DataFrame(5):DataFrame元素的获取方式(很重要)

【摘要】 1、学习DataFrame元素获取,需要掌握以下几个需求
访问一列 或 多列访问一行 或 多行访问某个值访问某几行中的某几列访问某几列中的某几行
2、构造一个DataFrame
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=...
1、学习DataFrame元素获取,需要掌握以下几个需求
- 访问一列 或 多列
- 访问一行 或 多行
- 访问某个值
- 访问某几行中的某几列
- 访问某几列中的某几行
2、构造一个DataFrame
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=["武汉","天门", "黄冈","孝感","广水"])
display(df)
- 1
- 2
- 3
- 4
结果如下:
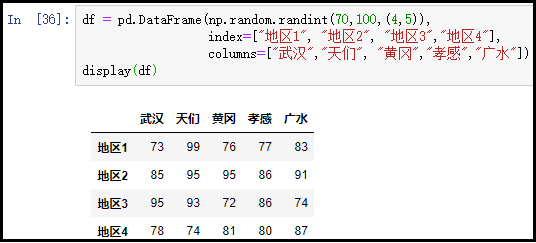
注意:不管是单独获取到一行、还是一列,得到的都是一个Series。不管是单独获取到多行、还是多列,得到的都是一个DataFrame。
# 获取一列
x = df["广水"]
display(x)
display(type(x))
# 获取一行
y = df.loc["地区1"]
display(y)
display(type(y))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果如下:
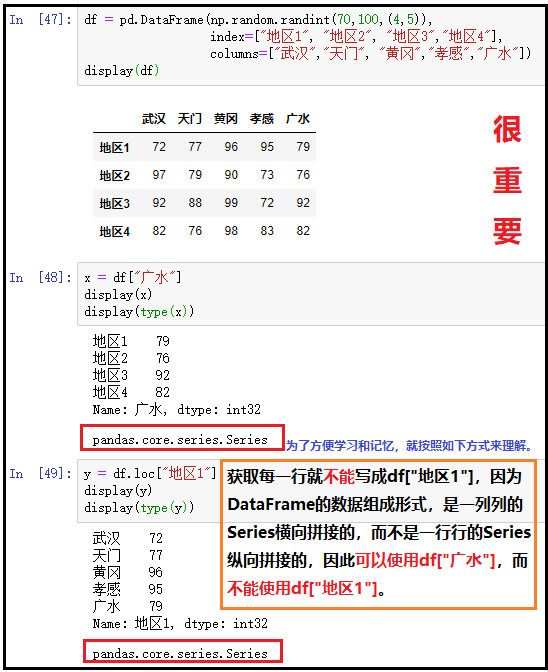
3、访问一列或多列:传入单个标签或标签数组
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=["武汉","天门", "黄冈","孝感","广水"])
display(df)
# 访问一列
x = df["武汉"]
display(x)
# 访问多列
y = df[["武汉","天门"]]
display(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果如下:
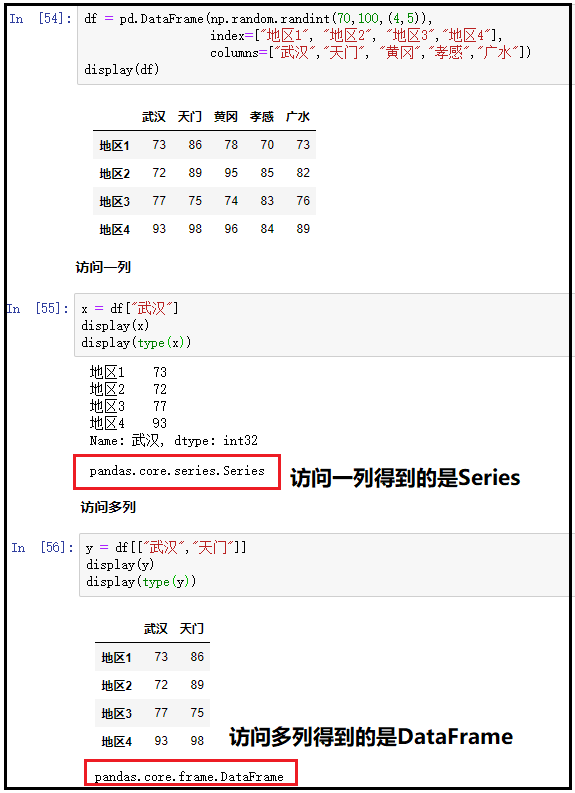
4、访问一行或者多行:loc中传入标签索引、iloc中传入位置索引、切片方式、布尔数组方式
