Elasticsearch 学习笔记(一)-----Lucene的简介以及索引原理

概述
今天,正式开始学习Elasticsearch,因为Elasticsearch是用Lucene来实现索引的查询功能的,所以,理解Lucene的原理显的尤为重要。
Lucene 简介
Lucene 是一个开源的全文检索引擎工具包。它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,它提供了完整的查询引擎和索引引擎,部分文本分析引擎。
索引说明
索引,可以想象成一种数据结构,使你快速的随机访问存储在索引中的关键词,进而找到关键词所关联的文档。Lucene 采用的一种称为倒排索引(Invered index)的机制,倒排索引就是说我们维护了一个词/短语表,对于这个词/短语表,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就可以非常快的得到搜索结果。
对文档建立好索引之后,就可以在这些索引上面进行搜索,搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
建立索引相关概念
为了对文档进行索引,Lucene 提供了5个基础的类,Document;Field;Analyzer;IndexWriter;Directory,下面我们分别介绍这几个类的功能。
Document
用来描述文档,此处的文档可以理解为数据库的一条记录,一篇文章。一个Document 对象由多个Field 对象组成。比如说,一篇文章是一个文档的话,那么,其标题,正文,标签就分别对应一个个Field对象。整体组成一个文档对象。
Field
用来描述一个文档的某个属性。比如文章的标题就对应一个Field。
Analyzer
在一个文档被索引之前,首先需要对文档进行分词处理,这部分工作就是由Analyzer(分词器)来做的。
IndexWriter
核心类,作用是把一个个Document对象加到索引中
Directory
这个类代表了Lucene 的索引存储的位置,这是一个抽象类,其有两个实现类,其中FSDirectory 类,表示一个存储在文件系统中的索引的位置,另外一个RAMDirectory 类表示一个存储在内存中的索引的位置。
构建索引的总体流程
- 为每一个待检索的文件构建Document对象,将文件中各部分内容作为Field类对象
- 使用Analyzer类实现对文档中的自然语言文本进行分词处理,并使用IndexWriter 类构建索引
- 使用FSDirectory 类设定索引存储的方式和位置,实现索引的存储
查询文档相关概念
Lucene 提供了几个基础的类来完成 在索引上进行搜索以查找包含某个关键词或短语的文档的过程。他们分别是IndexSearcher,Term, Query,TermQuery,Hits。 下面我们分别介绍这几个类的功能。
Query
这是一个抽象类,他有多个子类,比如:TermQuery,BooleanQuery,PrefixQuery,MultiTermQuery等等。这个类的目的是把用户输入的查询字符串封装成Lucene 能够识别的Query。
Term
Term 是搜索的基本单位,一个Term对象有两个String 类型的域组成。生成一个Term 对象可以有如下一条语句来完成:Term term=new Term(“fieldName”,“queryWorld”);其中第一个参数代表了要在文档的哪一个Field上进行查找,第二个参数代表了要查询的关键词。
TermQuery
TermQuery是抽象类Query的一个子类,它同时也是Lucene支持的最为基本的一个查询类。 Query query = new TermQuery(new Term(“fieldName”,“queryWorld”)); 它的构造函数只接收一个参数,那就是Term。
IndexSearcher
IndexSearcher 是用来在建立好的索引上进行搜索的,它只能以只读的方式打开一个索引,所以可以有多个IndexSearcher 的实例在一个索引上进行操作。
Hits
Hits 是用来保存搜索的结果的。
在索引上查询的流程如下:
- 使用IndexReader类读取索引
- 使用Term类表示用户所查找的关键词以及关键词所在的字段,使用QueryParser类表示用户的查询条件。使用Term类表示用户所查找的关键词以及关键词所在的字段,使用QueryParser类表示用户的查询条件。
- 对关键词进行分词。
- 使用IndexSearcher类检索索引,返回符合查询条件的Document类对象。
倒排索引
正如前面所说Lucene 采用的是倒排索引的机制,由属性值来确定记录的位置,而不是由记录确定属性。
如图所示:

