DataFrame(3):DataFrame常用属性说明

【摘要】 1、常用属性如下
ndim 返回DataFrame的维数;shape 返回DataFrame的形状;dtypes 返回DataFrame中每一列元素的数据类型;size 返回DataFrame中元素的个数;T 返回DataFrame的转置结果;index 返回DataFrame中的索引;columns 返回DataFrame中的列索引;values 返回DataFra...
1、常用属性如下
- ndim 返回DataFrame的维数;
- shape 返回DataFrame的形状;
- dtypes 返回DataFrame中每一列元素的数据类型;
- size 返回DataFrame中元素的个数;
- T 返回DataFrame的转置结果;
- index 返回DataFrame中的索引;
- columns 返回DataFrame中的列索引;
- values 返回DataFrame中的数值;
2、演示如下
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
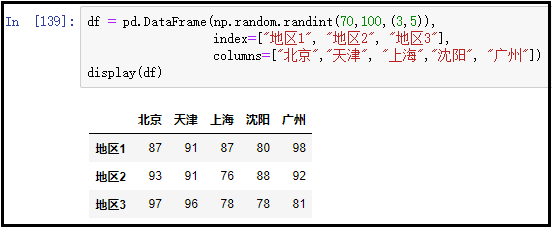
① ndim:返回DataFrame的维数;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.ndim
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
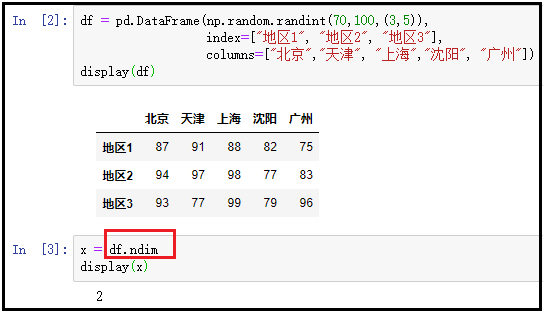
② shape:返回DataFrame的形状;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.shape
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
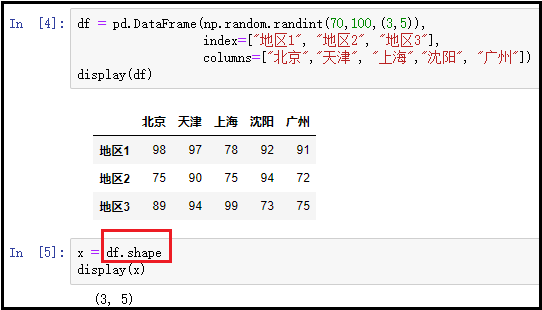
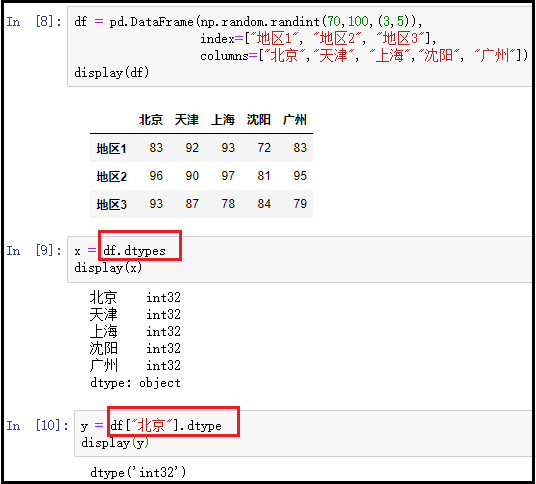
③ dtypes:返回DataFrame中每一列元素的数据类型;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.dtypes
display(x)
# 查看某一列元素的数据类型
y = df["北京"].dtype
display(y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果如下:
④ size:返回DataFrame中元素的个数;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.size
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
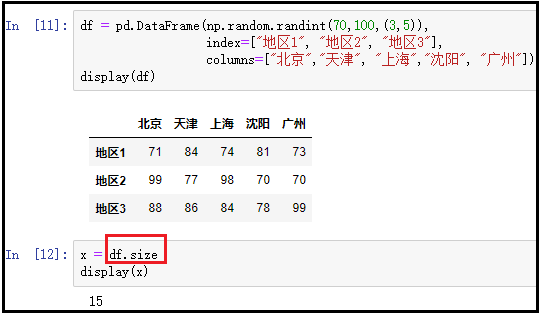
⑤ T:返回DataFrame的转置结果;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.T
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
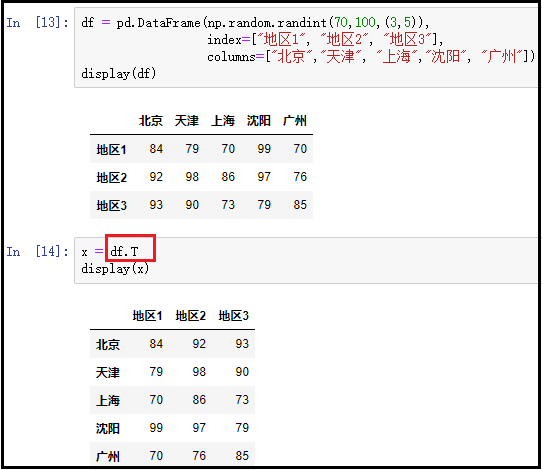
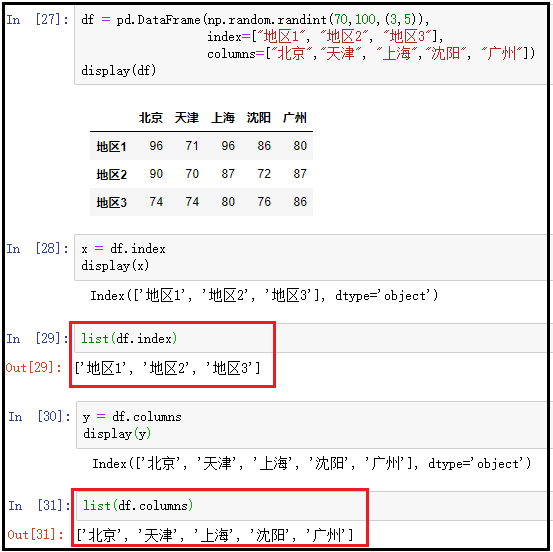
⑥ index:返回DataFrame中的索引;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.index
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
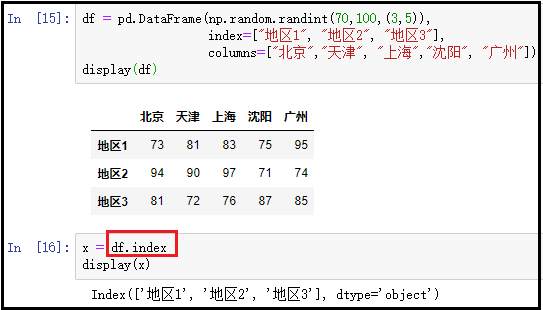
⑦ columns:返回DataFrame中的列索引;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.columns
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
注意:行索引、列索引都可以通过list转换为列表,然后我们可以针对这个列表做其他操作。
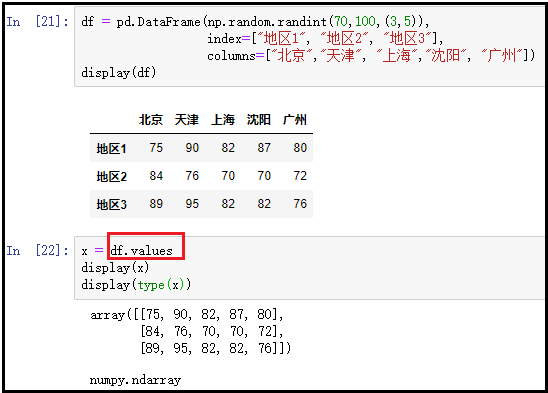
⑧ values:返回DataFrame中的数值;
df = pd.DataFrame(np.random.randint(70,100,(3,5)), index=["地区1", "地区2", "地区3"], columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.values
display(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
文章来源: blog.csdn.net,作者:数据分析与统计学之美,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_41261833/article/details/104150514

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)