,设计合理的结构等等,这就好比你写的代码像刘翔一样出色,那么即使没有一双好的跑鞋,拿到亚洲冠军也易如反掌。总之作为FPGA开发者来说,能做多好就做多好,这样可以尽可能降低编译器的工作难度,如果再适时地给编译器一些恰当的指导和建议(通过约束),就可以打造出优秀的FPGA设计。
编译流程之综合
综合是编译流程中的第一个环节,编译器在这一环节将我们的FPGA设计转换为门级网表。
综合的输入
综合的输入主要包括HDL代码、综合设置、器件型号等,分别介绍如下:
HDL代码
HDL代码基本上就是全部的待转化的FPGA设计,当然FPGA设计也可以包含一些图形化的文件。说“基本上”,是因为对于一些使用了IP核的FPGA设计来说,如果这些IP核是硬核或者固核,那么它们本身就是门级网表或者资源网表,所以是不会也不需要被综合的。而如果这些IP核是软核,那么它们的表现形式可能也是HDL代码,因此也是综合输入的一部分。
综合设置
综合设置是编译器综合FPGA设计时的指导信息,这对整个综合过程是必不可少的。编译器通常会采用默认的综合设置来进行综合,但有时候我们需要编译器在综合的时候能考虑一下FPGA设计的特点以及一些现实情况,这时就需要人工的去修改综合设置,下面就介绍几种人工干预综合的方法。
-
修改编译策略
一般来说,可选的编译策略包括:speed、area、power optimization、minimum runtime、balance等,我们可以根据项目实际需要来做出选择。各种策略介绍如下:
speed:速度优先策略。表示在综合的时候优先考虑FPGA设计的速度性能,选择该策略可以保证综合出来的门级网表在最终实现为电路的时候更容易工作在较高的时钟频率下。一般在时序分析环节发现最大时钟频率小于需求的时候,可以通过选择该综合策略进行尝试。
area:面积优先策略。表示在综合的时候优先考虑用最少的资源办最大的事情,选择该策略可以保证综合出来的门级网表在最终实现为电路的时候更容易占用较少的硬件资源。一般当发现FPGA设计占用的资源已经超出了所选FPGA芯片的资源数量时,可以通过选择该综合策略进行尝试。
power optimization:功耗最优策略。表示在综合的时候优先考虑减少FPGA芯片的功耗,选择该策略可以保证综合出来的门级网表在最终实现为电路的时候更容易产生较少的热量。一般当发现FPGA芯片在工作中温度过高的时候,可以通过选择该综合策略进行尝试。
minimum runtime:最短时间策略。表示编译器在综合的时候花费最少的时间。编译流程中的任一环节都是需要消耗时间的,我们可以推测,当选用这一策略时,编译器处于最懒的状态。通常如果你的电脑不是太古董的话,不建议选择这一策略。
balance:折中综合策略。表示在综合的时候兼顾考虑速度、面积、功耗等等各面因素,这也是编译器通常默认的综合策略,不过按照这个策略综合出来的门级网表在速度、面积、功耗等几方面都只能做到马马虎虎的水平。尤其是面积和速度这一对水火不容的指标,更是“鱼与熊掌不可兼得”. -
修改一般综合选项
一般综合选项有很多,相比于编译策略,这是稍微细节一些的综合设置,这里列举几个有代表性的综合选项供大家参考:
keep hierarchy:保留层级选项。在编写HDL代码的时候,为了功能强大、思路清晰、便于理解和修改等等原因,我们推荐大家使用层次化、模块化的设计思想来编写HDL,可是FPGA芯片上面的资源并不会按照HDL中的层级结构来进行组织,所以综合后的门级网表也没有必要保留这种层级结构。不过,有些时候,出于一些特殊的目的,我们希望综合出来的网表保留HDL代码中的层级结构,这时候就需要勾选该综合选项。
read core:读核选项。该选项主要是针对IP核的,如果不选中,则把IP当做黑盒来处理,否则在综合的时候可以提取IP核中的一些时间、资源等信息。
synthesis constraints file:综合约束文件选项。无论是综合策略还是综合选项,都太过概括,因为它们都针对全局。有些时候我们需要更具体一点、更灵活一点的综合设置,这时候就可以使用综合约束文件,来自行进行综合约束信息编写。需要注意,除了利用综合约束文件之外,我们还可以通过在HDL代码中嵌入综合约束信息来达到约束综合的效果。 -
修改HDL综合选项
由于HDL代码是FPGA设计的主要载体,因此专门针对HDL代码的综合就有很多的配置选项。这里选择一些比较有代表性的介绍如下:
