yolov5改进VariFocalNet

VariFocalNet | IoU-aware同V-Focal Loss全面提升密集目标检测(附YOLOV5测试代码)
观察到,核心网络是resnet50,resnet101
如果推理报错,参考:
https://github.com/hyz-xmaster/VarifocalNet/issues/1
准确地对大量候选检测器进行排名是高性能密集目标检测器的关键。尽管先前的工作使用分类评分或它与基于IoU的定位评分的组合作为排名基础,但它们都不能得到可靠地排名结果,这会损害检测性能。
在本文中,作者提出学习可同时表示对象存在置信度和定位精度的IoU感知分类评分(IACS),以在密集对象检测器中产生更准确的检测等级。特别地本文还设计了一个新的损失函数,称为Varifocal损失,用于训练密集的物体检测器来预测IACS,并设计了一种新的高效星形边界框特征表示,用于估算IACS和改进粗略边界框。结合这两个新组件和边界框优化分支,作者在FCOS架构上构建了一个新的密集目标检测器,简称为VarifocalNet或VFNet。
在MS COCO基准上进行的大量实验表明,VFNet超过了Baseline约2.0%AP,并且Res2Net-101-DCN最佳模型在COCO测试上达到了55.1%AP。
2 所提创新方法
本文提出学习IoU-aware classification score (IACS)用于对检测进行分级。为此在去掉中心分支的FCOS+ATSS的基础上,构建了一个新的密集目标检测器,称为VarifocalNet或VFNet。相比FCOS+ATSS融合了varifcoal loss、star-shaped bounding box特征表示和bounding box refinement 3个新组件。
2.1 IACS–IoU-Aware分类得分
IACS定义为分类得分向量的标量元素,其中ground-truth类标签位置的值为预测边界框与其ground truth之间的IoU,其他位置为0。
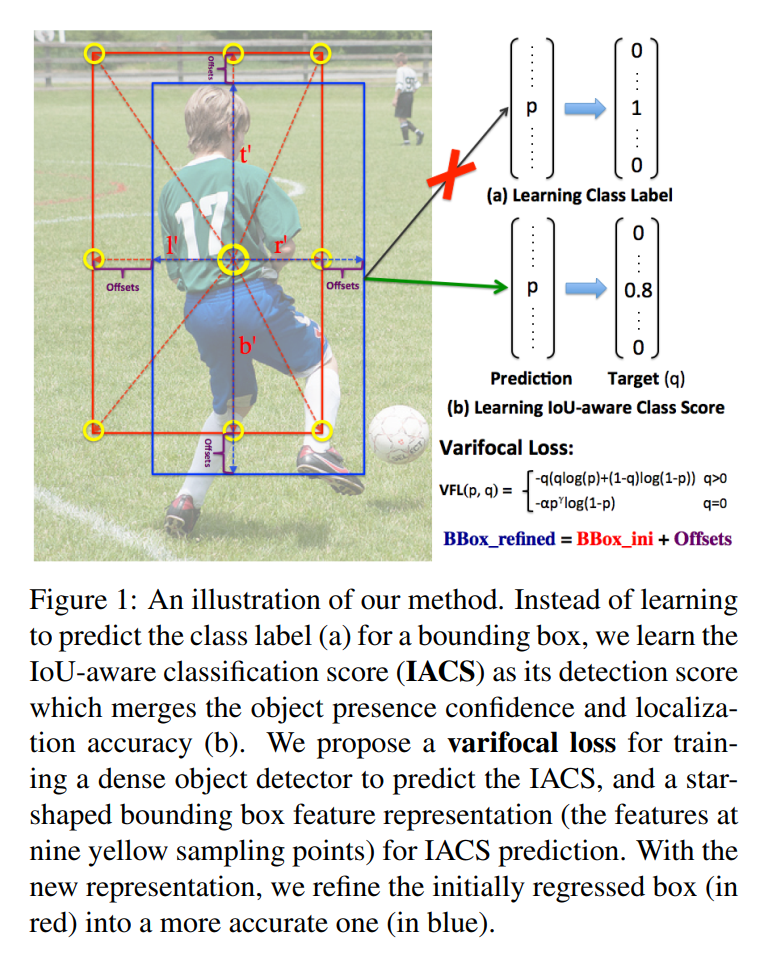
图1 IACS–IoU-Aware表示
如图1所示,不是学习预测一个bounding box的类标签(a),而是学习IoU-aware分类得分(IACS)作为检测分数,融合了目标存在置信度和定位精度(b)。
2.2 Varifocal Loss
本文设计了一种新的Varifocal Loss来训练密集目标检测器来预测IACS。由于它的灵感来自Focal Loss,这里也简要回顾一下Focal Loss。Focal Loss的设计是为了解决密集目标检测器训练中前景类和背景类之间极度不平衡的问题。定义为:
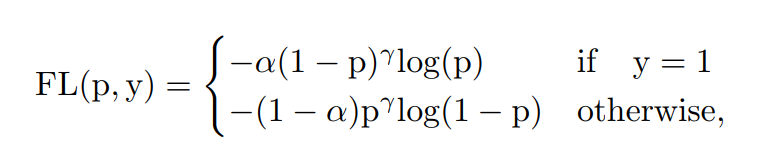
其中为ground-truth类,为前景类的预测概率。如公式所示,调制因子(γ为前景类和γ为背景类)可以减少简单样例的损失贡献,相对增加误分类样例的重要性。
因此,Focal Loss防止了训练过程中大量的简单负样本淹没检测器,并将检测器聚焦在稀疏的一组困难的例子上。
在训练密集目标检测器对连续IACS进行回归时借鉴了Focal Loss的加权方法来解决类别不平衡的问题。然而,不同的Focal Loss处理的正负相等,对待是不对称的。这里varifocal loss也是基于binary cross entropy loss,定义为:
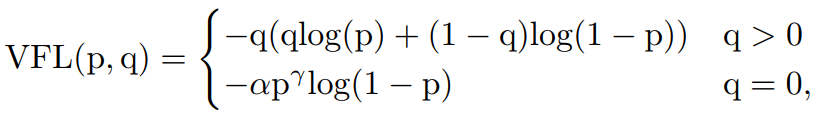
