pandas打乱数据

【摘要】 本文是把网上的方法收集下来,以便读者方便使用。
pandas自己的:
shuffle_data= df.sample(frac=1).reset_index(drop=True)
方法2:
我们有下面以个DataFrame
我们可以看到BuyInter的数值是按照0,-1,-1,2,2,2,3,3,3,3这样排列的,我们希望不保持这个次序,但是同时列属...
本文是把网上的方法收集下来,以便读者方便使用。
pandas自己的:
shuffle_data= df.sample(frac=1).reset_index(drop=True)
方法2:
我们有下面以个DataFrame
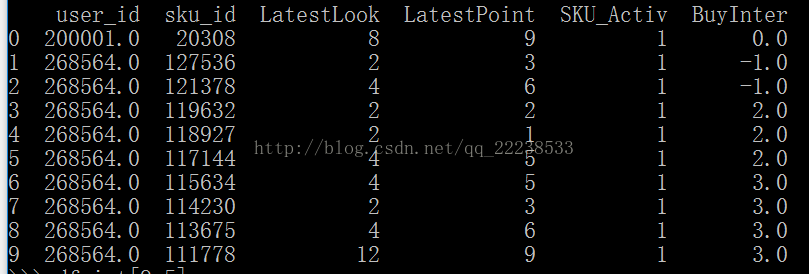
我们可以看到BuyInter的数值是按照0,-1,-1,2,2,2,3,3,3,3这样排列的,我们希望不保持这个次序,但是同时列属性又不能改变,即如下效果:
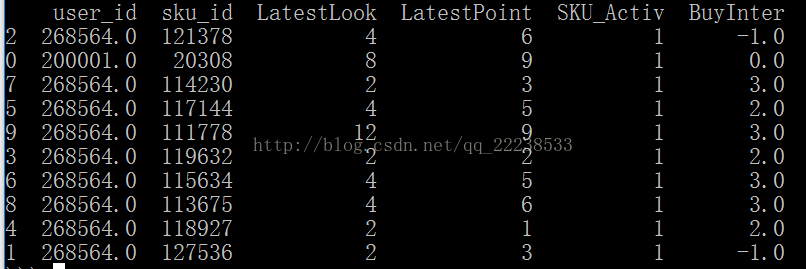
实现方法:
最简单的方法就是采用pandas中自带的 sample这个方法。
假设df是这个DataFrame
| 1 |
|
这样对可以对df进行shuffle。其中参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3。
有时候,我们可能需要打混后数据集的index(索引)还是按照正常的排序。我们只需要这样操作
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/108734466

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)