Lite-HRNet

模型21m,人体检测
Lite-HRNet

paper: https://arxiv.org/abs/2104.06403
code: https://github.com/HRNet/Lite-HRNet
本文是MSRA的研究员针对HRNet的轻量化设计,已被CVPR2021接收。从HRNet与轻量化网络ShuffleNet的组合出发,针对置换模块存在的计算瓶颈问题,提出了一种高效条件通道加权单元替换1x1卷积,并得到了本文的Lite-HRNet。所提Lite-HRNet在人体姿态估计方面取得了最佳的精度-速度均衡,比如在COCO数据集上,Lite-HRNet-30仅需0.7GFLOPs即可取得69.7AP指标;Lite-HRNet-30仅需0.42GFLOPs即可取得87.0 PCKh@0.5的指标。
Abstract
本文提出一种针对人体姿态估计的高效高分辨率网络:Lite-HRNet。我们通过简单的将ShuffleNet中的高效置换模块嵌入到HRNet即可比主流轻量化网络(比如MobileNet、ShuffleNet、Small HRNet)更强的性能。
我们发现:置换模块中重度使用的卷积是其计算瓶颈。我们引入一种轻量化单元(条件通道加权)替换置换模块中计算代价昂贵的卷积。所提通道加权的复杂度与通道数成线性关系,低于卷积的二次时间复杂度关系(比如,在与多分辨率特征方面,所提单元可以减少置换模块总体计算量的80%)。该方案从多个并行分支的所有通道、所有分辨率学习加权值,采用该权值进行通道、分辨率之间的信息交换,补偿卷积所扮演的角色。
实验表明:在人体姿态估计应用方面,相比主流轻量化网络,所提Lite-HR具有更强的性能;更重要的是,所提Lite-HRNet可以以相同方式轻易嵌入到语义分割任务中。
本文主要贡献包含以下几点:
-
通过简单的将ShuffleNet中的置换模块嵌入到HRNet即可得到性能优于其他轻量化方案的基础版Lite-HRNet;
-
通过引入一种高效条件通道加权单元替换置换模块的卷积得到本文所提改进版高效网络Lite-HRNet;
-
在COCO与MPII人体姿态估计方面,所提Lite-HR取得了最佳的复杂度-精度均衡,且可以轻易的推广到语义分割任务中。
Method
Naive Lite-HRNet
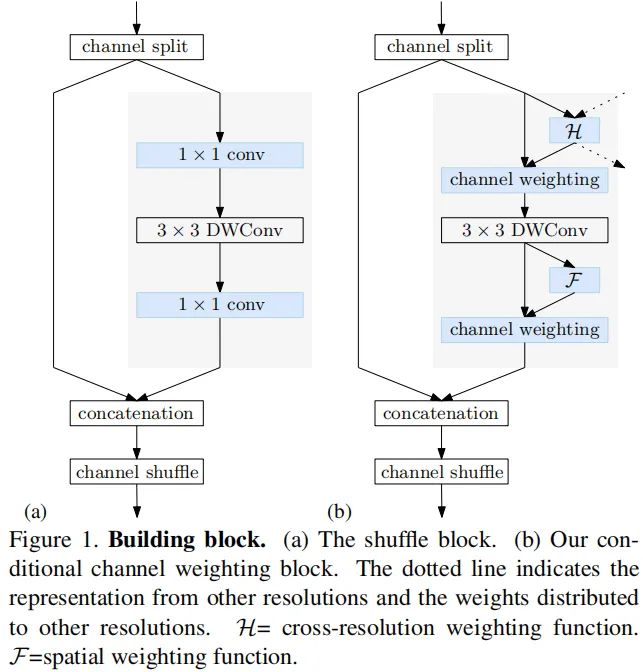
Shuffle Block 上图a给出了ShuffleNetV2中的置换模块示意图,它将输入通道拆分为两部分:一部分经过等卷积处理,一部分不做处理,最后对前述两部分concate结果进行通道置换。
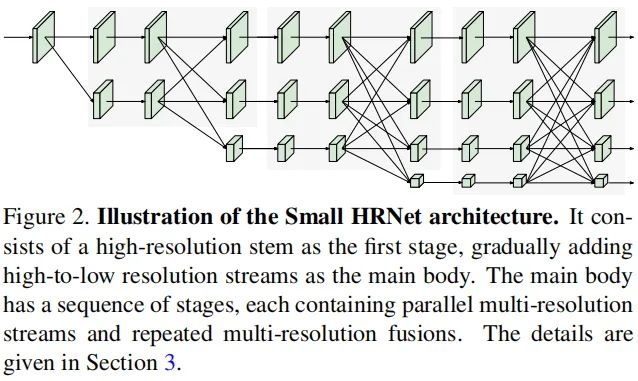
HRNet 上图给出了Small HRNet的网络架构示意图,它采用了渐进式添加高-低分辨率特征并进行不同分辨率特征的融合。