其中为预测的IACS, 为目标分数。对于前景点将其ground truth类设为生成的边界框和它的ground truth(gt_IoU)之间的IoU,否则为0,而对于背景点,所有类的目标为0。
如公式所示,通过用γ的因子缩放损失,varifocal loss仅减少了负例(q=0)的损失贡献,而不以同样的方式降低正例(q>0)的权重。这是因为positive样本相对于negatives样本是非常罕见的,应该保留它们的学习信息。
另一方面,受PISA的启发将正例与训练目标q加权。如果一个正例的gt_IoU较高,那么它对损失的贡献就会比较大。这就把训练的重点放在那些高质量的正面例子上,这些例子比那些低质量的例子对获得更高的AP更重要。
-
import mmcv
-
import torch.nn as nn
-
import torch.nn.functional as F
-
-
from ..builder import LOSSES
-
from .utils import weight_reduce_loss
-
-
-
@mmcv.jit(derivate=True, coderize=True)
-
def varifocal_loss(pred,
-
target,
-
weight=None,
-
alpha=0.75,
-
gamma=2.0,
-
iou_weighted=True,
-
reduction='mean',
-
avg_factor=None):
-
"""`Varifocal Loss <https://arxiv.org/abs/2008.13367>`_
-
Args:
-
pred (torch.Tensor): The prediction with shape (N, C), C is the
-
number of classes
-
target (torch.Tensor): The learning target of the iou-aware
-
classification score with shape (N, C), C is the number of classes.
-
weight (torch.Tensor, optional): The weight of loss for each
-
prediction. Defaults to None.
-
alpha (float, optional): A balance factor for the negative part of
-
Varifocal Loss, which is different from the alpha of Focal Loss.
-
Defaults to 0.75.
-
gamma (float, optional): The gamma for calculating the modulating
-
factor. Defaults to 2.0.
-
iou_weighted (bool, optional): Whether to weight the loss of the
-
positive example with the iou target. Defaults to True.
-
reduction (str, optional): The method used to reduce the loss into
-
a scalar. Defaults to 'mean'. Options are "none", "mean" and
-
"sum".
