【5月19日】 开源论文代码分享 分割、姿势预测,目标检测

#CVPR 2021##全景分割##开放集#
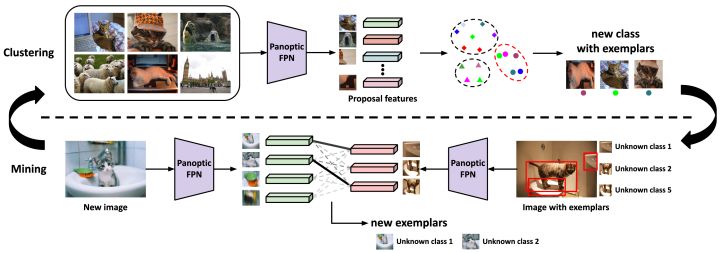
1、Exemplar-Based Open-Set Panoptic Segmentation Network
首尔大学&Adobe Research
先是定义开放集全景分割(OPS)任务,并通过深入分析其固有的挑战,利用合理的假设使其可行。通过重新格式化 COCO 构建一个全新的 OPS 基准,并作为 Panoptic FPN 的变种展示其基线的性能。EOPSN 是基于典范理论的开放集全景分割框架,在检测和分割未知类别的例子方面都是有效的。
已开源:https://github.com/jd730/EOPSN
论文:https://arxiv.org/abs/2105.08336
主页:https://cv.snu.ac.kr/research/EOPSN/
#人体姿势预测#
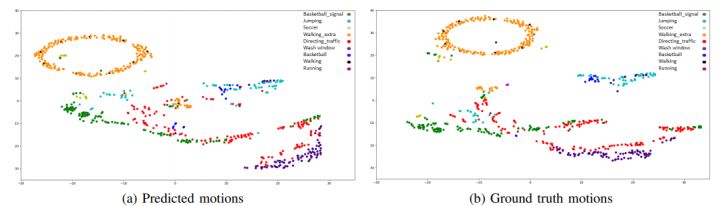
2、Human Motion Prediction Using Manifold-Aware Wasserstein GAN
Univ. Lille
Human motion prediction(人体姿势预测)当前的一些挑战有预测运动的不连续性和长期范围内的性能衰减。本次工作,作者通过使用人类运动的紧凑 manifold-valued 表示来进行解决。实验证明所提出方法在 CMU MoCap和 Human 3.6M 数据集上的表现优于最先进的方法。定性结果也展示了预测运动的平稳性。
已开源:https://drive.google.com/drive/folders/1pQkwtVDBeubW1oPwuXWFOOtftHabKaph
论文:https://arxiv.org/abs/2105.08715
#ICME 2021 oral##显著目标检测#
3、Exploring Driving-aware Salient Object Detection via Knowledge Transfer
北航&鹏城实验室&美团
构建一个全新的数据集:CitySaliency,用于特定任务(驾驶任务) SOD,可以促进 task-aware SOD 的发展。通过知识迁移卷积神经网络提出一个驾驶任务感知 SOD 的基线模型。在这个网络中,构建一个基于注意力的知识迁移模块来弥补知识差异。此外,还引入一个高效的边界感知特征解码模块,对复杂的特定任务场景中的目标进行细致的特征解码。整个网络以一种渐进的方式整合了知识迁移和特征解码模块。实验证明所提出方法在该数据集上的表现优于 12 种最先进的方法,促进了任务感知 SOD 的发展。
将开源:http://cvteam.net/papers.html
论文:https://arxiv.org/abs/2105.08286

#图像分割#
4、Finding an Unsupervised Image Segmenter in Each of Your Deep Generative Models
牛津大学学者开发一个自动程序用于寻找导致前景和背景分离的动向,并使用这些动向来训练图像分割模型,无需人工监督。该方法是 generator-agnostic(与生成器无关),在各种不同的 GAN 架构下都能产生强大的分割结果。此外,通过利用在 ImageNet 等大型数据集上预训练的 GANs,能够对一系列领域的图像进行分割,而无需进一步的训练或微调。在图像分割基准上对所提出方法进行评估,与之前的工作相比,既不需要人工监督,也不使用训练数据。总的来说,从预训练的深度生成模型中自动提取前景-背景结构可以作为人类监督的一个非常有效的替代。
将开源:https://github.com/lukemelas/unsupervised-image-segmentation
主页:https://lukemelas.github.io/unsupervised-image-segmentation/
论文:https://arxiv.org/abs/2105.08127

#视频#
5、VPN++: Rethinking Video-Pose embeddings for understanding Activities of Daily Living
石溪大学&Inria and Universite Cote d’Azur
Video-Pose Network(VPN),是姿势驱动的注意力机制的扩展,可用于对不同方向进行探索,一个是通过特征级蒸馏将 Pose knowledge 迁移到 RGB 中,一个是通过注意级蒸馏模仿姿势驱动的注意力。然后将它们整合为一个单一的模型:VPN++。实验验证 VPN++ 不仅有效,而且还提供了高速度和对噪声姿势的高弹性。无论有无 3D姿势,VPN++ 在 4 个公共数据集上的表现都优于代表性的基线。
已开源:https://github.com/srijandas07/vpnplusplus
论文:https://arxiv.org/abs/2105.08141

#ICDAR 2021##表单理解#
6、Visual FUDGE: Form Understanding via Dynamic Graph Editing
杨百翰大学&Adobe Research
FUDGE,是一种可视化的表单理解方法,通过结合文本片段(图形顶点)和以迭代的方式修剪边缘来编辑图形结构,以获得最终的文本实体和关系。可以应用于文本识别困难的表单(如降质的或历史表单),以及因为预训练一些语言模型是具有挑战性的资源匮乏的语言表单。FUDGE 在历史题材 NAF 数据集上是最先进的。
将开源:https://github.com/herobd/FUDGE
论文:https://arxiv.org/abs/2105.08194

文章来源: blog.csdn.net,作者:网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/117041542

- 点赞
- 收藏
- 关注作者
评论(0)