SPP原理和代码

空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)
一、为什么需要SPP
首先需要知道为什么需要SPP。
我们都知道卷积神经网络(CNN)由卷积层和全连接层组成,其中卷积层对于输入数据的大小并没有要求,唯一对数据大小有要求的则是第一个全连接层,因此基本上所有的CNN都要求输入数据固定大小,例如著名的VGG模型则要求输入数据大小是 (224*224) 。
固定输入数据大小有两个问题:
很多场景所得到数据并不是固定大小的,例如街景文字基本上其高宽比是不固定的,如下图示红色框出的文字。
2.可能你会说可以对图片进行切割,但是切割的话很可能会丢失到重要信息。
综上,SPP的提出就是为了解决CNN输入图像大小必须固定的问题,从而可以使得输入图像高宽比和大小任意。
二、SPP原理
更加具体的原理可查看原论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
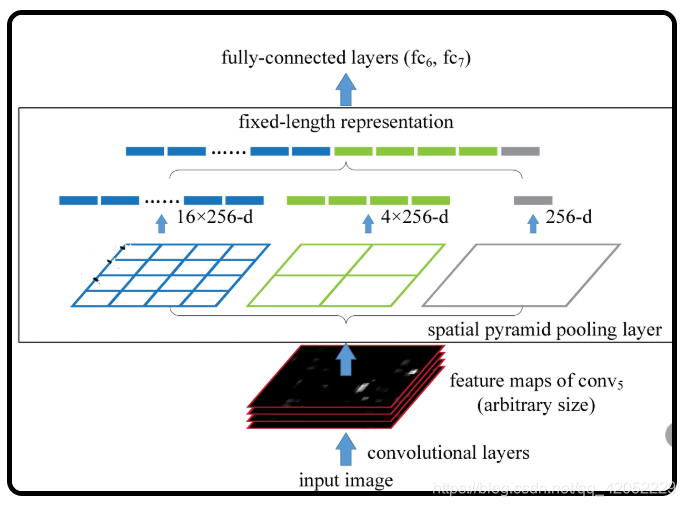
上图是原文中给出的示意图,需要从下往上看:
-
首先是输入层(input image),其大小可以是任意的
-
进行卷积运算,到最后一个卷积层(图中是conv5)输出得到该层的特征映射(feature maps),其大小也是任意的
-
下面进入SPP层
我们先看最左边有16个蓝色小格子的图,它的意思是将从conv5得到的特征映射分成16份,另外16X256中的256表示的是channel,即SPP对每一层都分成16份(不一定是等比分,原因看后面的内容就能理解了)。
中间的4个绿色小格子和右边1个紫色大格子也同理,即将特征映射分别分成4X256和1X256份
那么将特征映射分成若干等分是做什么用的呢? 我们看SPP的名字就是到了,是做池化操作,一般选择MAX Pooling,即对每一份进行最大池化。
我们看上图,通过SPP层,特征映射被转化成了16X256+4X256+1X256 = 21X256的矩阵,在送入全连接时可以扩展成一维矩阵,即1X10752,所以第一个全连接层的参数就可以设置成10752了,这样也就解决了输入数据大小任意的问题了。
注意上面划分成多少份是可以自己是情况设置的,例如我们也可以设置成3X3等,但一般建议还是按照论文中说的的进行划分。
三、SPP公式
理论应该理解了,那么如何实现呢?下面将介绍论文中给出的计算公式,但是在这之前先要介绍两种计算符号以及池化后矩阵大小的计算公式:
1. 预备知识
2.公式
假设
-
输入数据大小是(c,hin,win),分别表示通道数,高度,宽度
-
池化数量:(n,n)
那么则有
-
核(Kernel)大小: ⌈hinn,winn⌉=ceil(hinn,winn)
-
步长(Stride)大小: ⌊hinn,winn⌋=floor(hinn,winn)
我们可以验证一下,假设输入数据大小是(10,7,11), 池化数量(2,2):
那么核大小为(4,6), 步长大小为(3,5), 得到池化后的矩阵大小的确是2∗2。
3.公式修订
是的,论文中给出的公式的确有些疏漏,我们还是以举例子的方式来说明
假设输入数据大小和上面一样是(10,7,11), 但是池化数量改为(4,4):
此时核大小为(2,3), 步长大小为(1,2),得到池化后的矩阵大小的确是6∗5 ←[简单的计算矩阵大小的方法:(7=2+15, 11=3+24)],而不是4∗4。
那么问题出在哪呢?
我们忽略了padding的存在(我在原论文中没有看到关于padding的计算公式,如果有的话。。。那就是我看走眼了,麻烦提示我一下在哪个位置写过,谢谢)。
仔细看前面的计算公式我们很容易发现并没有给出padding的公式,在经过N次使用SPP计算得到的结果与预期不一样以及查找各种网上资料(尽管少得可怜)后,现将加入padding后的计算公式总结如下。
现在再来检验一下:
假设输入数据大小和上面一样是(10,7,11), 池化数量为(4,4):
Kernel大小为(2,3),Stride大小为(2,3),所以Padding为(1,1)。
利用矩阵大小计算公式:⌊h+2p−fs+1⌋*⌊w+2p−fs+1⌋得到池化后的矩阵大小为:4∗4。
四、代码实现
-
#coding=utf-8
-
-
import math
-
import torch
-
import torch.nn.functional as F
-
-
# 构建SPP层(空间金字塔池化层)
-
class SPPLayer(torch.nn.Module):
-
-
def __init__(self, num_levels, pool_type='max_pool'):
-
super(SPPLayer, self).__init__()
-
-
self.num_levels = num_levels
-
self.pool_type = pool_type
-
-
def forward(self, x):
-
num, c, h, w = x.size() # num:样本数量 c:通道数 h:高 w:宽
-
for i in range(self.num_levels):
-
level = i+1
-
kernel_size = (math.ceil(h / level), math.ceil(w / level))
-
stride = (math.ceil(h / level), math.ceil(w / level))
-
pooling = (math.floor((kernel_size[0]*level-h+1)/2), math.floor((kernel_size[1]*level-w+1)/2))
-
-
# 选择池化方式
-
if self.pool_type == 'max_pool':
-
tensor = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
-
else:
-
tensor = F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
-
-
# 展开、拼接
-
if (i == 0):
-
x_flatten = tensor.view(num, -1)
-
else:
-
x_flatten = torch.cat((x_flatten, tensor.view(num, -1)), 1)
-
return x_flatten
原文地址:https://www.cnblogs.com/marsggbo/p/8572846.html
原文中的代码:marsggbo/sppnet-pytorch
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/105923636

- 点赞
- 收藏
- 关注作者
评论(0)