高速串行总线设计基础(五)揭秘SERDES高速面纱之多相数据提取电路与线路编码方案

前言
SERDES可以工作在多吉比特的速率,同样作为串行总线的SPI却常常在十兆或数十兆比特的速率,为何差别这么大呢?SERDES的特别之处在哪里?用了什么技术?这里来揭秘SERDES高速面纱!
多相数据提取电路
采取多相位时钟处理数据的技术应用十分广泛,例如ADC芯片:EV10AQ190A,它的单通道模式就利用了多相位时钟技术对模拟信号进行采样:
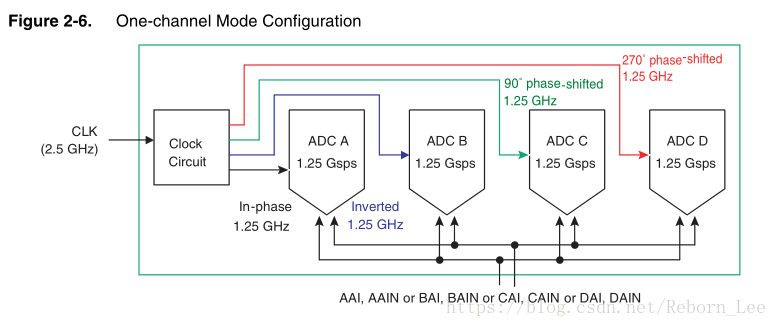
这时多相位时钟技术运用到了ADC电路设计中,可以实现使用数据流的4倍速率提升。
解读ADC采样芯片(EV10AQ190A)的工作模式(单通道模式)
如果将这种技术运用到吉比特收发器中呢?当然也可以大展身手,如下:
如下多相数据提取电路:
如果我们有比特率为x的输入串行流,则可以通过使用慢速时钟的多个相位来以x / 4的时钟恢复流。输入流被定向到四个触发器,每个触发器在时钟的不同相位(0、90、180和270)下运行。
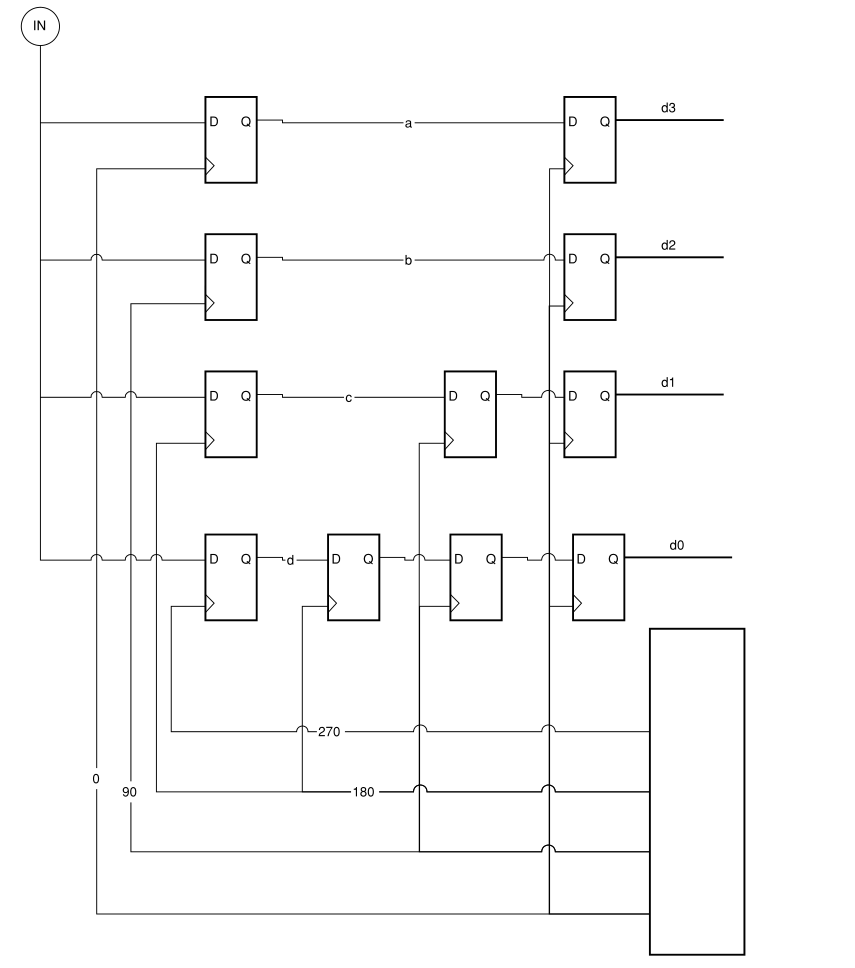
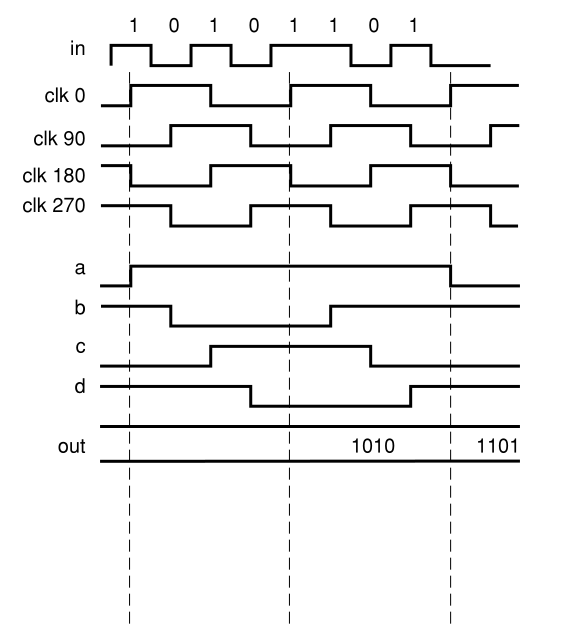
然后,每个触发器送入一个由下一个最低相位时钟的触发器, 直到以零相时钟开始计时。这就将输入的数据流反串成一个4位字,以输入数据流的1/4时钟速率运行。