-
avg_factor (int, optional): Average factor that is used to average
-
the loss. Defaults to None.
-
"""
-
# pred and target should be of the same size
-
assert pred.size() == target.size()
-
pred_sigmoid = pred.sigmoid()
-
target = target.type_as(pred)
-
if iou_weighted:
-
focal_weight = target * (target > 0.0).float() + \
-
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
-
(target <= 0.0).float()
-
else:
-
focal_weight = (target > 0.0).float() + \
-
alpha * (pred_sigmoid - target).abs().pow(gamma) * \
-
(target <= 0.0).float()
-
loss = F.binary_cross_entropy_with_logits(
-
pred, target, reduction='none') * focal_weight
-
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
-
return loss
-
-
-
@LOSSES.register_module()
-
class VarifocalLoss(nn.Module):
-
-
def __init__(self,
-
use_sigmoid=True,
-
alpha=0.75,
-
gamma=2.0,
-
iou_weighted=True,
-
reduction='mean',
-
loss_weight=1.0):
-
"""`Varifocal Loss <https://arxiv.org/abs/2008.13367>`_
-
Args:
-
use_sigmoid (bool, optional): Whether the prediction is
-
used for sigmoid or softmax. Defaults to True.
-
alpha (float, optional): A balance factor for the negative part of
-
Varifocal Loss, which is different from the alpha of Focal
-
Loss. Defaults to 0.75.
-
gamma (float, optional): The gamma for calculating the modulating
-
factor. Defaults to 2.0.
-
