人脸识别中的rank-n

人脸识别中的rank-n 代表的意思
原创这个昵称唯一 最后发布于2017-09-02 11:05:13 阅读数 2247 收藏
展开
Rank-1
看一些论文总是在结果中看到rank-1,等等,但是就不知道什么意思,今天终于搞明白了,备注一下。
意思
rank 1, 就是第一次命中
rank k,就是在第k次以内命中
人脸识别中,就代表,与目标人脸,最相似的k个人脸中,成功命中(找到正确人脸)的概率(和)。
RANK曲线,一般又被称呼为CMC曲线。
扩展阅读:人脸识别中常用的指标:
1、rank-n
搜索结果中最靠前(置信度最高)的n张图有正确结果的概率。
例如: lable为 m1,在100个样本中搜索。
如果识别结果是 m1、m2、m3、m4、m5……,则此时rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
如果识别结果是 m2、m1、m3、m4、m5……,则此时rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
如果识别结果是 m2、m3、m4、m5、m1……,则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%
当待识别的人脸集合有很多时,则采取取平均值的做法。
2、Precision & Recall
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
Precision:准确率 output为1中ground truth也为1的 占ground truth为1的概率
Recall:召回率 output为1中ground truth也为1的 占output为1的概率
正确率 = 提取出的正确信息条数 / 提取出的信息条数
召回率 = 提取出的正确信息条数 / 样本中的信息条数
准确率和召回率都是针对同一类别来说的,并且只有当检索到当前类别时才进行计算,比如在person re-id中,一个人的label为m1,在测试集中包含3张此人的图像,检索出来的图像按照得分从高到低顺序为m1、m2、m1、m3、m4、m1….,此时
第一次检索到m1,提取出的正确信息条数=1,提取出的信息条数=1,样本中的信息条数=3,正确率=1/1=100%,召回率=1/3=33.33%;
第二次检索到m1,提取出的正确信息条数=2,提取出的信息条数=3,样本中的信息条数=3,正确率=2/3=66.66%,召回率=2/3=66.66%;
第三次检索到m1,提取出的正确信息条数=3,提取出的信息条数=6,样本中的信息条数=3,正确率=3/6=50%,召回率=3/3=100%;
平均正确率AP=(100%+66.66%+50%)/3=72.22%
而当需要检索的不止一个人时,此时正确率则取所有人的平均mAP。
3、F-score
recall和precision的调和平均数 2 * P * R / (P + R)
从上面准确率和召回率之间的关系可以看出,一般情况下,Precision高,Recall就低,Recall高,Precision就低。所以在实际中常常需要根据具体情况做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。
很多时候我们需要综合权衡这2个指标,这就引出了一个新的指标F-score。这是综合考虑Precision和Recall的调和值。
当β=1时,称为F1-score,这时,精确率和召回率都很重要,权重相同。当有些情况下,我们认为精确率更重要些,那就调整β的值小于1,如果我们认为召回率更重要些,那就调整β的值大于1。
比如在上面的例子中,在第三次检索到m1时的争取率为50%,召回率为100%,则F1-score=(2*0.5*1)/(0.5+1)=66.66%,而F0.5-score=(1.25*0.5*1)/(0.25*0.5+1)=55.56%
4、mAP
PR曲线下的面积(PR曲线: 所有样本的precision和recall绘制在图里)
例如:query-id = 1,query-cam = 1,gallery共有5张图,按照下图方式计算出recall和precision,以recall为横坐标,precision为纵坐标,绘制PR曲线,曲线下方面积即为AP,当需要检索的不止一个人时,此时取所有人的平均mAP。。

曲线下方面积计算方法有多种,例如 ap = ap + (recall - old_recall)*((old_precision+precision)/2);
AP衡量的是学出来的模型在单个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏
5、CMC
对于single gallery shot来说,每一次query,对samples排序,找到匹配上id的gallery后,排除掉同一个camera下同一个id的sample。
CMC曲线是算一种top-k的击中概率,主要用来评估闭集中rank的正确率。举个很简单的例子,假如在人脸识别中,底库中有100个人,现在来了1个待识别的人脸(假如label为m1),与底库中的人脸比对后将底库中的人脸按照得分从高到低进行排序,我们发现:
如果识别结果是m1、m2、m3、m4、m5……,则此时rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
如果识别结果是m2、m1、m3、m4、m5……,则此时rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
如果识别结果是m2、m3、m4、m5、m1……,则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%;
同理,当待识别的人脸集合有很多时,则采取取平均值的做法。例如待识别人脸有3个(假如label为m1,m2,m3),同样对每一个人脸都有一个从高到低的得分,
比如人脸1结果为m1、m2、m3、m4、m5……,人脸2结果为m2、m1、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(1+1+1)/3=100%;rank-2的正确率也为(1+1+1)/3=100%;rank-5的正确率也为(1+1+1)/3=100%;
比如人脸1结果为m4、m2、m3、m5、m6……,人脸2结果为m1、m2、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(0+0+1)/3=33.33%;rank-2的正确率为(0+1+1)/3=66.66%;rank-5的正确率也为(0+1+1)/3=66.66%;
6、ROC
ROC曲线是检测、分类、识别任务中很常用的一项评价指标。曲线上每个点反映着对同一信号刺激的感受性。具体到识别任务中就是,ROC曲线上的每一点反映的是不同的阈值对应的FP(false positive)和TP(true positive)之间的关系。
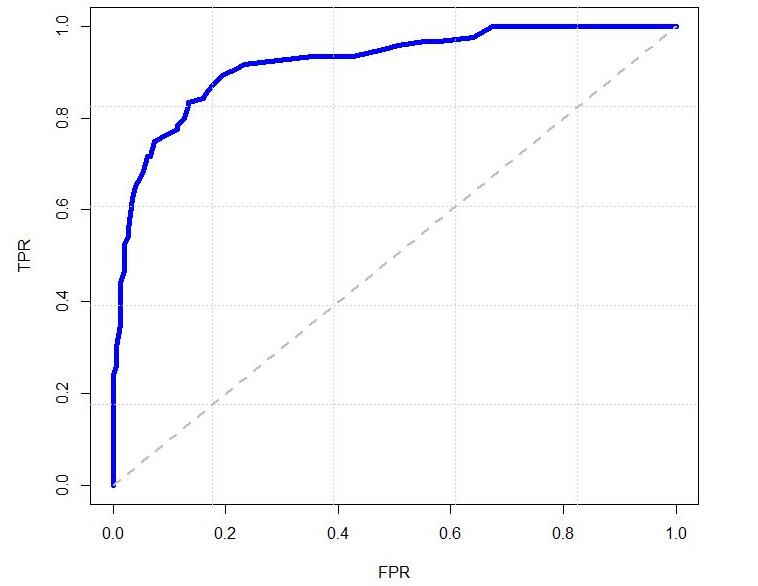
曲线上的每一点反映的是不同的阈值对应的FP(false positive)和TP(true positive)之间的关系。通常情况下,ROC曲线越靠近(0,1)坐标表示性能越好。
TP : True Positive 预测为1,实际也为1;TN:True Nagetive 预测为0,实际也为0
FP:False Positive 预测为1,实际为0的;FN:False Nagetive 预测为0,实际为1的
TPR=TP/(TP+FN)=Recall。
FPR=FP/(FP+TN),FPR即为实际为好人的人中,预测为坏人的人占比。
以FPR为x轴,TPR为y轴画图,就得到了ROC曲线。
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/104857663

- 点赞
- 收藏
- 关注作者
评论(0)