在前面的示例中,将相位对齐,时钟恰好是输入流速率的1/4。怎么发生的?我们必须锁定传入的串行数据流。我们可以使用经典的锁相环(PLL)来完成此操作,但这将需要全速率时钟并达到目的。高速SERDES的最大进步之一涉及用于时钟和数据恢复的PLL。普通PLL需要以数据速度运行的时钟,但是可以使用几种技术来避免这种需求,包括分数速率鉴相器,多相PLL,并行采样和过采样数据恢复。
线路编码方案
所谓的线路编码方案就是高速串行总线技术中常用的8B/10B编码或者64B/66B技术,关于8B/10B编码技术的具体细节我会在本系列的后续部分给出单独一篇!
下图时Xilinx的Transceiver定制页面的某一页,可见,8b/10b 编码是 Xilinx 的众多(几乎所有)高速串行总线协议中,采用的一种保持串行数据DC平衡的技术。
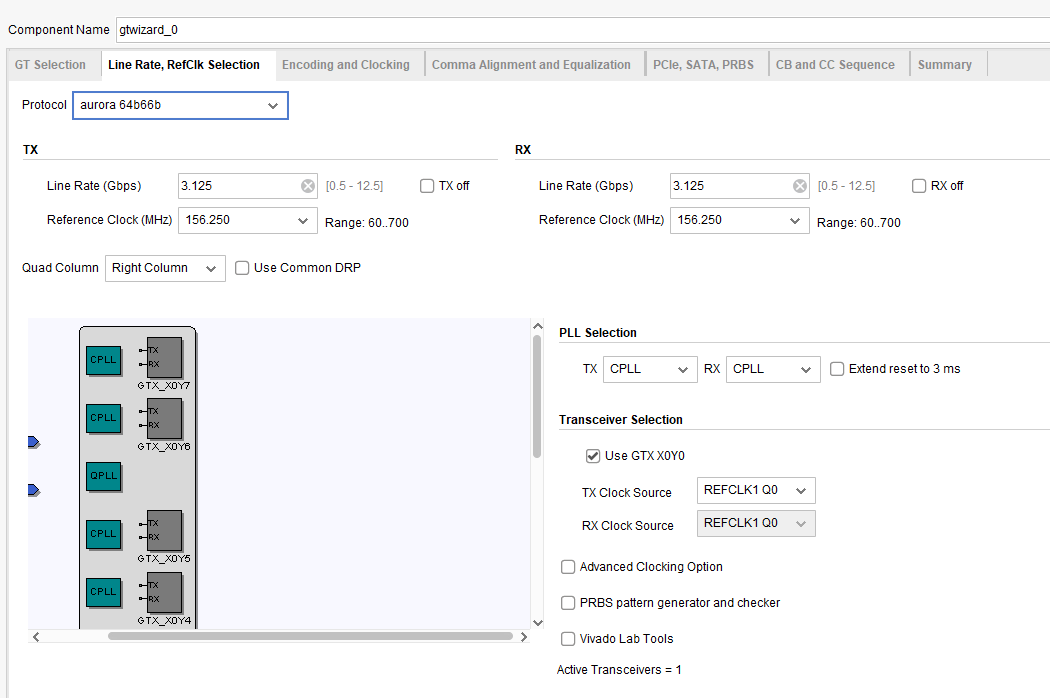
线路编码方案将原始数据修改成接收器可以接受的形式。具体而言,数据编码方案确保有足够的跳变以使时钟恢复电路工作。它们提供了一种将数据对齐成字的方法,并且在串行链路上具有良好的直流(DC)平衡。
可选地,线路编码方案还可提供时钟校正,块同步和通道绑定以及将带宽划分为子通道的实现。有两种主要的线路编码方案-值查找方案和自修改流或加扰器。
8B/10B编解码
8b / 10b编码方案是由IBM开发的,已经被广泛采用。它是Infiniband,千兆位以太网,光纤通道和10千兆位以太网的XAUI接口中使用的编码方案。它是一种值查找类型的编码方案,其中将8位字转换为10位符号。这些符号确保了时钟恢复的跳变次数。