状态机的相关选项:包括状态机中状态的编码方式选择,例如auto、one-hot、gray等等,默认一般是auto;是否实现安全的状态机,即当出现错误状态时是否会自动跳回到正常状态,默认是no,因为这部分功能需要消耗更多的资源;状态的实现方式,RAM或LUT;等等。
存储器相关选项:包括是否可以通过HDL代码推断并提取出RAM或ROM;用什么资源方式来实现RAM或ROM功能,block或distribute;等等。
复用器相关选项:包括是否可以通过HDL代码推断并提取出MUX;用什么复用器资源来实现MUX;等等。
解码器相关选项:包括是否可以通过HDL代码推断并提取出解码器;是否提取优先级解码器;等等。
寄存器相关选项:包括是否可以通过HDL代码推断并提取出移位寄存器;是否提取逻辑移位寄存器;等等。
其他选项:是否合并级联异或门;是否允许资源共享;是否允许使用DSP单元;等等。 -
修改特殊综合选项
综合过程中,还有一些比较特殊的综合选项。例如:
是否允许在门级网表中添加I/O Buffer,默认是允许的,因为一般来说所综合的代码就是最终需要在FPGA芯片上实现的设计,所以肯定需要借助I/O Buffer来和外界交互,但是如果仅仅是想将当前设计做成一个类似IP核的网表结构,那么肯定是不希望引入I/O Buffer的。
信号的最大扇出控制,即允许内部的一个输出信号所能直接驱动的接收源的个数。对于FPGA芯片来说,可能由于工艺上等等的原因,一般一个内部输出信号的驱动能力是有限的,因此驱动的接收源越多,可能延迟就越大,且由于对地电阻并联的效果,还可能会减弱驱动能力,而通过设置最大扇出的数量,如果FPGA内部有超过这个数量限制的接收源,那么就必须通过内插缓冲器的方法来满足接收源的需要,这样也就间接提高了内部输出信号的驱动能力。
是否允许寄存器复制,等效寄存器合并。这是两个完全相反的操作,但是各有用处,其中,寄存器的复制,对于提高设计的速度以及增强寄存器输出的驱动能力都很有好处;而寄存器的合并,能够有效的帮助我们优化FPGA设计的资源占用量,尤其是当HDL代码中的冗余度比较高时,该选项能够有效的节省FPGA资源。因此默认情况下,这两个选项都是打开的。
寄存器平衡选项。这是一个很强大的功能,它在完全不改变FPGA设计整体功能的前提下,通过重新分配寄存器前后的组合逻辑规模,使设计达到更高的时钟运行速度。寄存器平衡功能又叫retiming,默认情况下为关闭,因为开启该功能会导致编译器工作量急剧增大,从而急剧的增加了综合所消耗的时间。
以上介绍的还只是综合设置的一部分,我们可以看出其中有一部分就是纯粹用于对FPGA设计进行优化的,例如我们刚刚介绍的寄存器平衡功能。其实只要我们根据时序分析的结果对HDL代码进行正确的修改也可以达到近似的效果,这样不仅我们的HDL代码更加完善了,也极大的减轻了编译器的工作量,岂不是一举两得?这就是为什么在【编译概述】小节劝大家不要过分依赖编译器,自己能做多好就做多好。
- 器件型号
器件型号其实是个不太重要的输入,因为综合阶段是实现无关的,还不需要了解太多所使用的FPGA芯片的相关信息。不过在对设计的资源进行评估的时候,倒是需要根据所选器件初步估计出资源的占用率等。
综合的输出
综合的输出主要包括两大部分:RTL门级网表和综合报告,分别介绍如下:
- 1
- RTL门级网表
RTL是Register Transfer Level的简称,因此RTL门级网表又叫寄存器传输级网表。这里的RTL门级网表就是FPGA基本开发流程中FPGA顶层模块的门级仿真环节用到的那个门级网表,它就是FPGA设计对应的与、或、非等门电路单元的表达,由此我们可以推断,如果在编写HDL代码的时候仅仅通过调用最基本的与、或、非等门电路来实现FPGA设计,那么就基本相当于人工的完成了综合的工作。其实事实也基本如此,如果用HDL代码来表示门级网表的话,那么其就相当于只有基本门电路例化语句的HDL代码。
例如,如果我们在HDL代码中描述了一个与逻辑:输出c等于输入a和输入b的逻辑与,那么综合出来的门级网表对应的数字电路形式大致如下:

当然了由于FPGA主要是基于查找表而非逻辑门的,因此从工艺上来说,该门级网表的形式最终可能如下:

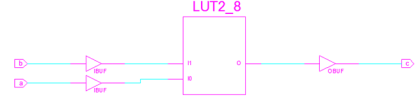
其中LUT2_8的意思是指这是一个两输入的查找表,查找表中存储的数值为“8”,用4位二进制形式来表示,即为“1000”,正好符合两输入与门的真值表。
