用 Opencv 和 Python 模糊检测


在刚刚过去的这个周末,我坐下来想在 iphoto 中整理这些海量的照片。这不仅仅意味着巨大的工作量,因为我很快注意到一个现象——其中充斥着大量模糊的照片。
主要因为我的摄影技术比较low,Jemma又特别活泼,跑来跑去,有时候看到我拍照,它又吓得缩起来发抖,所以我抓拍的效果不是很好,导致有多照片都是模糊的
作为一个普通人,我可能会想软件设计者们会开发出新功能来检测出这些模糊的照片(或者至少把他们移到一个单独的文件夹)。但是作为一个计算机视觉科学家,我是不会这样想的。
相反,我打开编辑器很快就编写了一个 Python 脚本,用 OpenCV 来执行模糊检测。
在这篇文章剩下的部分里,我将会展示如何用 OpenCV、Python 和拉普拉斯算子来计算图片中的模糊量。到文章结束,读者就能应用拉普拉斯方差算法来检测图片中的模糊量。
拉普拉斯方差算法(Variance of the Laplacian)

图1,用拉普拉斯算子与输入图像做卷积
我检测图片模糊量的第一步就是去拜读这篇优秀的综述文献——《Analysis of focus measure operators for shape-from-focus》[2013 Pertuz et al.]。在这篇文献中,Pertuz 等人论述了近 36 种不同的图片清晰度评价(focus measure)方法。
如果读者了解信号处理,就会知道最直接的方法就是计算图片的快速傅里叶变换,然后查看高低频的分布。如果图片有少量的高频成分,那么该图片就可以被认为是模糊的。然而,区分高频量多少的具体阈值却是十分困难的,不恰当的阈值将会导致极差的结果。
相反,如果我们能用计算出的一个具体浮点数值来表征图片的模糊程度,岂不是十分优雅?
Pertuz 等人讨论了很多种方法来计算“模糊度”。其中的一些方法简单明了,仅仅使用了像素灰度值的统计数据,其他的一些相比更加先进并且是基于特征的,使用了局部二值模式。
在快速浏览论文之后,我开始着手实现我找到的拉普拉斯方差算法——出自 Pech-Pacheco 等人 2000 年模式识别国际会议论文:《Diatom autofocusing in brightfield microscopy: a comparative study》
这种方法简洁明了,论证翔实,并且可以通过仅仅一行代码来实现:
|
1
|
cv2 . Laplacian ( image , cv2 . CV_64F ) . var ( )
|
只需要将图片中的某一通道(但一般用灰度值)用下面的拉普拉斯掩模做卷积运算:
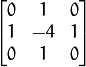
图2,拉普拉斯掩模
然后计算方差(即标准差的平方)。
如果某图片方差低于预先定义的阈值,那么该图片就可以被认为是模糊的。高于阈值,就不是模糊的。
这种方法凑效的原因就在于拉普拉斯算子定义本身。它被用来测量图片的二阶导数,突出图片中强度快速变化的区域,和 Sobel 以及 Scharr 算子十分相似。并且,和以上算子一样,拉普拉斯算子也经常用于边缘检测。此外,此算法基于以下假设:如果图片具有较高方差,那么它就有较广的频响范围,代表着正常,聚焦准确的图片。但是如果图片具有有较小方差,那么它就有较窄的频响范围,意味着图片中的边缘数量很少。正如我们所知道的,图片越模糊,其边缘就越少。
很显然,此算法的技巧在于设置合适的阈值。然而,阈值却十分依赖于所应用的领域。阈值太低会导致正常图片被误断为模糊图片,阈值太高会导致模糊图片被误判为正常图片。这种方法在能计算出可接受清晰度评价值的范围的环境中趋于发挥作用,能检测出异常照片。
检测图片中的模糊量
到目前为止,本文已经介绍完了计算给定图片模糊度的方法。下面这十二张图片组成的数据集将会在下文用到:

