MySQL的count()函数及其优化

很简单,就是为了统计记录数
由SELECT返回
为了理解这个函数,让我们祭出 employee_tbl 表
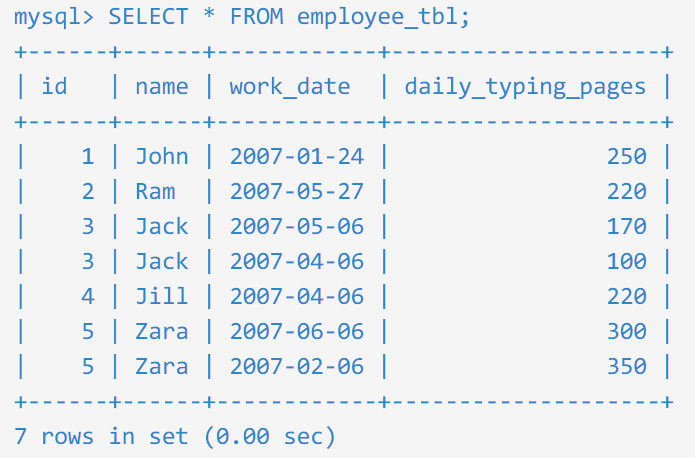
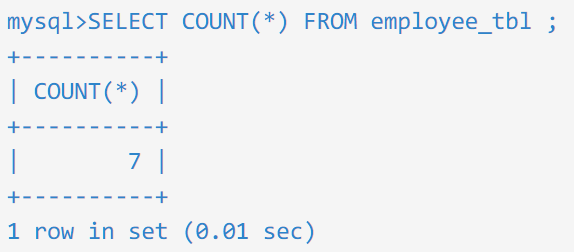
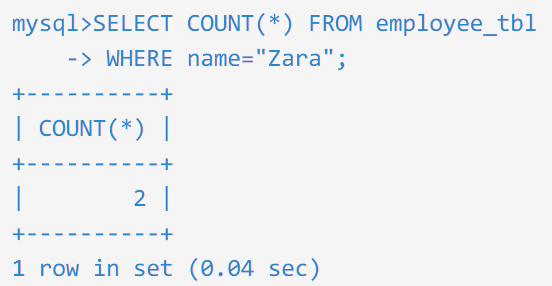
注意:由于 SQL 查询对大小写不敏感,所以在 WHERE 条件中,无论是写成 ZARA 还是 Zara,结果都是一样的
count(1),count(*),count(字段)区别
count(1)和count(*)
作用
都是检索表中所有记录行的数目,不论其是否包含null值
区别
count(1)比count(*)效率高
二 . count(字段)与count(1)和count(*)的区别
count(字段)的作用是检索表中的这个字段的非空行数,不统计这个字段值为null的记录
-
任何情况下SELECT COUNT(1) FROM tablename是最优选择
-
尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种
-
杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现
-
如果表没有主键,那么count(1)比count(*)快
-
如果有主键,那么count(主键,联合主键)比count(*)快
-
如果表只有一个字段,count(*)最快
count(1)跟count(主键)一样,只扫描主键。
count(*)跟count(非主键)一样,扫描整个表
明显前者更快一些。
执行效果:
- count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count()用时多了!
从执行计划来看,count(1)和count()的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(),自动会优化指定到那一个字段。所以没必要去count(1),用count(),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
- count(1) and count(字段)
两者的主要区别是
(1) count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
count(*) 和 count(1)和count(列名)区别
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count()
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count()最优。
实例
mysql> create table counttest(name char(1), age char(2));
Query OK, 0 rows affected (0.03 sec)
mysql> insert into counttest values -> ('a', '14'),('a', '15'), ('a', '15'), -> ('b', NULL), ('b', '16'), -> ('c', '17'), -> ('d', null), ->('e', '');
Query OK, 8 rows affected (0.01 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> select * from counttest;
+------+------+
| name | age |
+------+------+
| a | 14 |
| a | 15 |
| a | 15 |
| b | NULL |
| b | 16 |
| c | 17 |
| d | NULL |
| e | |
+------+------+
8 rows in set (0.00 sec)
mysql> select name, count(name), count(1), count(*), count(age), count(distinct(age)) -> from counttest -> group by name;
+------+-------------+----------+----------+------------+----------------------+
| name | count(name) | count(1) | count(*) | count(age) | count(distinct(age)) |
+------+-------------+----------+----------+------------+----------------------+
| a | 3 | 3 | 3 | 3 | 2 |
| b | 2 | 2 | 2 | 1 | 1 |
| c | 1 | 1 | 1 | 1 | 1 |
| d | 1 | 1 | 1 | 0 | 0 |
| e | 1 | 1 | 1 | 1 | 1 |
+------+-------------+----------+----------+------------+----------------------+
5 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
MyISAM有表元数据的缓存,例如行,即COUNT()值,对于MyISAM表的COUNT()无需消耗太多资源,但对于Innodb,就没有这种元数据,CONUT(*)执行较慢。
文章来源: javaedge.blog.csdn.net,作者:JavaEdge.,版权归原作者所有,如需转载,请联系作者。
原文链接:javaedge.blog.csdn.net/article/details/108932357

- 点赞
- 收藏
- 关注作者
评论(0)