-
综合报告
综合报告中包含了综合过程中输出的一些关键信息,而其中最主要的内容包括错误信息、警告信息和资源占用量信息。分别介绍如下: -
错误信息
出现了错误信息,表明综合过程失败,比较常见的原因是HDL代码中一些语法类的错误。为了继续FPGA的编译过程,我们必须根据报告内容将它们清除干净。 -
警告信息
出现了警告信息,表明编译器碰到一些不太确定的情况,或者编译器在未经我们允许的情况下进行了一些处理。虽然警告信息并不会导致综合的失败,但是请一定不要忽视,建议的做法是逐条进行确认,看这些警告是否反映了一些设计的隐患。例如,警告信息会给出代码中敏感量表信号缺失的补齐建议,如果不补全敏感量表,那么功能仿真的时候可就痛苦了。 -
资源占用量信息
资源占用量信息反映了综合后门级网表大概需要使用当前FPGA芯片中多少硬件资源,虽然这和最终的资源占用量有稍许差距,但是足以用来作为设计参考,进行设计质量评估。一般来说,当资源占用率小于70%的时候,编译器能比较轻松的将门级网表成功的转换为最终的FPGA数字电路。因此,尽量在综合环节就利用综合报告的资源占用信息来优化FPGA设计的资源占用量,从而为后续编译环节提供便利。
综合的工具
编译器在完成综合工作的时候需要使用综合工具。通常各大FPGA厂商都会在自己的FPGA软件集成开发环境中集成一个综合工具,例如Xilinx公司的XST。还是那句话,样样行不一定样样精,业内有一些专门的公司从事综合工具的开发,例如,Synplicity公司的synplify/synplifyPro、Synopsis公司的FPGA Compiler、MentorGraphic公司的Leonardo Spectrum等。一般说来,对于同样的HDL代码,这些专业的综合工具综合出的门级网表更加的高效,能够使用较少的资源实现较好的速度性能。由于各个综合工具的能力和侧重点有所不同,如果HDL代码书写不规范、结构不合理,很可能导致代码对编译器有所选择,即有的编译器综合出来的门级网表不能正常工作。因此还是那句话,为了减弱HDL代码对编译器的依赖性,在编写HDL代码的时候能做多好就做多好!
编译流程之翻译融合
翻译融合是编译流程中的第二个环节,编译器在这一环节将输入的门级网表和约束信息转换为后续作业工具所能识别的逻辑连接。除此以外,编译器在这一环节还将给出FPGA设计的顶层门级网表,因此,位置约束、时序约束等FPGA设计中的用户约束都必须在翻译融合环节之后才能进行设置。
翻译融合的输入
翻译融合的输入主要包括RTL门级网表、翻译融合设置、器件型号等等,分别介绍如下:
- 1
RTL门级网表
翻译融合环节中,使用到的RTL门级网表可以有两个来源,即综合后门级网表和IP核门级网表,一般来说,FPGA设计中会同时包括这两种门级网表,分别介绍如下:
综合后门级网表
综合后门级网表是综合环节的直接输出,例如,如果我们是用HDL代码来进行FPGA设计,那么综合后门级网表就是编译器将HDL代码综合后的产物。如果该门级网表还伴随有相应的约束文件,也需要一并进行处理。
IP核门级网表
我们在进行FPGA设计的时候,不一定、不太可能、也没有必要完全自己用HDL代码实现所有的功能部分,因为各个相关厂商都会或多或少的提供一些通用或专用、收费或免费的IP核,例如我们最常用FIFO其实就是一个IP核。当我们使用的IP核是硬核或者固核的时候(详细信息请参阅【知己知彼篇->IP核介绍->IP核概述】小节),由于IP核提供的不是HDL代码,而是RTL门级网表和相关约束信息,因此综合环节不会也无法对这类IP核进行任何处理,相关的工作将交由翻译融合环节来完成。通常来说,IP核的门级网表还常常伴有相关的约束文件存在,甚至它们本身就是合二为一的,这个也需要交由翻译融合环节来进行处理。
翻译融合设置
翻译融合设置是编译器对FPGA设计进行翻译融合时的指导信息,这对整个翻译融合过程来说是必不可少的。在翻译融合环节,编译器通常会采用默认的翻译融合设置来进行作业,并且会继承综合环节中所确定的编译策略,不过有时候我们需要编译器在翻译融合的时候能考虑一些实际的情况,这时就需要人工的去修改翻译融合设置,下面就简单介绍几种翻译融合设置选项供大家了解。
Macro Search Path:参考路径设置选项。该选项为编译器添加或指定了网表文件的查找路径,一般当描述IP核功能的网表文件不在工程目录下的时候需要进行手动指定。