表3-1给出了一些8位值的示例,这些值会导致长时间运行而不会发生跳变。 8b / 10b允许将12个特殊字符解码为12个通常称为K字符的控制字符。后面会更详细地介绍K个字符,但首先让我们研究8b / 10b如何确保良好的DC平衡。

运行差异(Running Disparity)
通过一种称为运行差异的方法,可以在8b / 10b中实现DC平衡。实现DC平衡的最简单方法是仅允许具有相同数目的1和0的符号,但这将限制符号的数量。
相反,8b/10b使用两个不同的符号分配给每个数据值。在大多数情况下,其中一个符号有6个0和4个1,另一个符号有4个0和6个1。监视1和0的总数,并根据需要选择下一个符号,使线路恢复直流平衡。这两个符号通常被称为+和-符号。
符号示例见下表。

关于此字符的全部编码,可参考UG476的附录C。
运行差异的另外一个好处是,接收器可以监控运行差异,并检测到传入流中发生了错误,因为违反了运行差异规则。
控制字符
刚才的表格中的以D开头的字符成为数据字符,它代表的是数据信息;其实不只有数据信息,高速串行总线传输的还有控制字符,如下:
下表列出了12个特殊符号的编码,这些符号称为控制字符或K字符。
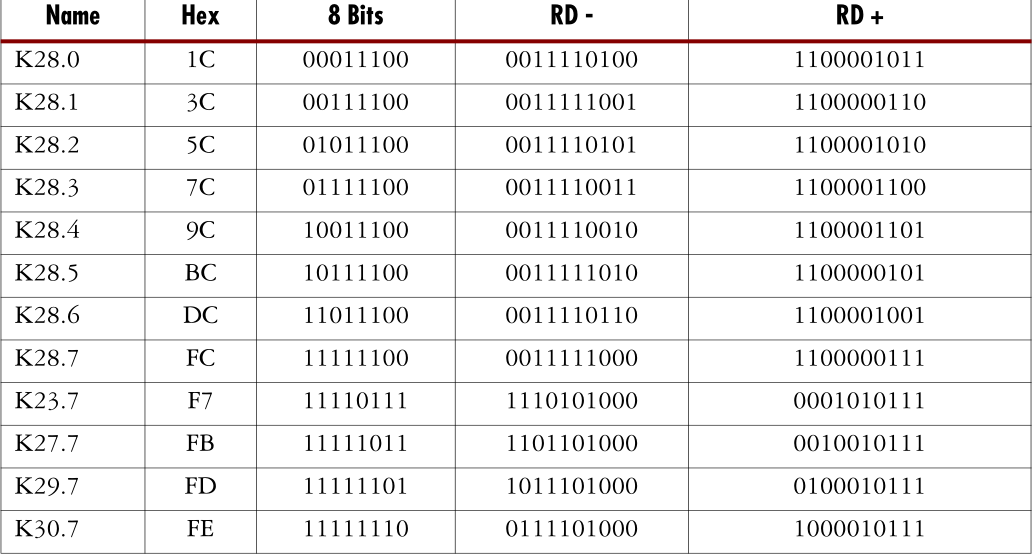
这些控制字符用于对齐,控制,并将带宽划分为子通道。
Comma 检测
Comma Detection可以直译为逗号检测,它是指定为对齐序列的一两个符号,可以看作是一个标志。
