机器学习8-特征工程

前言
传统编程的关注点是代码。在机器学习项目中,关注点变成了特征表示;即,开发者通过添加和改善特征来调整模型。
特征工程是指将原始数据转换为特征矢量;进行特征工程预计需要大量时间。
一、将原始数据映射到特征
下图中左侧表示来自输入数据源的原始数据,右侧表示特征矢量,也就是组成数据集中样本的浮点值集。
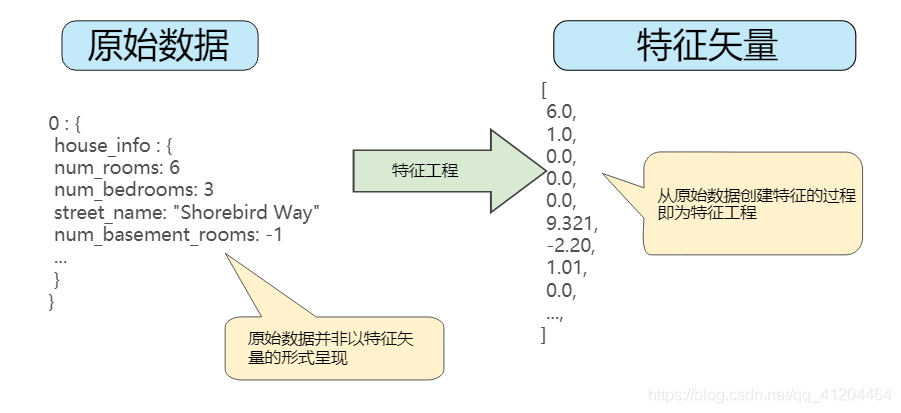
![]()
特征工程将原始数据映射到机器学习特征。
二、映射数值
整数和浮点数据不需要特殊编码,因为它们可以与数字权重相乘。
下图中,将原始整数值6转换为特征值6.0并没有多大的意义。
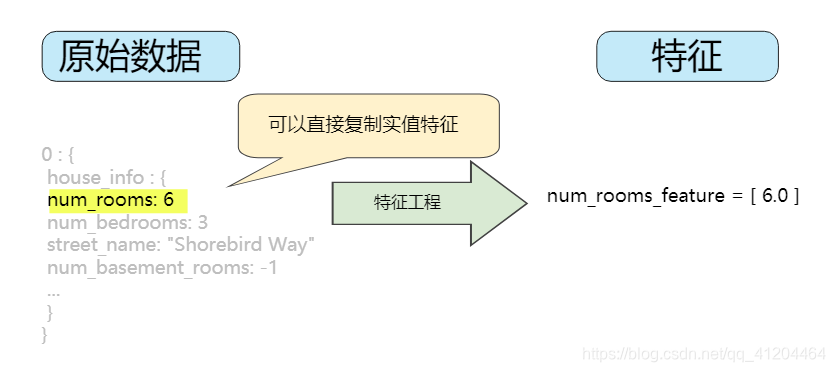
![]()
三、映射分类值
分类特征具有一组离散的可能值。例如,可能有一个名为street_name的特征,其中的选项包括:
{'Charleston Road', 'North Shoreline Boulevard', 'Shorebird Way', 'Rengstorff Avenue'}由于模型不能将字符串与学习到的权重相乘,因此我们使用特征工程将字符串转为数字值。
实现思路
可以定义一个从特征值(称为可能值的词汇表)到整数的映射。
世界上的每条街道并非都会出现在我们的数据集中,因此我们可以将所有其他街道分组为一个全部包罗的“其他”类别,称为OOV分桶(词汇表外)。
实现过程
通过上面的方法,我们可以按照以下方式将街道名称映射到数字:
- 将Charleston Road 映射到0
- 将North Shoreline Boulevard 映射到1
- 将Shorebird Way 映射到2
- 将Rengstorff Avenue 映射到3
- 将所有其他街道(OOV)映射到4
但是,如果我们将这些索引数字直接纳入到模型中,将会造成一些限制:
1)我们将学习适用于所有街道的单一权重。
例如,如果我们学习到street_name 的权重为6,那么对于Charleston Road,将其乘以0;对于North Shoreline Boulevard 则乘以1;对于Shorebird Way 则乘以2,依次类推。
以某个使用street_name 作为特征来预测房价的模型为例。根据街道名称对房价进行线性调整的可能性不大,此外,这些假设我们已经根据平均房价对街道怕徐。
我们的模型需要灵活地为每条街道学习不同的权重,这些权重将添加到使用其他特征估算的房价中。
2)我们没有将street_name 可能有多个值的情况考虑在内。例如,许多房屋位于两条街道的拐角处,因此如果模型包括单个索引,则无法再street_name 值中对该信息进行编码。
去除以上两个限制,我们可以为模型中的每个分类特征创建一个二元向量来表示这些值:
- 对于使用样本的值,将相应向量元素设为1.