Allow Unmatched LOC Constants:允许不匹配引脚约束选项。该选项指定是否允许输入的门级网表的端口名与用户管脚约束中的名称出现不一致。默认情况下该选项是false,如果编译器在翻译融合发现有不一致的情况,将会报告错误从而停止整个编译工作,但是当我们只完成了工程的一部分时,如果想通过后续的一些流程对已完成的工作进行一些测试或调试时,就需要将该选项设置为true。
器件型号
器件型号其实是个不太重要的输入,因为翻译融合阶段也基本上是实现无关的,还不需要了解太多所使用的FPGA芯片的相关信息。需要注意的是,器件型号的输入可以直接从综合环节进行继承,当然了,如果有综合环节的话,之所以这么讲,是因为在某些直接调用门级网表开始进行设计实现的工程中是没有综合环节的。
翻译融合的输出
翻译融合的输出主要包括顶层可识别门级网表、翻译融合报告等等,分别介绍如下:
- 1
顶层可识别门级网表
虽然仍然是门级网表,但是翻译融合环节输出的门级网表具有两个关键字——“顶层”和“可识别”,分别解释如下:
“顶层”关键字是为了突出门级网表文件的覆盖范围,即翻译融合环节输出的门级网表承载的一定是整个FPGA设计的功能。这点可以通过和综合环节的对比来看出,例如,当FPGA设计中使用到了硬核或固核的IP核时,综合环节输出的门级网表是不包括相应IP核的功能的,这个时候,就需要翻译融合环节来将综合后门级网表与IP核门级网表进行融合,从而形成一个能代表整个FPGA设计功能的门级网表,这也是翻译融合环节名称中关键字“融合”的由来。
“可识别”关键字是相对于对FPGA厂商来说的,因为经过综合后的门级网表其实是一个比较通用的门级网表,但是各个FPGA芯片的生产厂商之间谁也不服谁,各有各的想法。这就好比你有一本《如来神掌》,可是想学的人中有的讲日语,有的讲韩语,有的讲印度语,还有一些讲俄语,这可怎么办?那么你只有高薪聘请几个位于牛A与牛C之间的翻译,将这本《如来神掌》分别翻译为《如来雅灭掌》、《如来思密达掌》、《阿三来神掌》以及《如来司机神掌》才行。例如对于Xilinx的编译器,综合后的门级网表中两输入查找表名为LUT2,但是为了让后续流程能够读懂,翻译融合环节将其翻译为X_LUT2,这是一个Xilinx可以识别的基本逻辑单元,这也是为什么综合后仿真模型与翻译融合后仿真模型的门级网表代码中所基于的库是不一样的。上述原因也是翻译融合环节名称中关键字“翻译”的由来。
翻译融合报告
翻译融合环节也会输出一份报告,其中包括了对FPGA设计进行翻译融合过程中的一些详细信息,其中也包括错误信息和警告信息,当出现这两种信息的时候,需要认真处理。
翻译融合工具
由于翻译融合环节是针对具体的FPGA芯片生产厂商的,因此一般来说,用哪个公司的芯片,就用哪个公司的翻译融合工具。通常各个FPGA厂商推出的软件集成开发环境中都会自动集成这样一个工具。
- 1
编译流程之映射
映射是编译流程中的第三个环节,编译器在这一环节将我们的FPGA设计用具体的FPGA芯片中的各种资源来表示。
- 1
映射的输入
映射的输入主要包括顶层门级网表、映射设置、器件型号、位置约束、时序约束、管脚约束等,分别介绍如下:
- 1
顶层可识别门级网表
顶层可识别门级网表是翻译融合环节的直接输出,它是映射环节的主体输入,包含了FPGA设计的全部功能信息与基本逻辑实现。
映射设置
映射设置是编译器映射FPGA设计时的指导信息,这对整个映射过程是必不可少的。在映射环节,编译器通常会采用默认的映射设置来进行作业,并且会继承综合环节中所确定的编译策略,不过有时候我们需要编译器在映射的时候能考虑一些实际的情况,这时就需要人工的去修改映射设置,下面就简单介绍几种映射设置选项供大家了解。
Ignore User Timing Constrains:忽略用户时序约束选项。该选项是指定在映射过程中是否可以忽略用户输入的时序约束信息,一般来说是不应该忽略的,但有时候我们想看一下FPGA设计大致占用芯片中多少资源时,忽略用户的时序约束信息可以加速映射的过程,节约一定的时间。
Trim Unconnected Signals:删除无连接信号选项。一般来说,纵使你在HDL代码中把某一功能描述的多么风起云涌、神乎其神,只要该功能不直接或间接影响任何FPGA物理端口的输出,那么这就是一个无意义的功能,编译器一般会将该功能的所有电路全部删除掉。通常这种做法是非常正确的,但有时候设计只完成了一部分,如果此时想看一下映射后的资源占用情况,为了防止很多功能由于没有连接到输出端口而被优化掉, 就可以通过将该选项设置为false即可。
