没有窗口函数,MySQL应该怎么实现《分组排名》呢?

【摘要】 1.数据源
2.数据整体排名
1)普通排名
从1开始,按照顺序一次往下排(相同的值也是不同的排名)。
set @rank =0;
select
city ,
score,
@rank := @rank+1 rank
from cs
order by score desc;
1234567
结果如下:
2)并列排名
相同的值是相同的排名(...
1.数据源
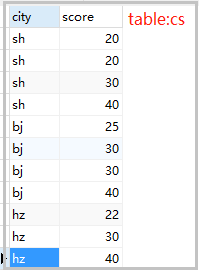
2.数据整体排名
1)普通排名
从1开始,按照顺序一次往下排(相同的值也是不同的排名)。
set @rank =0;
select
city ,
score,
@rank := @rank+1 rank
from cs
order by score desc;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
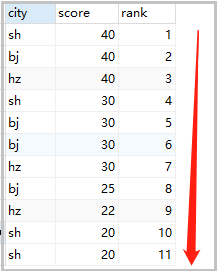
2)并列排名
相同的值是相同的排名(但是不留空位)。
set @rank=0,@price=null;
select cs.* ,
case when @price = score then @rank
when @price := score then @rank := @rank+1 end rank from cs order by score desc;
-- 当查询的score 值 = @price时,输出@rank,
-- 当不等时,将score值赋给@price ,并输出@rank := @rank+1
-- 或者
set @rank=0,@price=null;
select
a.city,a.score,a.rank
from
(select cs.*,
@rank := if(@p=score,@rank,@rank+1) rank,
@p := score
from cs
order by score desc) a;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果如下:
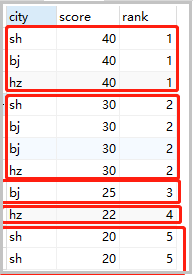
3)并列排名
相同的值是相同的排名(但是留空位)。
set @rank=0,@price=null, @z=1;
select
a.city,a.score,a.rank
from
(select
cs.*,
@rank := if(@p=score,@rank,@z) rank,
@p := score,@z :=@z+1
from cs
order by score desc) a;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果如下:
3.数据分组后组内排名
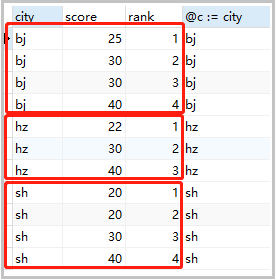
1)分组普通排名
从1开始,按照顺序一次往下排(相同的值也是不同的排名)。
set @rank=0,@c=null;
select
cs.city,cs.score,
@rank := if(@c = city,@rank+1,1) rank,
@c := city
from cs
order by cs.city,cs.score;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
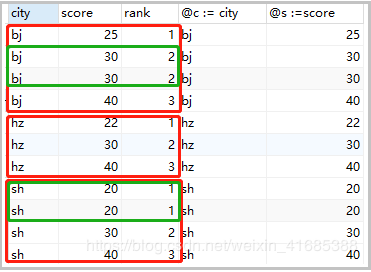
2)分组后并列排名
组内相同数值排名相同,不占空位。
set @rank=0,@c=null,@s=null;
select
cs.city,cs.score,
@rank := if(@c=city,if(@s=score,@rank,@rank+1),1) rank ,
@c := city,
@s :=score
from cs
order by cs.city,cs.score;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果如下:
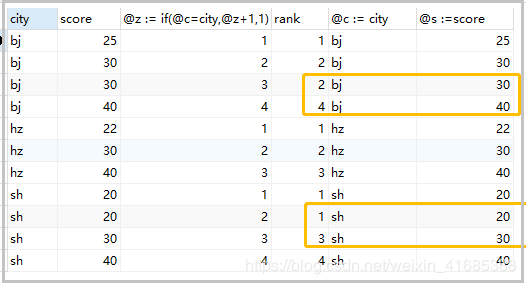
3)分组后并列排名
组内相同数值排名相同,需要占空位。
set @rank=0,@z=0,@c=null,@s=null;
select
cs.city,cs.score,
@z := if(@c=city,@z+1,1),
@rank := if(@c=city,if(@s=score,@rank,@z),1) rank,
@c := city,
@s :=score
from cs
order by cs.city,cs.score;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果如下:
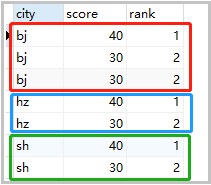
4.分组后取各组的前两名
① 方法一:按照分组排名的三种方式,然后限定排名的值
set @rank=0,@z=0,@c=null,@s=null;
select a.city,a.score,a.rank from
(select
cs.city city,cs.score score,
@z := if(@c=city,@z+1,1),
@rank := if(@c=city,if(@s=score,@rank,@z),1) rank,
@c := city,
@s :=score
from cs
order by cs.city,cs.score desc) a
where a.rank<=2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
② 内部查询
SELECT * FROM cs c
WHERE ( SELECT count(*) FROM cs WHERE c.city=cs.city AND c.score<cs.score )<2
ORDER BY city,score DESC;
- 1
- 2
- 3
- 4
- 5
结果如下:

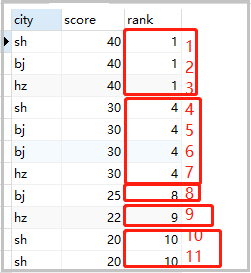
上述代码的执行原理如下图:

文章来源: blog.csdn.net,作者:数据分析与统计学之美,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_41261833/article/details/106728135

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)