- 将所有其他元素设为0;
该向量的长度等于词汇表中的元素数。当只有一个值为1 时,这种表示法称为独热编码;当有多个值为1时,这种表示法称为多热编码。
下图是通过独热编码映射街道地址,为街道Shorebird Way 的独热编码。
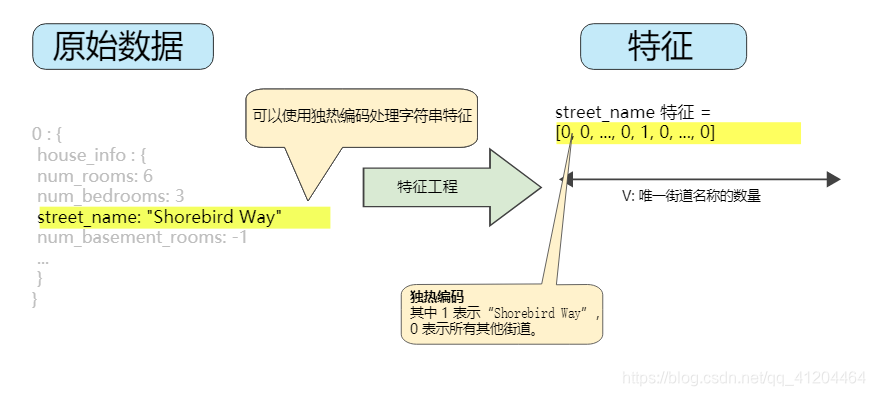
![]()
在此二元矢量中,代表Shorebird Way 的元素的值为1,而代表所有其他街道的元素的值为0.
小结
该方法能够有效为每个特征值创建布尔变量。采用这种方法时,如果房屋位于Shorebird Way街道上,则只有Shorebird Way的二元值为1.因此,该模型仅使用Shorebird Way 的权重。
如果房屋位于两条街道的拐角处,则将两个二元值设为1,并且模型将使用它们各自的权重。
四、稀疏表示法
背景
假设数据集中有100万个不同的街道名称,您希望将其包含为street_name 的值。
如果直接创建一个包含100万个元素的二元向量,其中只有1或2个元素为true,则是一种非常低效的表示法,在处理这些向量时会占用大量的存储空间并耗费很长的计算时间。
简介
在这种情况下,一种常用的方法是使用稀疏表示法,其中仅存储非零值。在稀疏表示法中,仍然为每个特征值学习独立的模型权重。
五、良好特征的特点
我们探索了将原始数据映射到适合特征矢量的方法,但这只是工作的一部分。然后需要探索什么样的值才算这些特征矢量中良好的特征。
- 避免很少实用的离散特征值
- 最好具有清晰明确的含义
- 实际数据内不要掺入特殊值
- 考虑上游不稳定性
5.1)避免很少使用的离散特征值
良好的特征值应该在数据集中出现大约5次以上。这样一来,模型就可以学习该特征值与标签是如何关联的。大量离散值相同的样本可让模型有机会了解不同设置中的特征,从而判断何时可以对标签很好地做出预测。例如,house_type特征包含大量样本,其中它的值为victorian:
house_type: victorian
如果某个特征值仅出现一次火灾很少出现,则模型就无法根据该特征进行预测。例如,unique_house_id 就不适合作为特征,因为每个值只使用一次,模型无法从中学习任何规律:
unique_house_id: 8SK982ZZ1242Z
5.2)最好具有清晰明确的含义
每个特征对于项目中的任何人,来说都应该具有清晰明确的含义。例如,房龄适合作为特征,可立即识别是以年为单位的房龄:house_age: 27
相反,对于一些特征值的含义,除了创建它的工程师,其他人恐怕辨识不出:house_age: 851472000
在某些情况下,混乱的数据会导致含义不清晰的值。例如,user_age的来源没有检查值是正确:user_age: 277
5.3)实际数据内不要掺入特殊值
良好的浮点特征不包含超出范围的异常断点或特征的值。例如,假设一个特征具有0到1 之间的浮点值。那么,如下值是可以接受的:
quality_rating: 0.82
quality_rating: 0.37不过,如果用户没有输入quality_rating,则数据集可能使用如下特殊值来表示不存在该值:
quality_rating: -1为了解决特殊值的问题,需将该特征转换为两个特征:
- 一个特征只存储质量评分,不含特殊值。
- 一个特征存储布尔值,表示是否提供了quality_rating。
5.4)考虑上游不稳定性
特征的定义不应随时间变化。例如,下列值是有用的,因为城市名称一般不会改变。
city_id: "br/sao_paulo"但收集由其他模型推理的值会产生额外成本。可能值“219”目前代表圣保罗,但这种表示在未来运行其他模型时可能轻易发送变化:
inferred_city_cluster: "219"
关键词—特征工程、离散特征、表示法、独热编码
特征工程(feature engineering),是指确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。特征工程有时称为特征提取。
离散特征(discrete feature),一种特征,包含有限个可能值。例如,某个值只能是“动物”、或“蔬菜”的特征,这是都能将类别列举出来的。与连续特征相对。
独热编码(one-hot-encoding),一种稀疏二元向量,其中:
- 一个元素设为1.
- 其他所有元素均设为0 。
独热编码常用语表示拥有 有限个可能值的字符串或标识符。
表示法(representation),将数据映射到实用特征的过程。
参考:https://developers.google.cn/machine-learning/crash-course/representation/feature-engineering
参考:https://developers.google.cn/machine-learning/crash-course/representation/qualities-of-good-features

- 点赞
- 收藏
- 关注作者
评论(0)