数据对齐是解串器(串并转换)的重要功能。下图表示串行流中的有效8b / 10b数据。
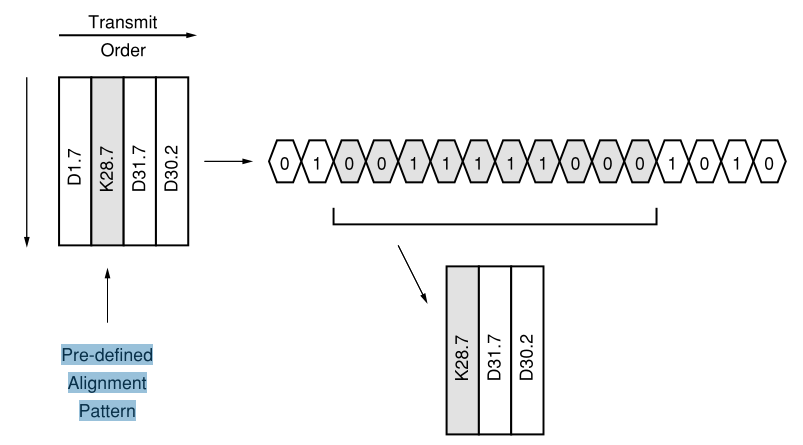
我们怎么知道符号的边界在哪里?符号是由逗号划定的。在这里,逗号是指定为逗号或对齐序列的一个或两个符号。这个序列通常在收发器中可设置,但在某些情况下,它可能是预定义的。
接收器扫描传入的数据流以查找指定的位序列。如果找到序列,则解串器将重置单词边界以匹配检测到的逗号序列。这是连续扫描。进行对齐后,检测到的所有后续逗号都应找到已设置的对齐方式。当然,逗号序列在序列的任何组合内必须是唯一的。
例如,如果我们对逗号使用信号符号c,则必须确定没有有序的符号xy集包含位序列c(确保唯一,作为仅仅为编)。使用预定义的协议不是问题,因为已经定义了逗号字符。
通常使用K字符的一个或多个特殊子集。该子集由K28.1,K28.5和K28.7组成,它们的前7位均为1100000。仅在这些字符中找到此模式;没有有序的数据集,也没有其他K字符包含此序列。因此,它是对齐使用的理想选择。在构建自定义协议的情况下,最安全,最常见的解决方案是从已知协议中“借用”序列。千兆以太网使用K28.5作为逗号。因此,即使在技术上还有其他选择,它也通常被称为逗号符号。
加扰技术
由于8B/10B编码技术,会添加额外的bit对数据进行编码,从而增加了带宽的开销;例如要获得2.5Gb的带宽,需要3.125Gbps的线速率。
加扰技术可以轻松解决时钟转换和直流偏置问题,而无需增加带宽。
什么是加扰技术呢?