Simple Combination 我们采用置换模块替换Small HRNet的stem部分的第二个卷积,替换所有的残差模块,多分辨率融合部分的卷积采用分离卷积替换,即可得到了基础班Lite-HRNet。
Lite-HRNet
convolution is costly 卷积在每个点进行矩阵-向量乘的计算,描述如下:
由于置换模块中的depthwise卷积(深度卷积)不进行通道间信息交换,故它在置换模块中扮演通道见信息交换的作用。
卷积的计算复杂度是通道数的二次关系,而深度卷积则是线性关系。在置换模块中,两个卷积的复杂度要比深度卷积的更高:。下表给出了卷积与深度卷积的复杂度对比。
![]()
Conditional Channel Weighting 我们提出采用元素级加权操作替换基础版Lite-HRNet中的卷积。对于第s分辨率分支的元素加权操作可以描述如下:
该计算单元的复杂度与通道数成线性关系,要低于卷积的复杂度。实现code如下:
class ConditionalChannelWeighting(nn.Module): def __init__(self, in_channels, stride, reduce_ratio, conv_cfg=None, norm_cfg=dict(type='BN'), with_cp=False): super().__init__() self.with_cp = with_cp self.stride = stride assert stride in [1, 2]
branch_channels = [channel // 2 for channel in in_channels]
self.cross_resolution_weighting = CrossResolutionWeighting( branch_channels, ratio=reduce_ratio, conv_cfg=conv_cfg, norm_cfg=norm_cfg)
self.depthwise_convs = nn.ModuleList([ ConvModule( channel, channel, kernel_size=3, stride=self.stride, padding=1, groups=channel, conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=None) for channel in branch_channels ])
self.spatial_weighting = nn.ModuleList([ SpatialWeighting(channels=channel, ratio=4) for channel in branch_channels ])
def forward(self, x):
