Python爬取B站视频评论并进行数据分析

【摘要】 Python爬取冰冰 一条B站视频的千条评论,绘制词云图,看看大家说了什么吧,Python爬取B站视频评论并进行数据分析
Python爬取B站视频评论并进行数据分析
Python爬取冰冰 一条B站视频的千条评论,绘制词云图,看看大家说了什么吧,Python爬取B站视频评论并进行数据分析
酱酱酱,那就开始吧

|

|

1. 数据收集
1.1 获取接口
哔哩哔哩其实留了很多接口,可以供我们来获取数据。 首先打开目标网站,并查看网页源码,发现评论内容不在源码中,可以确认评论是动态生成的。于是进入开发者模式,查找返回的内容。

1.2 查看数据
点击preview即可发现评论数据在这里

1.3 解析URL
去掉第一个和最后一个参数可得评论URL,https://api.bilibili.com/x/v2/replyjsonp&type=1&oid=800760067&sort=2&pn=.

1.4 解析数据
大家可以将获取的json
接下来就是正式的爬取工作了,和爬取百度图片原理一样,自己试试吧。
为了方便查看json数据,可以将html中的json复制到json在线解析中查看

# -*- coding: utf-8 -*-
"""
@author: 北山啦
@address:beishan.blog.csdn.net
"""
import requests
headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0",
'cookie': ''}
import pandas as pd
comments = []
users = []
genders = []
levels = []
likes = []
original_url = "https://api.bilibili.com/x/v2/reply?jsonp&type=1&oid=800760067&sort=2&pn="
for page in range(1,60): # 页码这里就简单处理了
url = original_url + str(page)
print(url)
try:
html = requests.get(url, headers=headers)
data = html.json()
if data['data']['replies']:
for i in data['data']['replies']:
comments.append(i['content']['message'])
likes.append(i['like'])
users.append(i['member']['uname'])
genders.append(i['member']['sex'])
levels.append(i["member"]["level_info"]["current_level"])
except Exception as err:
print(url)
print(err)
data = pd.DataFrame({"用户":users,"性别":genders,"等级":levels,"评论":comments,"点赞":likes})
data.to_excel("bingbing.xlsx")
2. 数据分析
数据获取后,就可以开始初步的数据分析了
import pandas as pd
data = pd.read_excel(r"bingbing.xlsx")
data.head()
<style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; }
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 用户 | 性别 | 等级 | 评论 | 点赞 | |
|---|---|---|---|---|---|
| 0 | 食贫道 | 男 | 6 | [呆][呆][呆]你来了嘿! | 158457 |
| 1 | 毕导THU | 男 | 6 | 我是冰冰仅有的3个关注之一[tv_doge]我和冰冰贴贴 | 148439 |
| 2 | 老师好我叫何同学 | 男 | 6 | [热词系列_知识增加] | 89634 |
| 3 | 央视网快看 | 保密 | 6 | 冰冰来了!我们要失业了吗[doge][doge] | 118370 |
| 4 | 厦门大学 | 保密 | 5 | 哇欢迎冰冰!!! | 66196 |
2.1 数据描述
data.describe()
<style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; }
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 等级 | 点赞 | |
|---|---|---|
| count | 1180.000000 | 1180.000000 |
| mean | 4.481356 | 2200.617797 |
| std | 1.041379 | 10872.524850 |
| min | 2.000000 | 1.000000 |
| 25% | 4.000000 | 4.000000 |
| 50% | 5.000000 | 9.000000 |
| 75% | 5.000000 | 203.750000 |
| max | 6.000000 | 158457.000000 |
2. 2 删除空值
data.dropna()
<style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; }
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 用户 | 性别 | 等级 | 评论 | 点赞 | |
|---|---|---|---|---|---|
| 0 | 食贫道 | 男 | 6 | [呆][呆][呆]你来了嘿! | 158457 |
| 1 | 毕导THU | 男 | 6 | 我是冰冰仅有的3个关注之一[tv_doge]我和冰冰贴贴 | 148439 |
| 2 | 老师好我叫何同学 | 男 | 6 | [热词系列_知识增加] | 89634 |
| 3 | 央视网快看 | 保密 | 6 | 冰冰来了!我们要失业了吗[doge][doge] | 118370 |
| 4 | 厦门大学 | 保密 | 5 | 哇欢迎冰冰!!! | 66196 |
| ... | ... | ... | ... | ... | ... |
| 1175 | 黑旗鱼 | 保密 | 5 | 11小时一百万,好快[惊讶] | 5 |
| 1176 | 是你的益达哦 | 男 | 6 | 冰冰粉丝上涨速度:11小时107.3万,平均每小时上涨9.75万,每分钟上涨1625,每秒钟... | 5 |
| 1177 | 快乐风男崔斯特 | 男 | 4 | 军训的时候去了趟厕所,出来忘记是哪个队伍了。看了up的视频才想起来,是三连[doge][滑稽] | 5 |
| 1178 | 很认真的大熊 | 男 | 5 | 我觉得冰冰主持春晚应该问题不大吧。[OK] | 5 |
| 1179 | 飞拖鞋呀吼 | 保密 | 5 | 《论一个2级号如何在2020年最后一天成为百大up主》 | 5 |
1180 rows × 5 columns
2.3 删除重复值
data.drop_duplicates()
<style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; }
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 用户 | 性别 | 等级 | 评论 | 点赞 | |
|---|---|---|---|---|---|
| 0 | 食贫道 | 男 | 6 | [呆][呆][呆]你来了嘿! | 158457 |
| 1 | 毕导THU | 男 | 6 | 我是冰冰仅有的3个关注之一[tv_doge]我和冰冰贴贴 | 148439 |
| 2 | 老师好我叫何同学 | 男 | 6 | [热词系列_知识增加] | 89634 |
| 3 | 央视网快看 | 保密 | 6 | 冰冰来了!我们要失业了吗[doge][doge] | 118370 |
| 4 | 厦门大学 | 保密 | 5 | 哇欢迎冰冰!!! | 66196 |
| ... | ... | ... | ... | ... | ... |
| 1175 | 黑旗鱼 | 保密 | 5 | 11小时一百万,好快[惊讶] | 5 |
| 1176 | 是你的益达哦 | 男 | 6 | 冰冰粉丝上涨速度:11小时107.3万,平均每小时上涨9.75万,每分钟上涨1625,每秒钟... | 5 |
| 1177 | 快乐风男崔斯特 | 男 | 4 | 军训的时候去了趟厕所,出来忘记是哪个队伍了。看了up的视频才想起来,是三连[doge][滑稽] | 5 |
| 1178 | 很认真的大熊 | 男 | 5 | 我觉得冰冰主持春晚应该问题不大吧。[OK] | 5 |
| 1179 | 飞拖鞋呀吼 | 保密 | 5 | 《论一个2级号如何在2020年最后一天成为百大up主》 | 5 |
1179 rows × 5 columns
3. 可视化展示
用的的工具是pyecharts,可以参考快速掌握数据可视化工具pyecharts
3.1 点赞TOP20
df1 = data.sort_values(by="点赞",ascending=False).head(20)
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c1 = (
Bar()
.add_xaxis(df1["评论"].to_list())
.add_yaxis("点赞数", df1["点赞"].to_list(), color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="评论热度Top20"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
.render_notebook()
)
c1