即一种对数据进行重新排序或编码的方法,以使其看起来是随机的,但可以被加密。
加扰是一种对数据进行重新排序或编码的方法,以使其看起来是随机的,但仍然可以不加扰。我们希望随机化器可以打破长期的零和一。显然,我们希望解扰器对比特进行解扰,而无需任何特殊的对齐信息。此特性称为自同步编码。
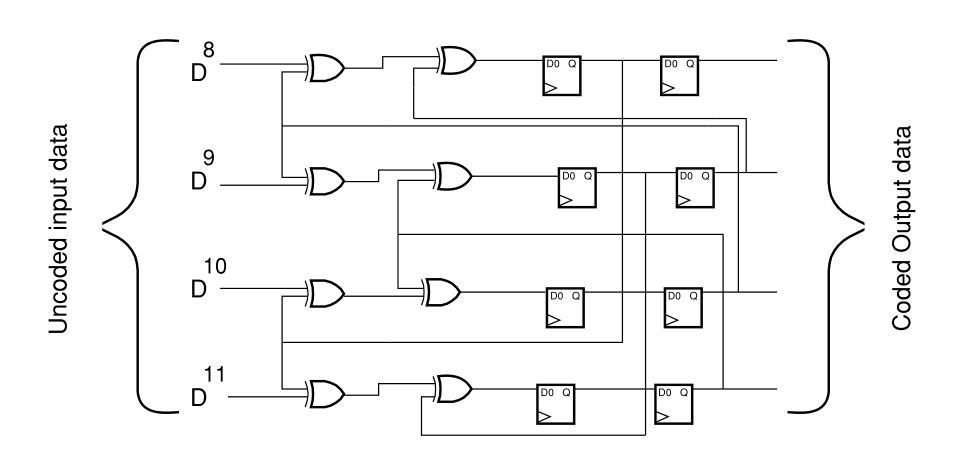
一个简单的加扰器由一系列触发器组成,这些触发器被安排用来移动数据流。大多数触发器仅馈送下一位,但有时触发器将与流中的较旧位进行异或运算。下图显示了此概念。
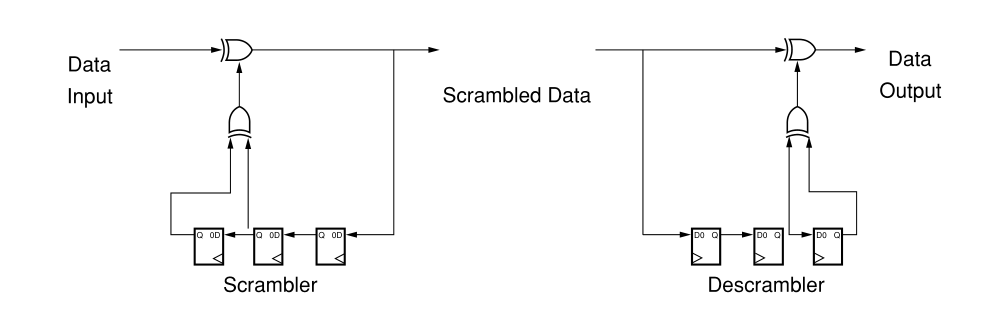
由于涉及到数学问题,加扰方法通常被称为多项式。多项式是根据扰频特性来选择的,例如它们创建的数据流有多随机,以及它们能多好地分解零和一的长数据流。它们还必须避免产生长的运行长度。
希望增加触发器的时钟速率。但是,根本无法获得诸如10 Gb / s的高速率。但是,有一种方法可以将任何串行系数并行为y大小的并行字,以加快处理过程,如图所示。
加扰技术虽然很好,不会增加带宽的开销,但8b/10b等线路编码方案所提供的其他任务是扰码所不能提供的。例如:
- 字对齐
- 时钟校正机制
- 通道绑定机制
- 子通道创建
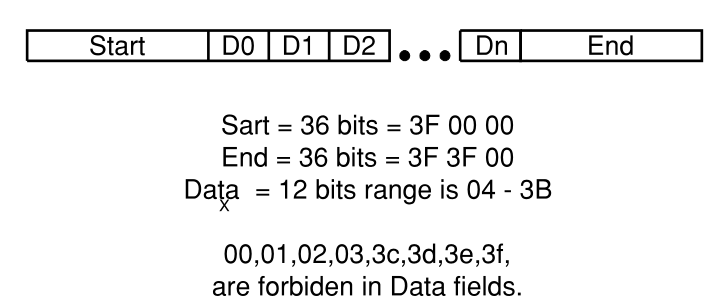
尽管在某些情况下可能不需要最后三个,但是始终需要字对齐。如果将加扰用作行编码方法,则必须使用另一种方法进行字对齐。例如,我们可以从数据或有效负载的允许值中排除某些值。然后,我们可以使用这些不允许的值创建在序列的数据部分中不会出现的位流(图3-11)。
到这里,SERDES为何如此之快的话题还没结束,内容较多,留到下一篇再说吧。
参考文献
解读ADC采样芯片(EV10AQ190A)的工作模式(单通道模式)
注:本系列博文首发自:https://www.ebaina.com/articles/140000005095
文章来源: reborn.blog.csdn.net,作者:李锐博恩,版权归原作者所有,如需转载,请联系作者。
原文链接:reborn.blog.csdn.net/article/details/110730255

- 点赞
- 收藏
- 关注作者
评论(0)