图3,图像数据集
在这些图片中,有些是模糊的,有些是正常的,而要完成目标就是把它们区分开来。
如前文所述,新建文件并命名为”detect_blur.py”,开始码代码吧:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian ( image ) :
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2 . Laplacian ( image , cv2 . CV_64F ) . var ( )
# construct the argument parse and parse the arguments
ap = argparse . ArgumentParser ( )
ap . add_argument ( "-i" , "--images" , required = True ,
help = "path to input directory of images" )
ap . add_argument ( "-t" , "--threshold" , type = float , default = 100.0 ,
help = "focus measures that fall below this value will be considered 'blurry'" )
args = vars ( ap . parse_args ( ) )
|
在代码开始的2-4行,导入了必需的模块。如果读者还没有安装我开发的 imutils 模块,请先安装该模块:
|
1
|
$ pip intall imutils
|
在代码第六行中,定义了 variance_of_laplacian 函数。此函数只接收一个待计算清晰度评价的 image 参数(假设是单通道图像,例如灰度图)。第九行对 image 用3×3拉普拉斯算子做卷积,然后返回方差。
12-17行处理命令行参数解析。第一个需要的参数是 –image,包含进行模糊度检测的图片数据集路径。
代码中还定义了一个可选参数 –thresh, 是用于模糊检测的阈值。如果给定图片的清晰度评价值低于该阈值,该图片就会被判定为模糊。如果读者使用其他的数据集,调整该阈值是很重要的。阈值 100 对于本文所使用的数据集效果良好,但是阈值受具体图片内容影响较大,因此为了获得最优结果,读者需要审慎地确定阈值。
不管你信不信,最艰苦的部分已经完成了。剩下的就只需要写点代码来从磁盘中读入图片,计算拉普拉斯方差然后标记图片为模糊或者正常:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian ( image ) :
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2 . Laplacian ( image , cv2 . CV_64F ) . var ( )
# construct the argument parse and parse the arguments
ap = argparse . ArgumentParser ( )
ap . add_argument ( "-i" , "--images" , required = True ,
help = "path to input directory of images" )
ap . add_argument ( "-t" , "--threshold" , type = float , default = 100.0 ,
help = "focus measures that fall below this value will be considered 'blurry'" )
args = vars ( ap . parse_args ( ) )
# loop over the input images
for imagePath in paths . list_images ( args [ "images" ] ) :
# load the image, convert it to grayscale, and compute the
# focus measure of the image using the Variance of Laplacian
# method
image = cv2 . imread ( imagePath )
gray = cv2 . cvtColor ( image , cv2 . COLOR_BGR2GRAY )
fm = variance_of_laplacian ( gray )
text = "Not Blurry"
# if the focus measure is less than the supplied threshold,
# then the image should be considered "blurry"
if fm & lt ; args [ "threshold" ] :
text = "Blurry"
# show the image
cv2 . putText ( image , "{}: {:.2f}" . format ( text , fm ) , ( 10 , 30 ) ,
cv2 . FONT_HERSHEY_SIMPLEX , 0.8 , ( 0 , 0 , 255 ) , 3 )
cv2 . imshow ( "Image" , image )
key = cv2 . waitKey ( 0 )
|
代码第二十行遍历给定目录中的所有图片。对每一幅从磁盘加载的图像,先将它们转化为灰度图,然后用OpenCV执行模糊检测(代码24-27行)。
如果图像的清晰度低于命令行提供的预置参数,该图像将被标记为“模糊”。
在代码最后,第35-38行将 text 和计算出的清晰度评价值写入图像中并将图像展示在屏幕上。
用OpenCV执行模糊检测
至此,detect_blur.py 脚本已经编写完毕,来练练手吧。打开命令行,敲入以下命令:
|
1
|
$ python detect_blur . py -- images images
|

图4,准确标记为“模糊”
这张图象的清晰度评价值为 83.17,低于阈值 100,因此标记其为“模糊”。

此图像清晰度评价值为64.25,同样标记其为“模糊”。

图6,标记为“正常”
图像6的清晰度评价值高达 1004.14,比前两张图像高出两个数量级。毫无疑问,此图不模糊,十分清晰。

此图唯一模糊的地方在 Jemma 摇动的尾巴上。

虽然此图的清晰度评价值低于图7,但是我们还是可以把它准确归入“正常”。

我们可以清除看见上图的模糊。

如此高的清晰度评价值意味着此图“正常”。

此图中包含有大量的模糊。

图12,标记为“模糊”

图13,和图12相比,模糊量大大减少

图14,准确标记为“正常”

图15,标记为“模糊”
总结
在此文中,我们学习了用 OpenCV 和 Python 来执行模糊检测。
我们实现了拉普拉斯方差算法,该算法提供给我们一个浮点数来代表具体图像的“模糊度”。该算法快速,简单且易于使用——用拉普拉斯算子与输入图像做卷积然后计算方差即可。如果方差低于预定义阈值,图像就被标记为“模糊”。
读者必须明白阈值是一个很重要的待调整参数,针对每一个数据集都需要重新设定,阈值太低会导致正常图片被误断为模糊图片,阈值太高会导致模糊图片被误判为正常图片。
下载代码,然后尝试一下吧!
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/80574451

- 点赞
- 收藏
- 关注作者
评论(0)