3.2 等级分布
data.等级.value_counts().sort_index(ascending=False)
6 165
5 502
4 312
3 138
2 63
Name: 等级, dtype: int64
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c2 = (
Pie()
.add(
"",
[list(z) for z in zip([str(i) for i in range(2,7)], [63,138,312,502,165])],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="等级分布"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
c2

3.3 性别分布
data.性别.value_counts().sort_index(ascending=False)
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c4 = (
Pie()
.add(
"",
[list(z) for z in zip(["男","女","保密"], ["404",'103','673'])],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="性别分布"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
c4

3.4 绘制词云图
from wordcloud import WordCloud
import jieba
from tkinter import _flatten
from matplotlib.pyplot import imread
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
with open('stoplist.txt', 'r', encoding='utf-8') as f:
stopWords = f.read()
with open('停用词.txt','r',encoding='utf-8') as t:
stopWord = t.read()
total = stopWord.split() + stopWords.split()
def my_word_cloud(data=None, stopWords=None, img=None):
dataCut = data.apply(jieba.lcut) # 分词
dataAfter = dataCut.apply(lambda x: [i for i in x if i not in stopWords]) # 去除停用词
wordFre = pd.Series(_flatten(list(dataAfter))).value_counts() # 统计词频
mask = plt.imread(img)
plt.figure(figsize=(20,20))
wc = WordCloud(scale=10,font_path='C:/Windows/Fonts/STXINGKA.TTF',mask=mask,background_color="white",)
wc.fit_words(wordFre)
plt.imshow(wc)
plt.axis('off')
my_word_cloud(data=data["评论"],stopWords=stopWords,img="1.jpeg")
3.5 Summary
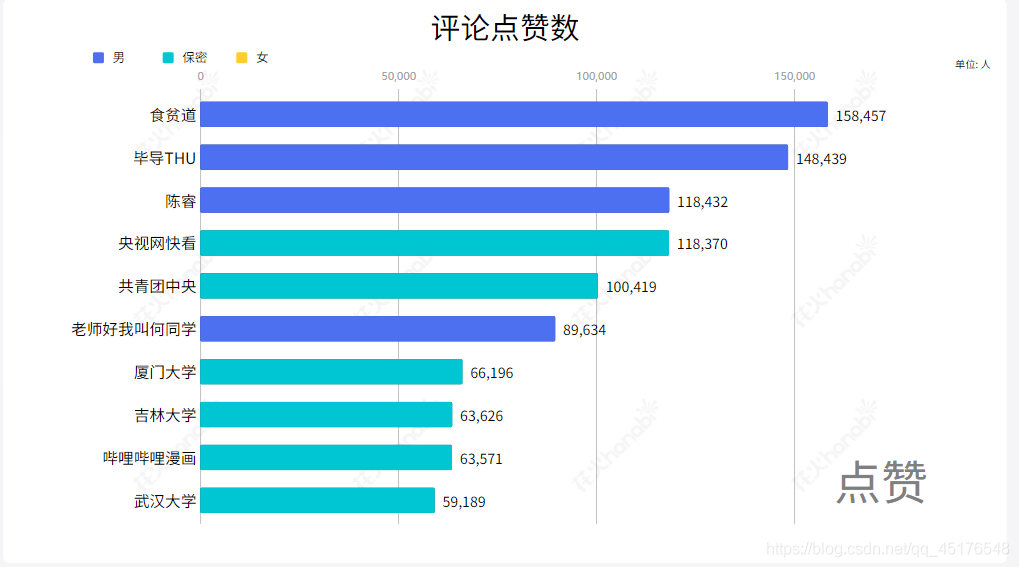
通过之前博客的学习,想必大家已经对Python网络爬虫有了了解,希望大家动手实践。笔者能力有限,有更多有趣的发现,欢迎私信或留言。 到这里就结束了,如果对你有帮助,欢迎点赞关注,你的点赞对我很重要


【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)