Generate Detailed Map Report:产生详细映射报告选项。由于映射过程中的细节非常之多,一般编译器只是筛选出其中比较重要的一些信息来组成映射报告,如果需要了解更多、更详细的信息,请选中该选项。
Pack I/O Registers/Latchs into IOB:使用接口资源中的寄存器选项。默认情况下是fasle,如果对接口的时序要求比较高,那么可以设置该选项为true,这样就可以保证从寄存器到FPGA物理管脚之间的延时最短。为了做到更加细节、更加有针对性的这类约束,更为通常的做法是在HDL代码中嵌入相关的约束信息。具体的做法请参阅【程序设计篇->编程思路->代码中的约束信息->HDL中的常用约束示例->寄存器的相关约束】小节。
器件型号
映射环节是与具体的FPGA芯片型号息息相关的,因为它需要利用具体的FPGA芯片中的各种资源来实现顶层可识别门级网表的功能。通常来说,映射环节直接继承前面流程中的器件型号,并根据这个具体的型号完成对FPGA设计的映射工作并给出相关资源占用率报告。
位置约束
在映射的过程中,编译器其实也顺便完成了对FPGA芯片的布局工作,因此位置约束必须在映射开始前就输入。不过这个布局不一定就是最终的布局,但是由于结合了编译策略和相关约束选项,因此布局的效果已经不错了。
时序约束
时序约束主要是针对布局布线环节的,但在映射环节中就必须输入它,因为对于映射环节来说它也有两个不可小视的作用,分别介绍如下:
一、指导映射过程。为什么时序约束会影响到映射工作的行为呢,这又要从三个方面来讲:第一,不同的资源时间延迟参数不一样,例如用DSP实现乘法器就要比用查找表等资源实现的乘法器在速度要快得多,当我们没有强制指定某一个乘法器的实现思路时,编译器就会根据时序约束信息来做出这种实现选择。第二,由于FPGA芯片内部不同的资源所处的位置有所不同,因此你将一个存储功能模块映射为BLOCK RAM还是LUT,也或多或少的限定了最终的布局,从而或多或少的受时序约束的影响。第三,映射的结果本来就跟布局工作息息相关,并且事实上还会顺便完成一次布局工作,而时序约束则是布局过程的一个指导。
二、产生映射后时序分析报告。在【本篇->FPGA设计的时序分析】章节中,我们介绍过时序分析的分类,其中有一类叫做映射后时序分析,如果希望自己的FPGA设计能够顺利通过这类时序分析,必须通过时序约束来约束映射的行为。同时,如果使用编译器自带的时序分析工具,时序约束也是转换为时序要求的依据。
管脚约束
管脚约束是将FPGA设计中的端口对应到FPGA芯片物理管脚的约束,我们可以在编译的最开始就对设计进行管脚约束设置,不过对于综合、翻译融合环节来说管脚约束只是一个可选项,因为这两个环节的工作并不涉及到任何关于具体FPGA芯片的细节,之所以可以在此之前就做管脚约束设置,是因为从HDL代码到各环节门级网表,FPGA设计端口的数目和形式并不会发生改变(名称可能会有略微改变)。
管脚约束主要还是针对映射和布局布线环节的,由于映射环节也会顺便完成一次布局工作,因此使用哪些FPGA的物理管脚对资源布局的位置非常重要,尤其是跟输入输出管脚相关的那些资源。除此以外,不同资源距离物理管脚的距离远近是不同的,例如IOB中的寄存器到FPGA物理管脚的距离远比内部逻辑资源块中的寄存器到FPGA物理管脚的距离要近得多。因此映射的不同会影响到一些资源与FPGA物理管脚间的时间延迟信息,尤其是跟输入输出相关的那些资源。
映射的输出
映射的输出主要包括三大部分:顶层资源位置门级网表、门延时文件和映射报告,分别介绍如下:
- 1
顶层资源位置门级网表
同样是门级网表,但这里的关键字是“顶层”、“资源”和“位置”。“顶层”的意思与顶层可识别门级网表中的“顶层”一样,这里就不再赘述,下面主要讨论一下“资源”和“位置”这两个关键字。
对于FPGA芯片来说“资源”是什么?如果忘了请复习【知己知彼篇->FPGA内部资源介绍】章节。而对于不同的FPGA芯片来说,这些资源的具体形式也不一样。例如有些FPGA芯片中的查找表是3输入的,而另一些是4输入、5输入甚至6输入的。那么针对当前项目所基于的这款具体的FPGA芯片,我们需要将顶层可识别门级网表中的那些功能用FPGA芯片中能够提供的资源形式来表示,这一过程就是映射的过程,而输出即为顶层资源门级网表。例如,针对Xilinx公司的Virtex5系列中的LX110子系列FPGA芯片,顶层可识别门级网表中的X_LUT2被映射成为一个X_LUT6,因为该系列的芯片中没有2输入的查找表资源,只有用一个6输入的查找表资源来自降身价实现了。