iou_weighted (bool, optional): Whether to weight the loss of the
-
positive examples with the iou target. Defaults to True.
-
reduction (str, optional): The method used to reduce the loss into
-
a scalar. Defaults to 'mean'. Options are "none", "mean" and
-
"sum".
-
loss_weight (float, optional): Weight of loss. Defaults to 1.0.
-
"""
-
super(VarifocalLoss, self).__init__()
-
assert use_sigmoid is True, \
-
'Only sigmoid varifocal loss supported now.'
-
assert alpha >= 0.0
-
self.use_sigmoid = use_sigmoid
-
self.alpha = alpha
-
self.gamma = gamma
-
self.iou_weighted = iou_weighted
-
self.reduction = reduction
-
self.loss_weight = loss_weight
-
-
def forward(self,
-
pred,
-
target,
-
weight=None,
-
avg_factor=None,
-
reduction_override=None):
-
"""Forward function.
-
Args:
-
pred (torch.Tensor): The prediction.
-
target (torch.Tensor): The learning target of the prediction.
-
weight (torch.Tensor, optional): The weight of loss for each
-
prediction. Defaults to None.
-
avg_factor (int, optional): Average factor that is used to average
-
the loss. Defaults to None.
-
reduction_override (str, optional): The reduction method used to
-
override the original reduction method of the loss.
-
Options are "none", "mean" and "sum".
-
Returns:
-
torch.Tensor: The calculated loss
-
"""
-
assert reduction_override in (None, 'none', 'mean', 'sum')
