高可用的微服务架构设计-资源隔离、限流、熔断、降级、监控

断路器模式
舱壁隔离模式
容错理念
- 凡是依赖都可能会失败
- 凡是资源都有限制
- CPU/Memory/Threads/Queue
- 网络并不可靠,延迟是应用稳定性杀手
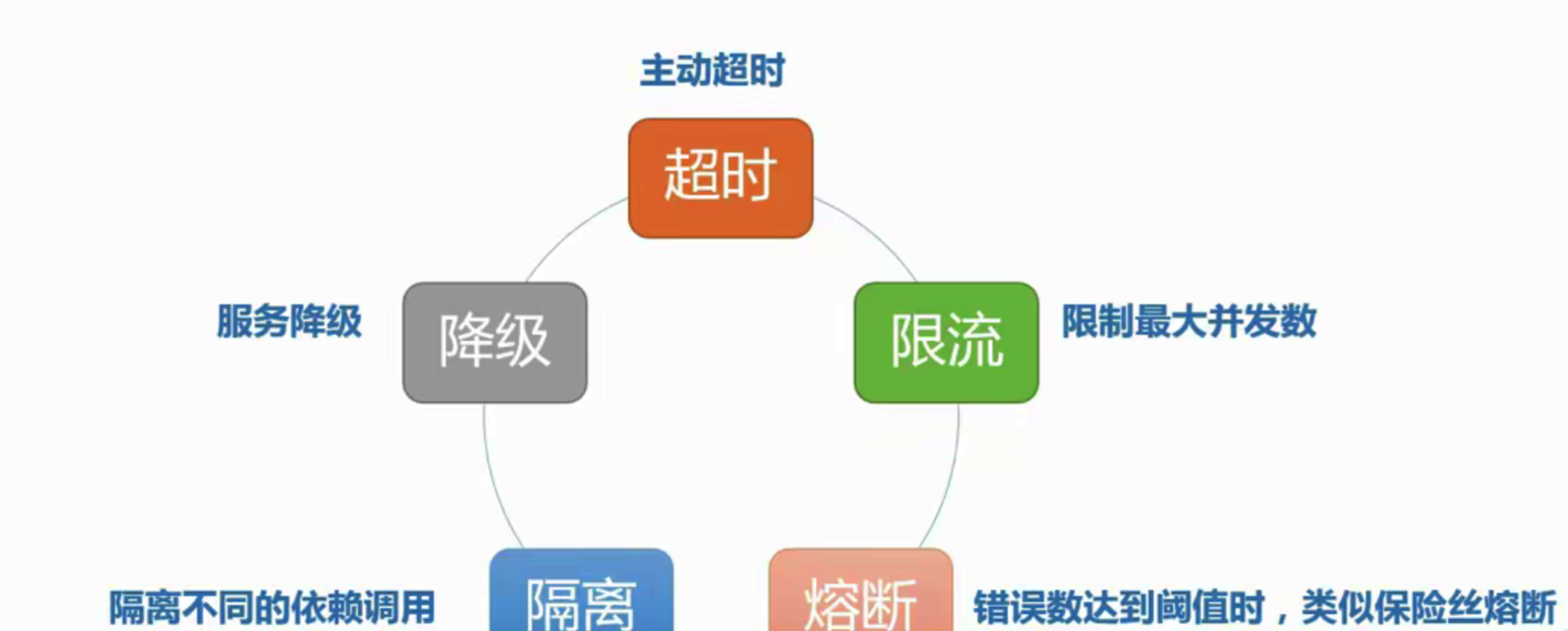
1 资源隔离
让你的系统里,某一块东西,在故障的情况下,不会耗尽系统所有的资源,比如线程资源
项目中的一个case,有一块东西,是要用多线程做一些事情,小伙伴做项目的时候,没有太留神,资源隔离,那块代码,在遇到一些故障的情况下,每个线程在跑的时候,因为那个bug,直接就死循环了,导致那块东西启动了大量的线程,每个线程都死循环
最终导致系统资源耗尽,崩溃,不工作,不可用,废掉了
资源隔离,那一块代码,最多最多就是用掉10个线程,不能再多了,就废掉了,限定好的一些资源
2 限流
对打入服务的请求流量进行控制,使服务能够承担不超过自己能力的流量压力。
高并发的流量涌入进来,比如说突然间一秒钟100万QPS,废掉了,10万QPS进入系统,其他90万QPS被拒绝了
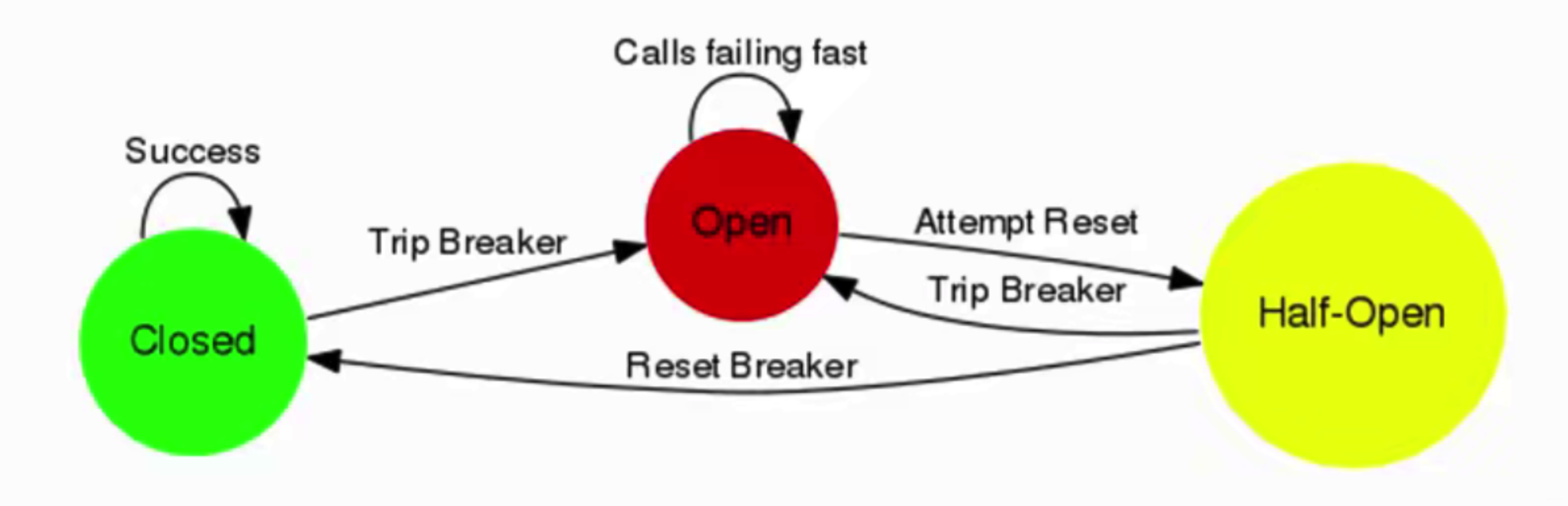
3 熔断
A服务调用B服务的某个功能,由于网络不稳定问题,或者B服务卡机,导致功能时
间超长。如果这样的次数太多。我们就可以直接将B断路(A不再请求B接口),凡是
调用B的直接返回降级数据,不必等待B的超长执行。这样B的故障问题,就不会级联影
响到A。
依赖服务,出了一些故障,每次请求都报错,熔断它,后续的请求过来直接不接收了,拒绝访问,10分钟之后再尝试去看看接口是否恢复。
4 降级
整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级[停止服务,所有的调用直接返回降级数据]。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的响应。