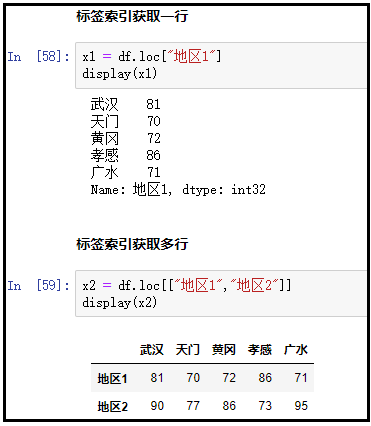
① loc标签索引
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=["武汉","天门", "黄冈","孝感","广水"])
display(df)
x1 = df.loc["地区1"]
display(x1)
x2 = df.loc[["地区1","地区2"]]
display(x2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果如下:
特别说明:“访问行”唯独不能使用类似df[0],df[[0,1]],df[“地区1”],df[[“地区1”,“地区2”]]这样的方式。
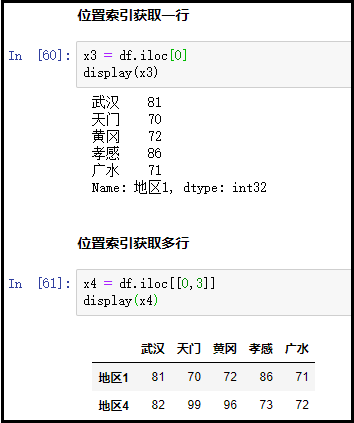
② iloc位置索引
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=["武汉","天门", "黄冈","孝感","广水"])
display(df)
x3 = df.iloc[0]
display(x3)
x4 = df.iloc[[0,3]]
display(x4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果如下:
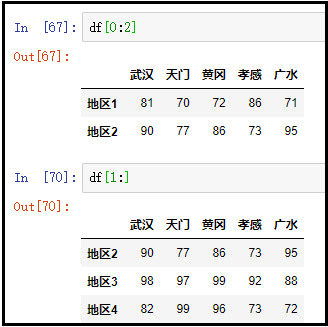
③ 切片方式:这种方式容易忽略,也容易弄错
df[0:2]
df[1:]
- 1
- 2
结果如下:
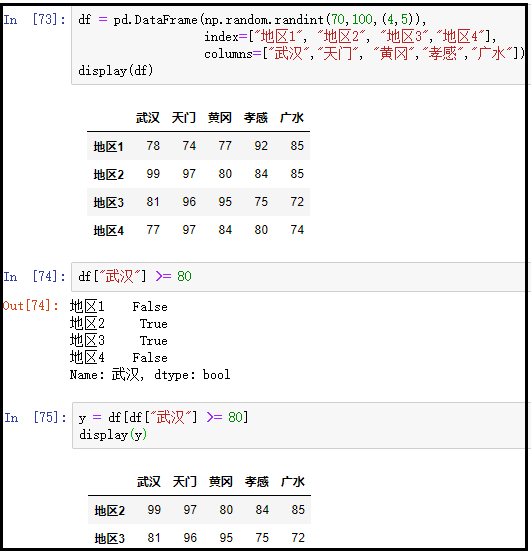
④ 布尔数组方式
df = pd.DataFrame(np.random.randint(70,100,(4,5)), index=["地区1", "地区2", "地区3","地区4"], columns=["武汉","天门", "黄冈","孝感","广水"])
display(df)
y = df[df["武汉"] >= 80]
display(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
5、访问某个值
如果说要访问下面数据框DataFrame中的95,应该怎么做呢?