def _inner_forward(x): x = [s.chunk(2, dim=1) for s in x] x1 = [s[0] for s in x] x2 = [s[1] for s in x]
x2 = self.cross_resolution_weighting(x2) x2 = [dw(s) for s, dw in zip(x2, self.depthwise_convs)] x2 = [sw(s) for s, sw in zip(x2, self.spatial_weighting)]
out = [torch.cat([s1, s2], dim=1) for s1, s2 in zip(x1, x2)] out = [channel_shuffle(s, 2) for s in out]
return out
if self.with_cp and x.requires_grad: out = cp.checkpoint(_inner_forward, x) else: out = _inner_forward(x)
return out
Cross-resolution weight computation 考虑到第s阶段有s个并行分辨率,我们需要计算s个权值图。我们采用轻量函数对不同分辨率的所有通道计算权值图:
我们通过如下方式实现轻量函数:在上先进行自适应均值池化得到,AAP可以将任意输入尺寸池化到给定输出尺寸;我们将上述所得拼接得到,并经由卷积、ReLU、卷积、Sigmoid生成不同分辨率的加权图。
在这里,每个分辨率每个位置的加权值依赖于均值池化后多分辨率特征同位置的通道特征。这就是为什么我们将该机制称之为跨分辨率权值计算的原因。上采样到对应的分辨率得到用于后续的元素级加权。
这里所提的元素级加权图将起着跨分辨率、通道信息交换的作用。每个位置的加权向量从所有输入接受信息,并与原始的通道进行加权, 描述如下:
换句话说,通道加权机制起着与卷积相同的作用:信息交换。另一方面,函数在是小分辨率上实现的,故而其计算复杂度非常小。实现code如下:
class CrossResolutionWeighting(nn.Module): def __init__(self, channels, ratio=16, conv_cfg=None, norm_cfg=None, act_cfg=(dict(type='ReLU'),dict(type='Sigmoid'))): super().