-
reduction = (
-
reduction_override if reduction_override else self.reduction)
-
if self.use_sigmoid:
-
loss_cls = self.loss_weight * varifocal_loss(
-
pred,
-
target,
-
weight,
-
alpha=self.alpha,
-
gamma=self.gamma,
-
iou_weighted=self.iou_weighted,
-
reduction=reduction,
-
avg_factor=avg_factor)
-
else:
-
raise NotImplementedError
-
return loss_cls
2.3 Star-Shaped Box特征表示
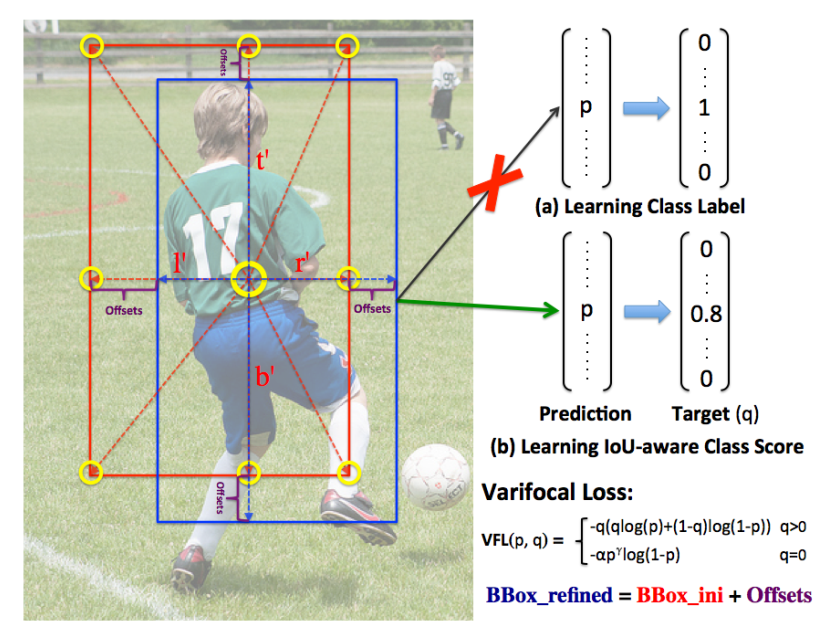
图2 Star-Shaped Box示意
本文设计了一种用于IACS预测的Star-Shaped Box特征表示方法。它利用9个固定采样点的特征(图2中的黄色圆圈)表示一个具有可变形卷积的bounding box。这种新的表示方法可以捕获bounding box的几何形状及其附近的上下文信息,这对于编码预测的bounding box和ground-truth之间的不对齐是至关重要的。
具体来说:
-
首先,给定图像平面上的一个采样位置(或feature map上的一个投影点),首先用卷积从它回归一个初始bounding box;
-
然后,在FCOS之后,这个bounding box由一个4D向量编码,这意味着位置分别到bounding box的左、上、右和下侧的距离。利用这个距离向量启发式地选取,,,,,,,和9个采样点,然后将它们映射到feature map上。它们与(x, y)投影点的相对偏移量作为可变形卷积的偏移量;
-
最后,将这9个投影点上的特征使用可变形卷积卷积表示一个bounding box。由于这些点是人工选择的,没有额外的预测负担。
2.4 Bounding Box细化
通过bounding box细化步骤进一步提高了目标定位的精度。bounding box细化是目标检测中常用的一种技术,但由于缺乏有效的、有判别性的目标描述符,在密集的目标检测器中并未得到广泛应用。有了Star-Shaped Box特征表示现在可以在高密度物体探测器中采用它,而不会损失效率。
这里将bounding box细化建模为一个残差学习问题。对于初始回归的bounding box:
-
首先,提取Star-Shaped Box特征表示并对其进行编码;
-
然后,根据表示学习4个距离缩放因子来缩放初始距离向量,使表示的细化bounding box更接近ground-truth。
3 VarifocalNet
将上述3个组件附加到FCOS网络体系结构并删除原来的centerness分支就得到了VarifocalNet。