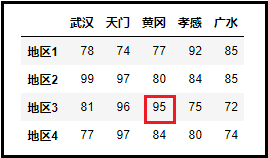
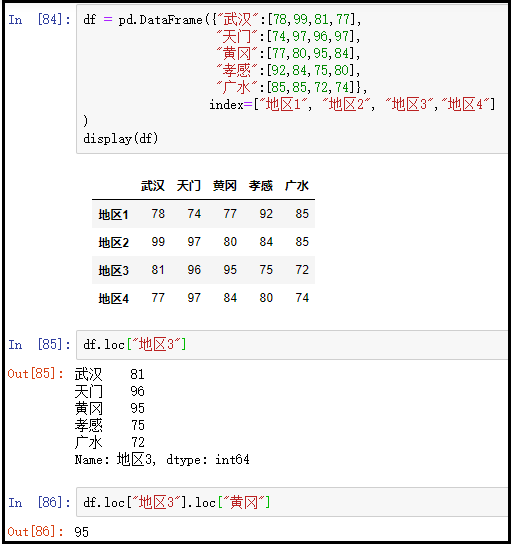
① 先访问“地区3”这一行,再访问95这个数据
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
df.loc["地区3"]
df.loc["地区3"].loc["黄冈"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
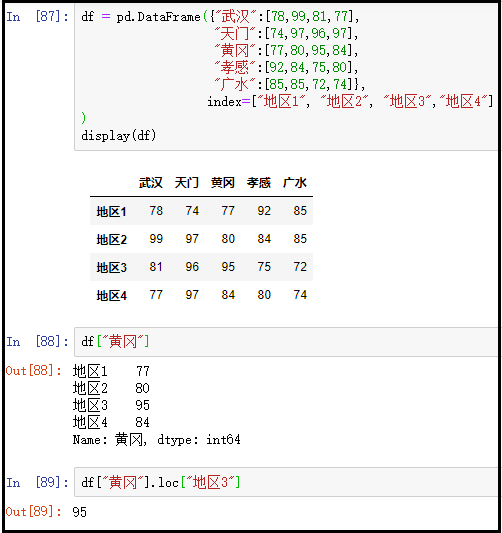
② 先访问“黄冈”这一列,再访问95这个数据
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
df["黄冈"]
df["黄冈"].loc["地区3"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
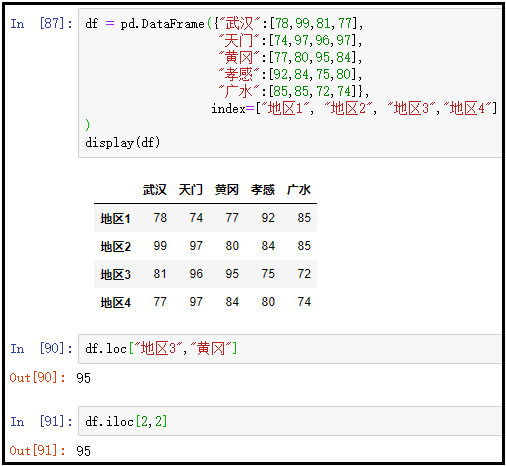
③ 向loc中传入数据的标签坐标、向iloc中传入数据的位置坐标(最常用)
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
df.loc["地区3","黄冈"]
df.iloc[2,2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
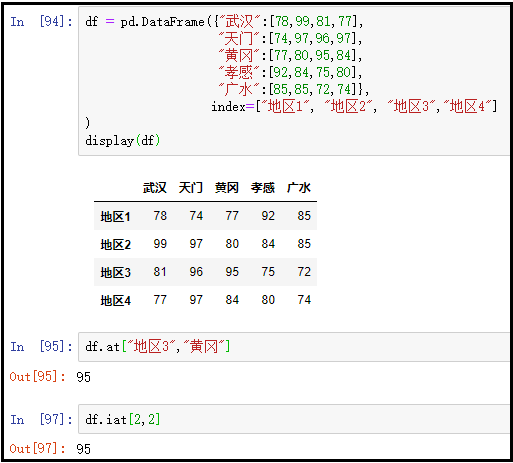
④ 向at中传入数据的标签坐标、向iat中传入数据的位置坐标
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
df.at["地区3","黄冈"]
df.iat[2,2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
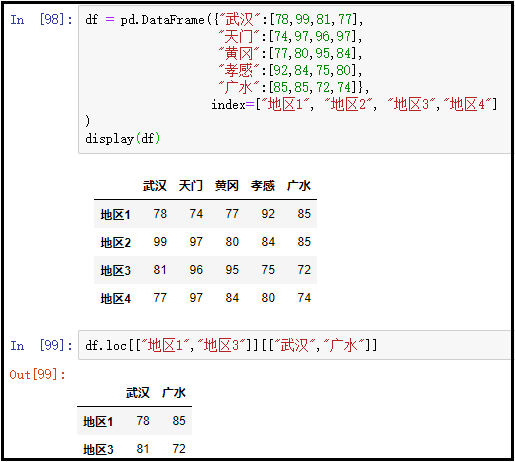
6、访问某几行中的某几列
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
# 先获取行,再获取列
df.loc[["地区1","地区3"]][["武汉","广水"]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
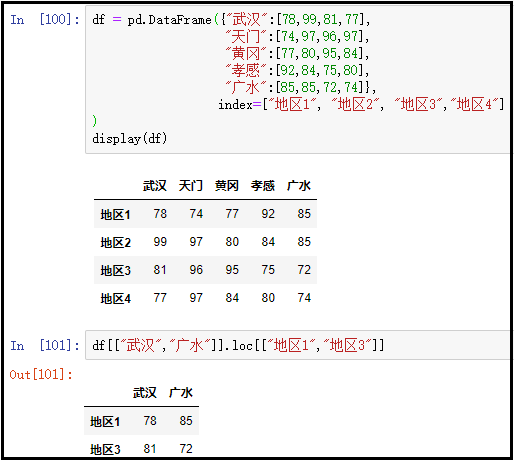
7、访问某几列中的某几行
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
# 先获取列,再获取行
df[["武汉","广水"]].loc[["地区1","地区3"]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