接下来来看一下“位置”关键字。前面说过,映射的过程顺便完成了一次不错的布局工作(前提是我们提供了比较完备的时序约束),那么布局后的位置信息是如何体现出来的呢?是直接在门级网表中体现的。例如,如果将上例中的X_LUT6在门级网表中描述翻译成HDL代码的话,以VHDL为例,类似如下所示:
c1 : X_LUT6
generic map(
LOC => “SLICE_X46Y99”,
INIT => X"FFFF000000000000"
)
port map (
ADR0 => VCC,
ADR1 => VCC,
ADR2 => VCC,
ADR3 => VCC,
ADR4 => a_INBUF_B,
ADR5 => b_INBUF_B,
O => c_OBUF_14
);
可以看到,其中第三行的LOC关键字就是对该资源的位置约束,也即布局信息。
门延时文件
既然映射环节输出了顶层资源位置门级网表,那么这些具体的资源门单元的延时信息就可以得到,而这些延时信息的聚类就是映射后时序信息文件,由于映射并不涉及到具体的布线操作,因此该文件也叫门延时文件。可见无论是映射后的时序分析还是时序仿真工作,都是离不开这个门延时文件。需要说明一点,门延时文件中的内容跟FPGA芯片的具体型号息息相关,即使型号相同,也会由于芯片的速度等级不同而不同,具体信息可参阅【知己知彼篇->FPGA产品介绍->FPGA产品的速度等级简介】小节。
映射报告
映射报告中包含了映射过程中输出的一些关键信息,而其中最主要的内容包括错误信息、警告信息和资源占用量等信息,一定要注意阅读。
映射工具
与翻译融合工具类似,映射是完全针对具体的FPGA芯片所做,所以一般来说,用哪个公司的芯片,就用哪个公司的映射工具。通常各个FPGA厂商推出的软件集成开发环境中都会自动集成这样一个工具。
- 1
编译流程之布局布线
布局布线是编译流程中的第四个环节,编译器在这一环节将我们的FPGA设计完全转化为FPGA芯片上的具体数字电路实现。
布局布线的输入
布局布线的输入主要包括顶层资源位置门级网表、布局布线设置、器件型号、管脚约束、时序约束等,分别介绍如下:
顶层资源位置门级网表
顶层资源位置门级网表是映射环节的直接输出,它是布局布线环节的主体输入,包含了FPGA设计的全部功能信息、基本逻辑实现与初步资源布局信息。
布局布线设置
布局布线设置是编译器布局布线FPGA设计时的指导信息,这对整个布局布线过程是必不可少的。在布局布线环节,编译器通常会采用默认的布局布线设置来进行作业,并且会继承综合环节中所确定的编译策略,不过有时候我们需要编译器在布局布线的时候能考虑一些实际的情况,这时就需要人工的去修改布局布线设置,下面就简单介绍一些布局布线设置选项供大家参考。
Place And Route Mode:布局布线模式选项。共有Route Only、Reentry Route、Multi Pass Place And Route三种模式。默认为Route Only模式,表示认为映射环节所做的布局已经可以接受了,因此在布局布线环节只进行布线工作;Reentry Route模式,表示可重入布线模式,即在自动布线开始后可以打断布线器的工作,进行若干手动布线操作,然后再对剩下的部分重新进行自动布线。而Multi Pass Place And Route模式,表示多次布局布线尝试模式,即,如果在当前的布局和设置下无法布出满足时序等指标的连线,则可以尝试重新调整布局后再次布线,其中尝试次数可以由别的选项进行设置。
Place And Route Effort Level:布局布线努力程度选项。共有Standard、Medium、High三个选项,默认为Standard,努力程度最低,如果选择更高级别的努力程度,最终布局布线后的设计能达到时序等约束的要求的可能性就更大,但是布局布线工作所消耗的时间就越长。
Ignore User Timing Constraints:忽略用户约束选项。与在映射中的作用类似,该选项是指定在布局布线过程中是否可以忽略用户输入的时序约束信息。一般来说是不应该忽略的,但有时候我们想看一下FPGA设计大致占用芯片中多少资源时,忽略用户的时序约束信息可以加速布局布线的过程,节约一定的时间。与映射环节相比,布局布线环节得到的资源占用情况更接近或者等于实际情况。