具体参考倒排索引原理和实现
索引时
以live 这行为例我们说明下该结构:live在文章1中出现了2次,文章2中出现了一次,它的位置为“2,5,2”,这表示什么呢?我们需要结合文章号和出现频率来分析啊,文章1出现了2次,那么“2,5” 就表示live在文章1中出现的两个位置,文章2中出现了一次,那么剩下的“2” 就表示live是文章2中第2个关键词
我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二分搜索算法快速定位关键词
实现
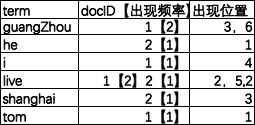
lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键词的频率信息和位置信息。
Lucene 中使用了field的概念,用于表达信息所在的位置(如标题中,文章中,url中),在建索引中,该field 信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)
一个简单的demo
新建一个maven项目,引入Lucene 的依赖,版本为7.4.0。
- POM文件中的依赖如下:
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.4.0</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.4.0</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 建立索引
public class CreateTest { public static void main(String[] args) throws Exception {
// Path indexPath = FileSystems.getDefault().getPath("d:\\index\\"); Path indexPath = FileSystems.getDefault().getPath("/Volumes/Develop/index");
// FSDirectory有三个主要的子类,open方法会根据系统环境自动挑选最合适的子类创建
// MMapDirectory:Linux, MacOSX, Solaris
// NIOFSDirectory:other non-Windows JREs
// SimpleFSDirectory:other JREs on Windows Directory dir = FSDirectory.open(indexPath); // 分词器 Analyzer analyzer = new StandardAnalyzer(); boolean create = true; IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); if (create) { indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE); } else { // lucene是不支持更新的,这里仅仅是删除旧索引,然后创建新索引 indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); } IndexWriter indexWriter = new IndexWriter(dir, indexWriterConfig); Document doc = new Document(); // 域值会被索引,但是不会被分词,即被当作一个完整的token处理,一般用在“国家”或者“ID // Field.Store表示是否在索引中存储原始的域值 // 如果想在查询结果里显示域值,则需要对其进行存储 // 如果内容太大并且不需要显示域值(整篇文章内容),则不适合存储到索引中 doc.add(new StringField("Title", "sean", Field.Store.YES)); long time = new Date().getTime(); // LongPoint并不存储域值 doc.add(new LongPoint("LastModified", time));
// doc.add(new NumericDocValuesField("LastModified", time)); // 会自动被索引和分词的字段,一般被用在文章的正文部分 doc.add(new TextField("Content", "this is a test of sean", Field.Store.NO)); List<Document> docs = new LinkedList<>(); docs.add(doc); indexWriter.addDocuments(docs); // 默认会在关闭前提交 indexWriter.close(); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
运行结果:

构建索引时序图如下

4. 在建立好的索引上进行搜索
public class QueryTest { public static void main(String[] args) throws Exception {
// Path indexPath = FileSystems.getDefault().getPath("d:\\index\\"); Path indexPath = FileSystems.getDefault().getPath("/Volumes/Develop/index"); Directory dir = FSDirectory.open(indexPath); // 分词器 Analyzer analyzer = new StandardAnalyzer(); IndexReader reader = DirectoryReader.open(dir); IndexSearcher searcher = new IndexSearcher(reader); // 同时查询多个域 String[] queryFields = {"Title", "Content", "LastModified"}; QueryParser parser = new MultiFieldQueryParser(queryFields, analyzer); Query query = parser.parse("sean 123"); // 一个域按词查doc
// Term term = new Term("Title", "sean");
// Query query = new TermQuery(term); // 模糊查询
// Term term = new Term("Title", "se*");
// WildcardQuery query = new WildcardQuery(term); // 范围查询
// Query query1 = LongPoint.newRangeQuery("LastModified", 1L, 1637069693000L);
// 多关键字查询,必须指定slop(key的存储方式)
// PhraseQuery.Builder phraseQueryBuilder = new PhraseQuery.Builder();
// phraseQueryBuilder.add(new Term("Content", "test"));
// phraseQueryBuilder.add(new Term("Content", "sean"));
// phraseQueryBuilder.setSlop(10);
// PhraseQuery query2 = phraseQueryBuilder.build();
//
// // 复合查询
// BooleanQuery.Builder booleanQueryBuildr = new BooleanQuery.Builder();
// booleanQueryBuildr.add(query1, BooleanClause.Occur.MUST); //and
// booleanQueryBuildr.add(query2, BooleanClause.Occur.MUST); //and
// BooleanQuery query = booleanQueryBuildr.build(); // 返回doc排序 // 排序域必须存在,否则会报错 Sort sort = new Sort(); SortField sortField = new SortField("Title", SortField.Type.SCORE); sort.setSort(sortField); TopDocs topDocs = searcher.search(query, 10, sort); if(topDocs.totalHits > 0) for(ScoreDoc scoreDoc : topDocs.scoreDocs){ int docNum = scoreDoc.doc; Document doc = searcher.doc(docNum); System.out.println(doc.toString()); } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
运行结果:

查询索引时序图如下:

总结
本文首先对Lucene 做了简介,然后对建立索引和查询文档的基本类做了详细说明,接着,对倒排索引做了详细阐述,最后就是通过一个demo来说明Lucene的使用。
参考资料
https://www.ibm.com/developerworks/cn/java/j-lo-lucene1/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/inverted-index.html
倒排索引原理和实现
文章来源: feige.blog.csdn.net,作者:码农飞哥,版权归原作者所有,如需转载,请联系作者。
原文链接:feige.blog.csdn.net/article/details/87536104

- 点赞
- 收藏
- 关注作者
评论(0)