__init__() if isinstance(act_cfg, dict): act_cfg = (act_cfg, act_cfg) assert len(act_cfg) == 2 assert mmcv.is_tuple_of(act_cfg, dict) self.channels = channels total_channel = sum(channels) self.conv1 = ConvModule( in_channels=total_channel, out_channels=int(total_channel / ratio), kernel_size=1, stride=1, conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg[0]) self.conv2 = ConvModule( in_channels=int(total_channel / ratio), out_channels=total_channel, kernel_size=1, stride=1, conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg[1])
def forward(self, x): mini_size = x[-1].size()[-2:] out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]] out = torch.cat(out, dim=1) out = self.conv1(out) out = self.conv2(out) out = torch.split(out, self.channels, dim=1) out = [ s * F.interpolate(a, size=s.size()[-2:], mode='nearest') for s, a in zip(x, out) ] return out
Spatial weight computation 对于每个分辨率,我们同时还计算了空域加权,计算方式如下:
函数包含(其实就是一个SE,见下面的code)。此时的特征加权方式将调整为:
class SpatialWeighting(nn.Module):
def __init__(self, channels, ratio=16, conv_cfg=None, act_cfg=(dict(type='ReLU'),dict(type='Sigmoid'))): super().__init__() if isinstance(act_cfg, dict): act_cfg = (act_cfg, act_cfg) assert len(act_cfg) == 2 assert mmcv.is_tuple_of(act_cfg, dict) self.global_avgpool = nn.AdaptiveAvgPool2d(1) self.conv1 = ConvModule( in_channels=channels, out_channels=int(channels / ratio), kernel_size=1, stride=1, conv_cfg=conv_cfg, act_cfg=act_cfg[0]) self.conv2 = ConvModule( in_channels=int(channels / ratio), out_channels=channels, kernel_size=1, stride=1, conv_cfg=conv_cfg, act_cfg=act_cfg[1])
def forward(self, x): out = self.global_avgpool(x) out = self.conv1(out) out = self.conv2(out) return x * out
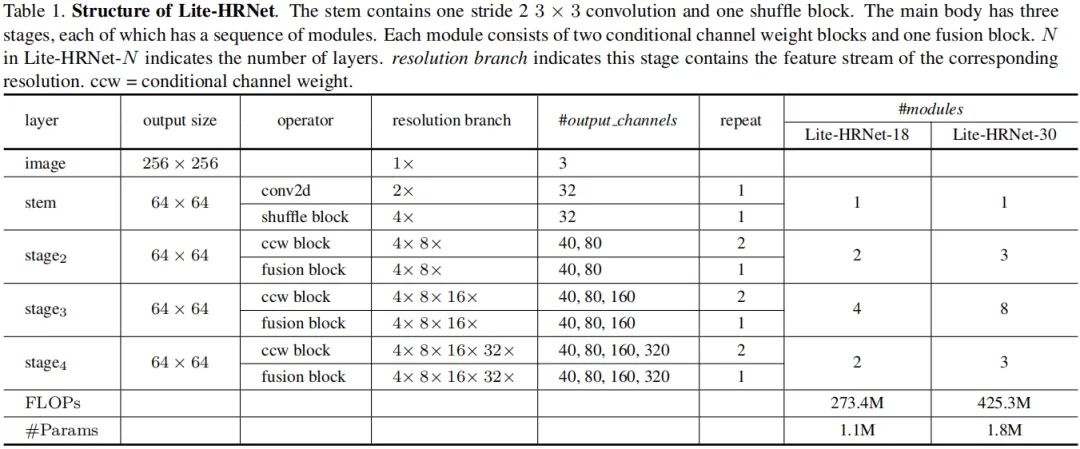
Instantiation Lite-HRNet包含高分辨率Stem和主体两部分,stem由一个stride=2的卷积+置换模块构成;主体部分由一些列模块化的单元构成,每个单元包含两个条件通道加权模块与一个多分辨率融合,每个分辨率对应特征的通道维度为。Lite-HRNet的架构信息见下表。
Connection 本文所提条件加权机制具有与CondConv、动态滤波器、SE等相似的思想:数据自适应性。区别在于:CondConv、动态滤波器以及SE采用自网络学习卷积核或者混合权值并提升模型的容量;而本文方法则探索了额外的作用:采用所学习到的权值对不同分辨率、不同通道见的信息交换进行桥接。它可以用于替换轻量化网络中的耗时的卷积,除此之外,我们还引入了多分辨率信息提升加权学习。
Experiments
我们在COCO与MPII数据集上对所提方法的性能进行了评估,参照主流top-down框架,我们直接估计K个热图。
Dataset COCO具有200K图像,250K具有17个关键点的人体示例。我们在train2017数据集(包含57K图像,150K人体示例)上进行训练,在val2017与test-dev2017数据集上验证;MPII包含25K个全身姿态标注的图像,超40K人体示例,其中12K用于测试,其他用于训练。
Training 人体检测框扩展为比例后裁剪,COCO数据的图像缩放到或者;MPII数据的图像缩放到。此外每个图像还会进行一系列的数据增广:随机旋转、随机缩放、随机镜像等。
Testing 对于COCO数据,我们采用双阶段的top-down框架:即先检测再预测;对于MPII数据,我们采用标准的测试策略(预提供人体框)。
Evaluation 我们采用基于OKS的mAP对COCO进行度量:;对于MPII,我们采用标准度量PCKH@0.5进行性能评估。
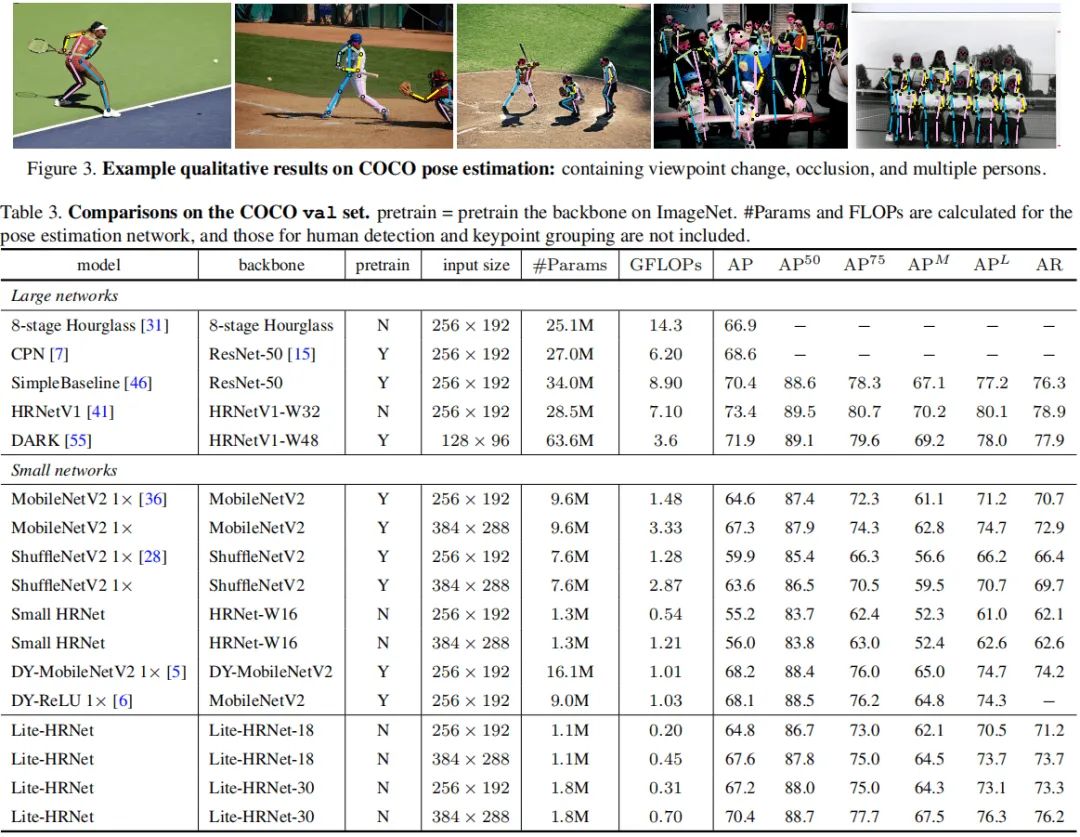
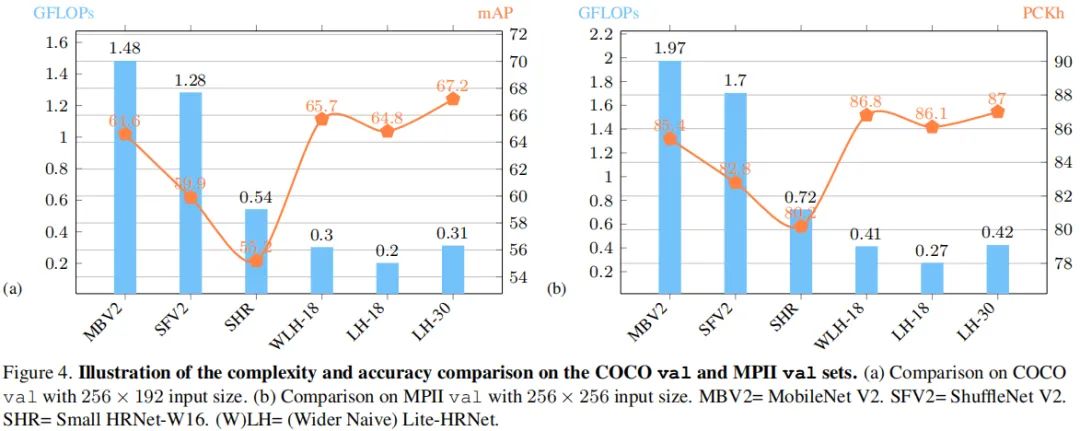