Use Bonded I/Os:使用闲置I/O资源选项。该选项指定是否可以使用闲置的I/O资源来完成某些布局或布线工作,默认为不可以。
Generate Asynchronous Delay Report:产生异步延时报告选项。该选项表示是否在布局布线报告中添加异步延时的分析信息,默认为不产生。
Generate Clock Region Report:产生时钟域报告选项。该选项表示是否在布局布线报告中添加时钟域的分析信息,默认为不产生。
Generate Post-Place And Route Static Timing Report:产生布局布线后时序分析报告选项。该选项表示是否在布局布线报告中添加布局布线后的静态时序分析信息,默认为产生。
Generate Post-Place And Route Simulation Model:产生布局布线后仿真模型选项。该选项表示是否生成布局布线后的仿真模型,默认为不产生。
Number Of Place And Route Iterations:布局布线器尝试次数选项。该选项针对布局布线模式中的Multi Pass Place And Route模式,表示尝试次数。
Number Of Results To Save:保存结果的次数选项。每次布局布线成功后都会产生一个结果文件,如果今后修改了设计,重新布局布线后则会产生一个新的结果文件,而本选项就是允许编译器保存之前编译成功结果的个数。例如该选项为3,则表示编译器最多可以保存最近三次成功的布局布线结果。
Power Reduction:功耗优化选项。该选项表示在布局布线的时候需要考虑减少最终电路的功耗,不过所谓“鱼与熊掌不可兼得也”,这会对布局布线有不利影响,因此默认不选中。
器件型号
布局布线环节是与具体的FPGA芯片型号息息相关的,因为它需要利用具体的FPGA芯片中的各种资源(包括布线资源)来实现顶层资源门级网表的功能。通常来说,布局布线环节直接继承前面流程中的器件型号,并根据这个具体的型号完成对FPGA设计的布局布线工作并给出最终的资源占用率等报告。
管脚约束
管脚约束就是一种布局信息,而布局信息又直接影响布线操作,因此管脚约束对于布局布线的工作来说非常重要。
时序约束
时序约束是主要针对布局布线环节的,因为布局从宏观上决定时间延迟参数(离得远的连线延迟肯定大),而布线则从细节上确定时间延迟参数(离得近的连线延迟不一定小)。我们可以用示波器的粗调与微调旋钮来类比布局与布线对时间延迟参数的影响(虽然并不完全一样),从而更加形象的理解布局布线与时间延迟的关系。
最后多说一句,虽然时序约束对于映射与布局布线环节的工作非常重要,但是它并不是一个不可或缺的输入选项,通常建议务必为每个FPGA设计编写完备的时序约束,因为没有时序约束就相当于时序约束极限松,因此布局器和布线器随便怎么操作都能满足要求,试问这么随意得到的FPGA片上电路,其性能怎么能够保证?
布局布线的输出
布局布线的输出主要包括四个方面:最终资源位置门级网表、布线信息、延迟文件和布局布线报告,分别介绍如下:
最终资源位置门级网表
同样是门级网表,但这里的关键字是“最终”、“资源”和“位置”。“资源”和“位置”的意思与顶层资源位置门级网表中的“资源”、“位置”关键字一样,这里就不再赘述,下面主要讨论一下“最终”这个关键字。
“最终”的必然是“顶层”的,因为如果不是“顶层”的,那么说明FPGA设计并没有实现完毕,也就不可能是“最终”的。但是顶层资源位置门级网表仅仅是映射环节的输出,由于在布局布线环节可能重新修改布局(当处于Multi Pass Place And Route模式),因此顶层资源位置门级网表中的位置信息未必等于布局布线后的门级网表中的位置信息。而经历了布局布线环节后,FPGA芯片中的电路就完全固定了,因此该环节的输出叫做最终资源位置门级网表。
布线信息
门级网表只能描述各个FPGA内部资源之间的连接关系,并不能反映出具体布线的方式与方法。这就好比画电路板时,分为原理图绘制和PCB绘制两个环节,最终资源位置门级网表相当于具有位置信息的电路板原理图,布线信息相当于没有电子器件的电路板PCB。因此要想完好表述FPGA片上电路,最终资源位置门级网表与布线信息缺一不可。
延时文件