MySQL挂了,系统发现了,自动降级,从内存里存的少量数据中,去提取一些数据出来。
和熔断的异同
相同点
- 为了保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲小我
- 用户最终都是体验到某个功能不可用
不同点
- 熔断是被调用方故障,触发的系统主动规则
- 降级是基于全局考虑,停止一些正常服务,释放资源
5 运维监控
监控+报警+优化,各种异常的情况,有问题就及时报警,优化一些系统的配置和参数,或者代码
如果你的各种依赖的服务有了故障,那么很可能会导致你的系统不可用
hystrix对系统进行各种高可用性的系统加固,来应对各种不可用的情况
最佳实践
- 网关集中埋点,覆盖大部分场景
- 尽量框架集中埋点,客户端为主
- 配置对接Apollo ,根据实际使用调整阀值
- 信号量vs线程池场景
- 信号量:网关,缓存
- 线程池场景:服务间调用客户端,数据库访问,第三方访问
- 线程池大小经验值
- 30rps x0.2sec= 6 + breathing room = 10 threads
- Thread-pool Queue size:5 ~ 10
- 部署
- Hystrix Dashboard大盘(无线/H5/第3三方网关)
- 共享Hystrix Dashboard/Turbine服务器
- 熔断告警
- Spring Cloud Hystrix标注
文章来源: javaedge.blog.csdn.net,作者:JavaEdge.,版权归原作者所有,如需转载,请联系作者。
原文链接:javaedge.blog.csdn.net/article/details/95803214

- 点赞
- 收藏
- 关注作者
评论(0)