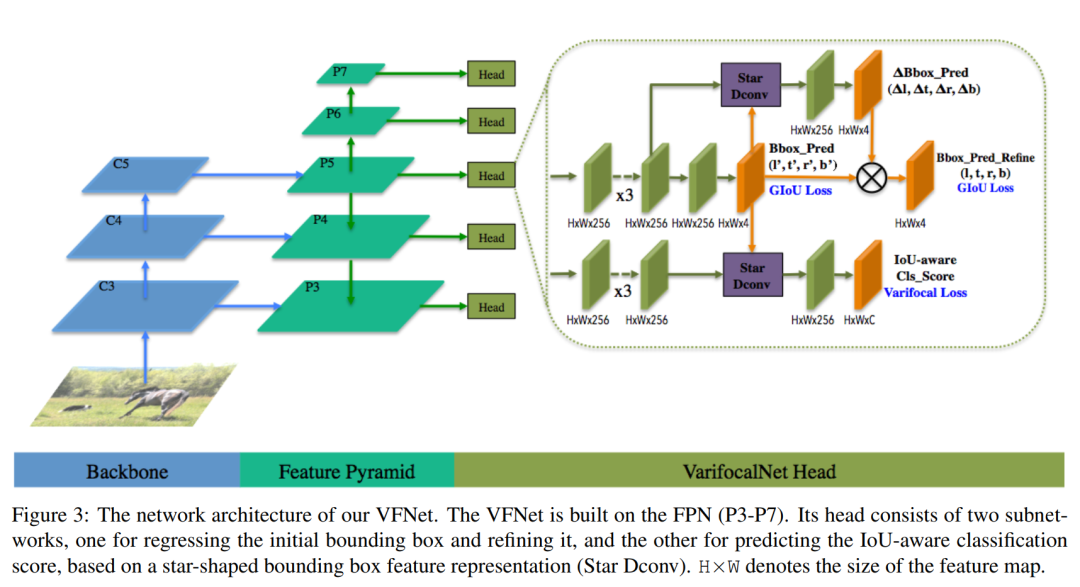
图3 VFNet架构
图3说明了VFNet的网络架构。VFNet的骨干网和FPN网部分与FCOS相同。区别在于头部结构。VFNet的Head是由2个子网组成:localization subnet执行bounding box回归和Bounding Box细化。
一个分支将FPN各层的特征图作为输入,首先应用ReLU激活的3个的conv层。这将产生256个通道的特征映射。localization subnet的一个分支再次卷积Feature Map,然后在每个空间位置输出一个4D距离向量,表示初始bounding box。考虑到最初的bounding box和特征映射,另一个分支应用卷积的Star-Shaped得到9个功能采样点和距离比例因子,然后距离变换因子乘以初始距离矢量便可以得到细化后的bounding box。
另一个分支用于预测IACS。它具有与localization subnet(细化分支)类似的结构,只是每个空间位置输出一个由C(类别)组成的向量,其中每个元素联合表示对象存在置信度和定位精度。
4 损失函数
VFNet的训练是由以下的loss函数来监督的:
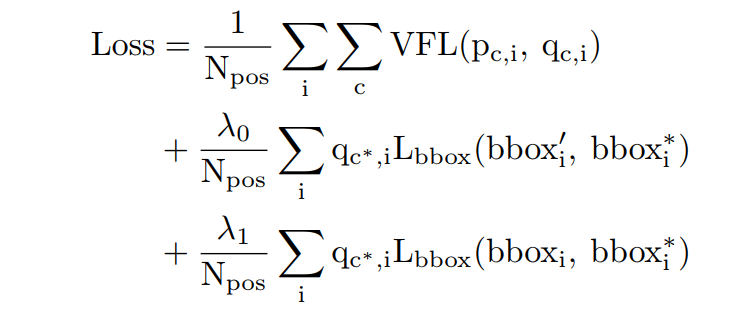
其中和分别为FPN每一级特征图上位置的c类IACS的预测和目标IACS。为GIoU损失,、和分别表示初始、细化和ground truth bounding box。用训练目标为加权,这是前景点的gt借据,否则为0,跟随FCOS。和分别是用来平衡中2个子损失的超参数,本文经验设定分别为1.5和2.0。Npos是前景点的数量,用于使总损失正常化。这里在训练期间使用ATSS来定义前景和背景点。
VFNet的推理很简单,只涉及通过网络模型传输输入图像和NMS的后处理步骤,以消除冗余检测。
基于YOLO V5的改进代码
替换YOLOV5中的Focal Loss即可,小编在小型数据集已经验证该方法的有效性。
-
class VFLoss(nn.Module):
-
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
-
super(VFLoss, self).__init__()
-
# 传递 nn.BCEWithLogitsLoss() 损失函数 must be nn.BCEWithLogitsLoss()
-
self.loss_fcn = loss_fcn #
-
self.gamma = gamma
-
self.alpha = alpha
-
self.reduction = loss_fcn.reduction
-
self.loss_fcn.reduction = 'mean' # required to apply VFL to each element
-
-
def forward(self, pred, true):
-
-
loss = self.loss_fcn(pred, true)
-
-
pred_prob = torch.sigmoid(pred) # prob from logits