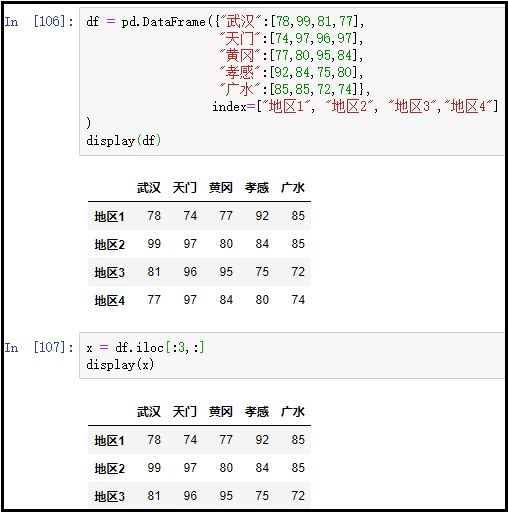
8、获取多行多列常用的一种方式:iloc+切片、loc+标签数组
① 获取多行多列:iloc+切片
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
x = df.iloc[:3,:]
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
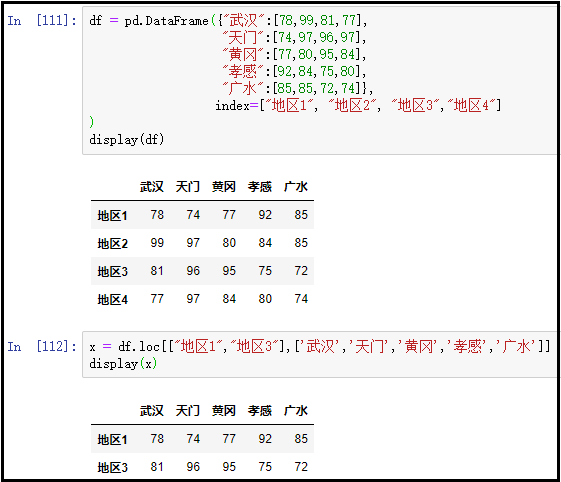
② 获取多行多列:loc+标签数组
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
x = df.loc[["地区1","地区3"],['武汉','天门','黄冈','孝感','广水']]
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
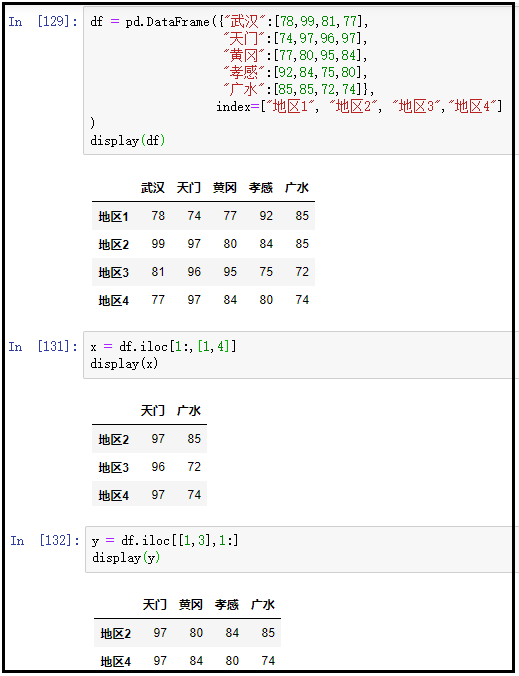
9、获取多行多列常用的第二种方式:iloc+切片+位置数组、loc+切片+标签数组
① 获取多行多列:iloc+切片+位置数组
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
x = df.iloc[1:,[1,4]]
display(x)
y = df.iloc[[1,3],1:]
display(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果如下:
② 获取多行多列:loc+切片+标签数组
df = pd.DataFrame({"武汉":[78,99,81,77], "天门":[74,97,96,97], "黄冈":[77,80,95,84], "孝感":[92,84,75,80], "广水":[85,85,72,74]}, index=["地区1", "地区2", "地区3","地区4"]
)
display(df)
x = df.loc["地区1":,["武汉","广水"]]
display(x)
y = df.loc[["地区1","地区3"],"天门":]
display(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果如下:

文章来源: blog.csdn.net,作者:数据分析与统计学之美,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_41261833/article/details/104158011

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)