既然布局布线环节输出了最终资源门级网表和布线信息,那么门延迟和线延迟的信息我们就都得到了,而这些信息的的聚类就是延时文件。延时文件是对FPGA设计进行布局布线后时序分析与时序仿真的前提条件,它与映射环节输出的门延时文件一样,内容跟FPGA芯片的具体型号息息相关,即使型号相同,也会由于芯片的速度等级不同而不同。
布局布线报告
布局布线报告中包含了布局布线过程中输出的一些关键信息,而其中最主要的内容包括错误信息、警告信息、时序分析信息和资源占用量等信息,一定要注意阅读和分析。
布局布线工具
与翻译融合工具类似,布局布线是完全针对具体的FPGA芯片所做,所以一般来说,用哪个公司的芯片,就用哪个公司的布局布线工具。通常各个FPGA厂商推出的软件集成开发环境中都会自动集成这样一个工具。布局布线工具又可细分为布局器和布线器,其中布局器可用于映射与布局布线环节,而布线器主要用于布局布线环节。
编译流程之配置生成
配置生成是编译流程中的第五个环节,也是最后一个环节,编译器在这一环节将我们的FPGA设计转化FPGA芯片的配置文件。
配置生成的输入
配置生成的输入主要包括最终资源位置门级网表、布线信息、配置生成设置、器件型号等,分别介绍如下:
最终资源位置门级网表
最终资源位置门级网表是布局布线环节的直接输出,主要包含了FPGA设计的资源信息以及资源位置信息。
布线信息
布线信息也是布局布线环节的直接输出,主要包含了最终资源位置门级网表中各个资源之间的具体连线关系与方式。
配置生成设置
配置生成设置是编译器生成FPGA配置文件时的指导信息,这对整个配置生成过程是必不可少的。在配置生成环节,建议采用默认的配置生成设置来进行作业,当然了,如果仅仅是想添加或删除产生配置文件的种类,可以通过简单勾选或去除一些配置生成的选项来实现,而对于一些像配置引脚的电阻上拉或下拉特性来说,还是不要轻易修改。
器件型号
配置生成环节是与具体的FPGA芯片型号息息相关的,因为通过载入配置文件就可以在FPGA芯片内部还原出布局布线环节给出的电路结构,从而实现FPGA设计对应的功能。通常来说,配置生成环节直接继承前面流程中的器件型号,并根据这个具体的型号完成对FPGA设计的配置生成工作。
配置生成的输出
配置生成的输出主要包括两大部分:配置文件和配置生成报告,分别介绍入下:
配置文件
同一个FPGA设计的配置文件一般不止一种,这是由FPGA芯片配置方法的多样化而决定的,这其中包括配置接口的多样化与配置方法的多样化。例如:Altera公司的FPGA产品,使用JTAG接口进行配置的时候使用的是后缀名为*.sof的配置文件,而使用外部配置芯片的时候使用后缀名为*.pof的配置文件;Xilinx公司的FPGA产品,使用FLASH作为配置芯片时,使用后缀名为*.bit的配置文件,而使用PROM作为配置芯片的时候,使用后缀名为*.mcs的配置文件,等等。
需要说明的一点是,对于某个固定的FPGA芯片型号来说,它的同一种配置文件的大小是固定的,无论FPGA设计的功能复杂还是简单。这是因为我们可以将FPGA内部的所有资源信息(例如LUT的初始状态)和布线信息看做是一个个不同的开关,我们可以通过控制开关的通断来让FPGA中的资源实现不同的功能或结构,因此,无论FPGA设计的功能如何,FPGA芯片中的开关总数是不会改变的,而配置文件就是用来描述各个开关的通断状态的,所以配置文件的大小仅仅跟FPGA芯片的型号有关,而与FPGA设计本身无关。之所以不同配置方法或配置接口的配置文件大小不一样,是因为它们需要通过不同的表现形式让使用它们的不同接口或通信协议能够理解它们,这就和同样的功能用VHDL描述和用Verilog描述最终的文件大小是不同的一样。类似的例子还有《如来思密达掌》、《阿三来神掌》都是《如来神掌》的译本,可是题目的字数却不一样。
配置生成报告
配置生成报告中包含了配置生成过程中输出的一些信息,例如都生成了哪些类型的配置文件。通常来说能够顺利通过布局布线环节的FPGA设计不会在这一步出现错误和警告信息,因此该报告的重要性没有前几个环节报告的重要性大。
配置生成工具
与翻译融合工具类似,配置生成是完全针对具体的FPGA芯片所做,所以一般来说,用哪个公司的芯片,就用哪个公司的配置生成工具。通常各个FPGA厂商推出的软件集成开发环境中都会自动集成这样一个工具。
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/104257344

- 点赞
- 收藏
- 关注作者
评论(0)