-
-
focal_weight = true * (true > 0.0).float() + self.alpha * (pred_prob - true).abs().pow(self.gamma) * (true <= 0.0).float()
-
loss *= focal_weight
-
-
if self.reduction == 'mean':
-
return loss.mean()
-
elif self.reduction == 'sum':
-
return loss.sum()
-
else:
-
return loss
5 实验结果
5.1 Varifocal损失对比实验
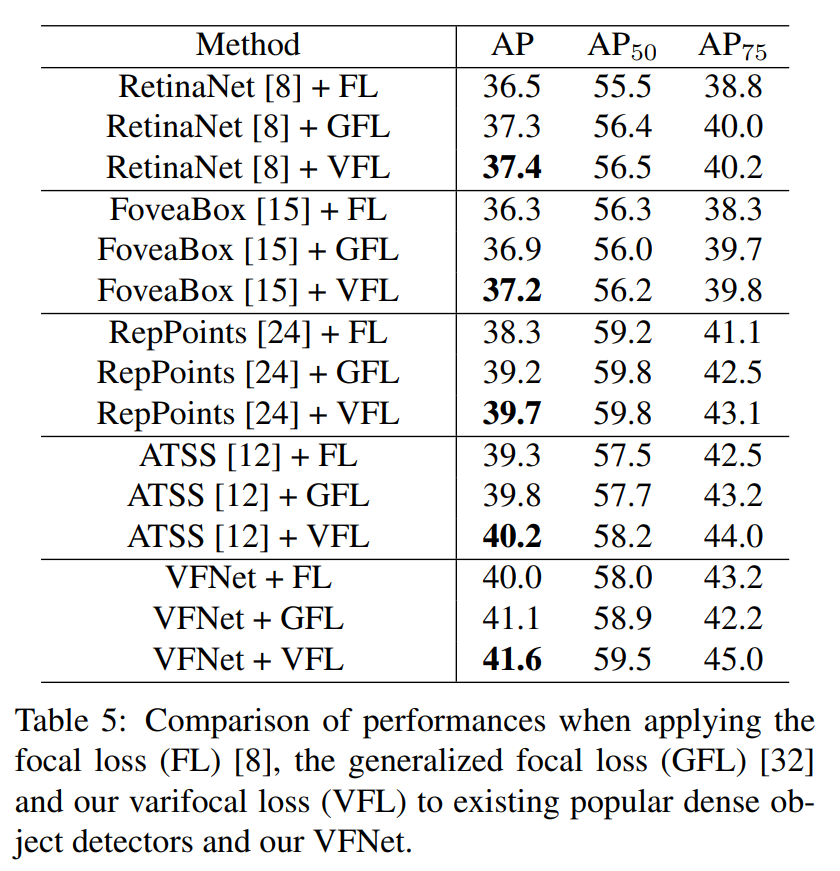
表1 FL、GFL、VFL对比表
表1显示了使用不同损失训练模型的结果。可以看到Varifocal损失使RetinaNet, FoveaBox和ATSS持续改善0.9 AP。对于RepPoints增加了1.4 AP。这表明Varifocal损失可以很容易地给现有的密集物体探测器带来相当大的性能提升。
与GFL相比Varifocal损失在所有情况下表现都比它好,证明了Varifocal损失的优越性。
此外,作者用FL和GFL训练了VFNet以便进一步比较。表1的最后一部分显示了结果,可以观察到Varifocal损失相对于FL和GFL依然具有优势。同时也证明了VFNet的有效性。
5.2 SOTA模型对比
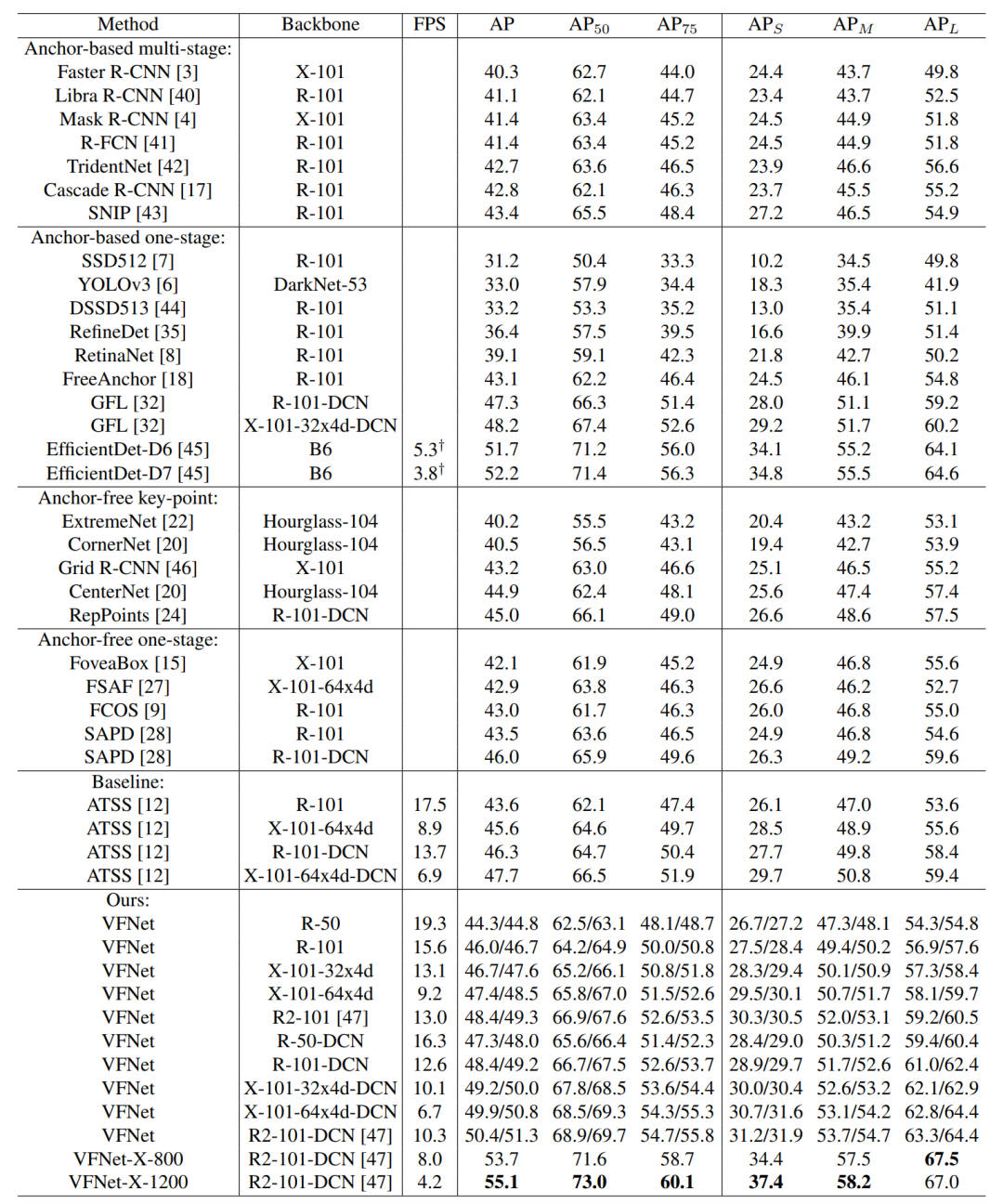
表2 SOTA检测器对比
表2给出了SOTA检测器实验结果对比。与Backbone ATSS相比VFNet在不同Backbone网下实现了大约2.0 AP的提升,例如使用ResNet-101 Backbone时46.0AP和43.6AP,这验证了方法的有效性。
与类似的工作的GFL(其MSTrain标度范围为1333x[480:800])相比,VFNet始终比它好得多。同时用Res2Net-101-DCN训练的模型达到了51.3AP,几乎超过了所有最新的检测器。
文章还给出了VFNet在Nvidia V100 GPU上的推断速度。由于在完全相同的设置下很难得到所有列出的检测器的速度,所以只将VFNet与Baseline ATSS进行比较。可以看出VFNet非常高效,例如以19.3 FPS的速度实现44.8AP,与Baseline相比,只增加了很小的计算开销。
5.3 测试可视化结果

通过上图可以看到,对于小目标和密集目标具有很好的鲁棒性。
6 参考
[1].VarifocalNet: An IoU-aware Dense Object Detector
[2].https://github.com/hyz-xmaster/VarifocalNet
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/115472434

- 点赞
- 收藏
- 关注作者
评论(0)