上图给出了COCO验证集上的性能对比,从中可以看到:
-
输入为条件下,Lite-HRNet-30取得了67.2AP指标,优于其他轻量化方案。
-
相比MobileNetV2,性能提升2.6AP,且仅需20%GFLOOs与参数量;
-
相比ShuffleNetV2,Lite-HRNet-18与Lite-HRNet-30分别获得了4.9与7.3指标提升,同时具有更低的计算量;
-
相比Small HRNet-W16,Lite-HRNet指标提升超10AP;
-
相比大网络(比如Hourglass、CPN),所提方法可以取得相当的AP指标且具有极低复杂度。
-
输入为条件下,Lite-HRNet-18与Lite-HRNet-30分别取得了67.6与70.4AP指标;
-
受益于所提高效条件通道加权模块,Lite-HRNet取得了更佳的精度-计算复杂度均衡,可参考下图。
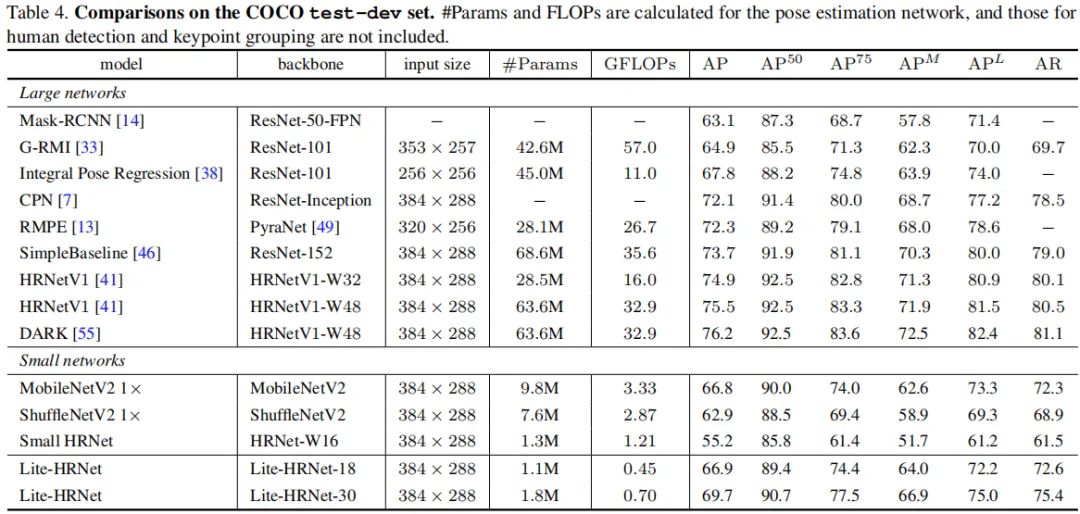
上表给出了COCO-test-dev数据集上的性能对比,可以看到:
-
Lite-HRNet-30取得了69.7AP指标,显著优于其他轻量网络,同时具有更低FLOPs和参数量;
-
Lite-HRNet-30取得了优于Mask-RCNN、G_RMI、IPR等大网络的性能;
-
尽管相比其他大网络,所提方法仍存在性能差异,但所提方法具有超低的GFLOPs与参数量。
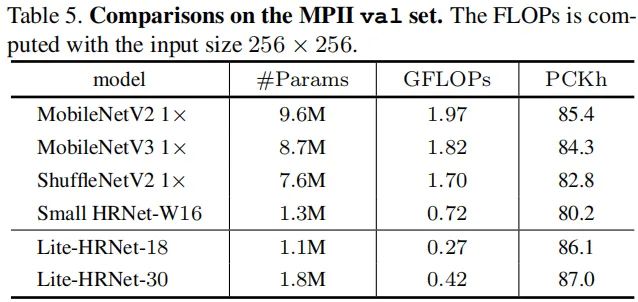
上表给出了MPII验证集上的性能对比,可以看到:
-
相比MobileNet2、MobileNetV3、ShuffleNetV2、Small HRNet等轻量化模型,所提Lite-HRNet-18取得了更高的精度,同时具有更低的计算复杂度;
-
继续提升模型大小可以进一步提升模型的精度,比如Lite-HRNet-30取得了87.0 PCKh@0.5的指标。
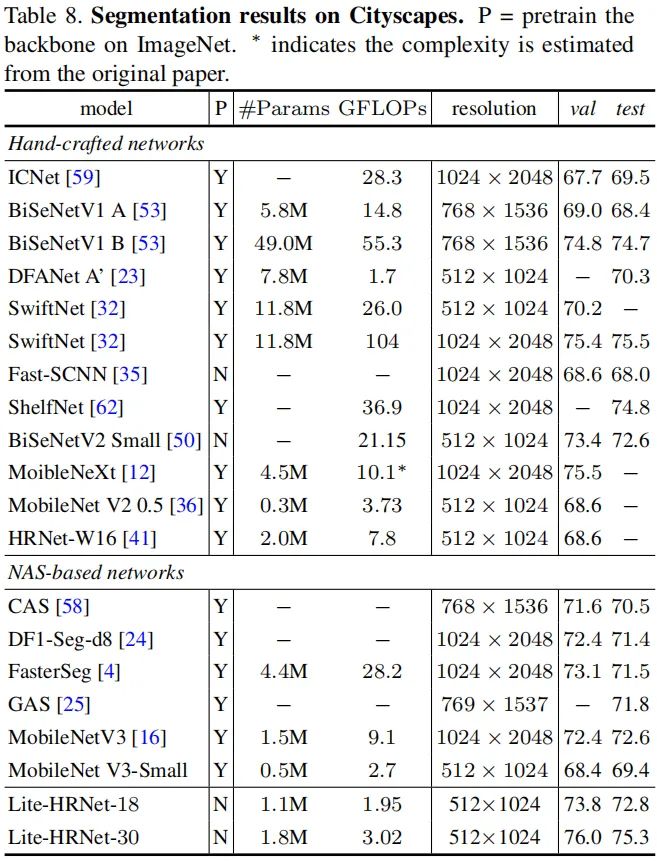
最后,我们再看一下所提方法迁移到语义分割任务上的效果,见上表。可以看到:
-
Lite-HRNet-18以1.95GFLOPs计算量取得72.8%的mIoU指标;
-
Lite-HRNet-30以3.02GFLOPs计算量取得了75.3%的mIoU指标。
-
所提方法优于手工设计网络(如ICNet、BiSeNet、DFANet等)与NAS网络(比如CAS、GAS、FasterSeg等),同时与SwiftNetRN-18性能相当,但具有更低的计算量(3.02 vs 104)。
全文到此结束,更多消融实验与分析建议查看原文。
文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/115711634

- 点赞
- 收藏
- 关注作者
评论(0)