领导给我一堆无序、杂乱的数据,我写了一个Python自动化脚本!

【摘要】 问题抽丝剥茧
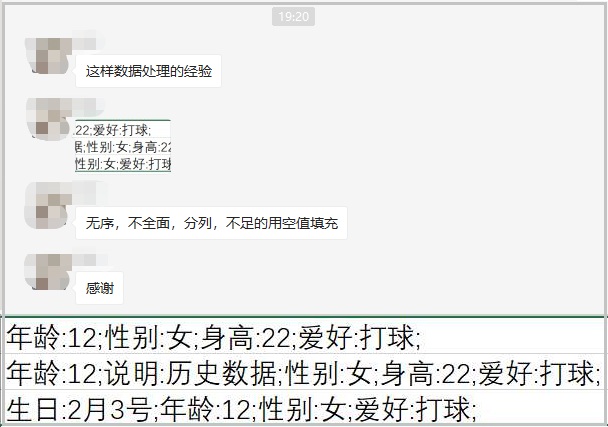
这个问题也算是群友答疑。如果说同事或者老板给你一堆这样的数据,你估计会抓狂,该怎么处理呢? 仔细观察上面数据可以发现,该数据有如下2个主要特点:
① 每一行的数据长度不同。第一行和第三行有4个属性,第二行有5个属性。② 不同行的属性值,并不是对应排列。
解题思路剖析
你可能会想,直接用Excel分裂。其实并不可行,因为不同行的属性值,并不是对应排...
问题抽丝剥茧
这个问题也算是群友答疑。如果说同事或者老板给你一堆这样的数据,你估计会抓狂,该怎么处理呢?
仔细观察上面数据可以发现,该数据有如下2个主要特点:
- ① 每一行的数据长度不同。第一行和第三行有4个属性,第二行有5个属性。
- ② 不同行的属性值,并不是对应排列。
解题思路剖析
你可能会想,直接用Excel分裂。其实并不可行,因为不同行的属性值,并不是对应排列。Excel分列导致的结果就是:不同的属性,存在于相同的行。

放弃Excel那条路之后,我就只能寻求Python的帮助了。我们要根据数据的特点,选择合适的数据存储方法。最终问题就转化为:构造数据源,然后创建DataFrame即可。
我曾经写了一篇文章《DataFrame的创建方式》,这篇文章总结了10种创建DataFrame的方法,我下面把链接提供给大家学习一下。
DataFrame的10种创建方式:http://suo.im/6tEjDJ
然后根据我们这个数据的特点,我选择构造字典组成的列表这样一个数据,并利用它来创建DataFrame。
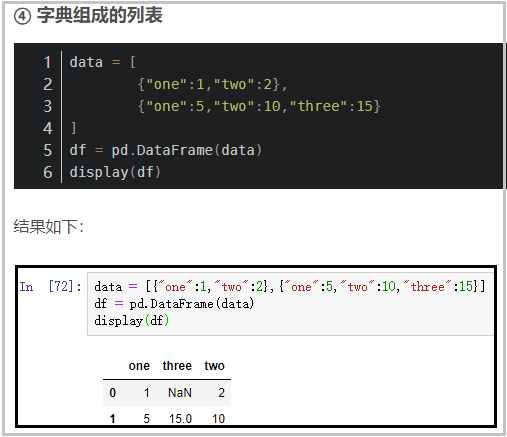
观察我提供的这个案例和待解决的问题,简直异曲同工。我们同样可以将上述数据的每一行,都变成一个个键值对组成的字典。然后最外层用一个大列表,将所有的字典包含起来。
完整代码
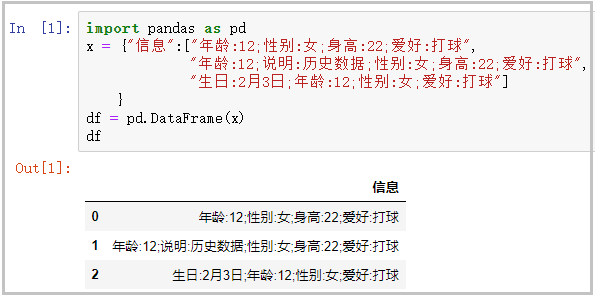
1)首先需要构造练习数据
import pandas as pd
x = {"信息":["年龄:12;性别:女;身高:22;爱好:打球", "年龄:12;说明:历史数据;性别:女;身高:22;爱好:打球", "生日:2月3日;年龄:12;性别:女;爱好:打球"] }
df = pd.DataFrame(x)
df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
2)构造字典组成的列表
tmps_list = []
for data in df["信息"].values: tmp_dict = {} for kv in data.split(";"): k, v = kv.split(":") tmp_dict[k] = v tmps_list.append(tmp_dict)
tmps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果如下:

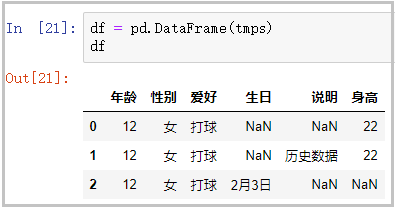
3)创建DataFrame
df = pd.DataFrame(tmps)
df
- 1
- 2
结果如下:
文章来源: blog.csdn.net,作者:数据分析与统计学之美,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_41261833/article/details/107774397

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)