Python+os+openpyxl 批量获取Excel的文件名和最大行数

【摘要】 1. 提出需求
这已经不知道是粉丝问我的第几个办公自动化的问题了,并且这些问题都是大家在学习和工作中碰到过的真实问题场景。其实从下图中已经可以很明确的看出别人的需求了,我这里就不用在赘述了,下面直接上思路吧!
2. 解题思路
为了让大家能够快速学会,我这里会将问题拆解为各个小部分,也希望能够帮助到大家。
1)导入相关库
import pandas as pd...
1. 提出需求
这已经不知道是粉丝问我的第几个办公自动化的问题了,并且这些问题都是大家在学习和工作中碰到过的真实问题场景。其实从下图中已经可以很明确的看出别人的需求了,我这里就不用在赘述了,下面直接上思路吧!

2. 解题思路
为了让大家能够快速学会,我这里会将问题拆解为各个小部分,也希望能够帮助到大家。
1)导入相关库
import pandas as pd
from openpyxl import load_workbook
from openpyxl import Workbook
import os
- 1
- 2
- 3
- 4
2)获取文件的路径
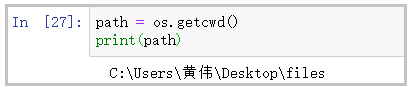
path = os.getcwd()
print(path)
- 1
- 2
结果如下:
3)遍历文件夹,获取文件夹下的文件(包括文件夹和文件)
for path,dirs,files in os.walk(path): print(files)
- 1
- 2
结果如下:

4)筛选出以.xlsx结尾的Excel表格
tables = []
path = os.getcwd()
for path,dirs,files in os.walk(path): for i in files: if i.split(".")[1] == "xlsx": tables.append(i)
tables
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:

5)组织数据,便于后续写入到Excel中
这里特别说明一点,组织好的数据应该是一个列表嵌套,内层的每一个列表,就是Excel表格中的每一行。
final_data = []
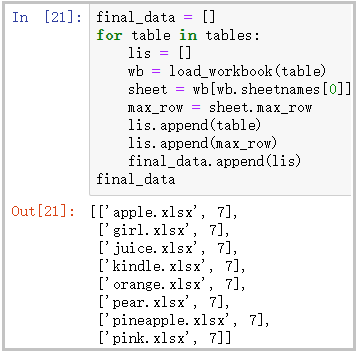
for table in tables: lis = [] wb = load_workbook(table) sheet = wb[wb.sheetnames[0]] max_row = sheet.max_row lis.append(table) lis.append(max_row) final_data.append(lis)
final_data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果如下:
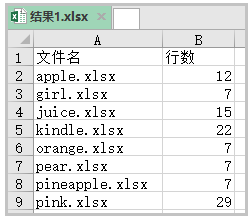
6)新建一个Excel表格,并循环插入数据
new_wb = Workbook()
sheet = new_wb.active
sheet.title = "最终数据"
sheet.append(["文件名 ","行数"])
for row in final_data: sheet.append(row)
new_wb.save(filename="结果.xlsx")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下:
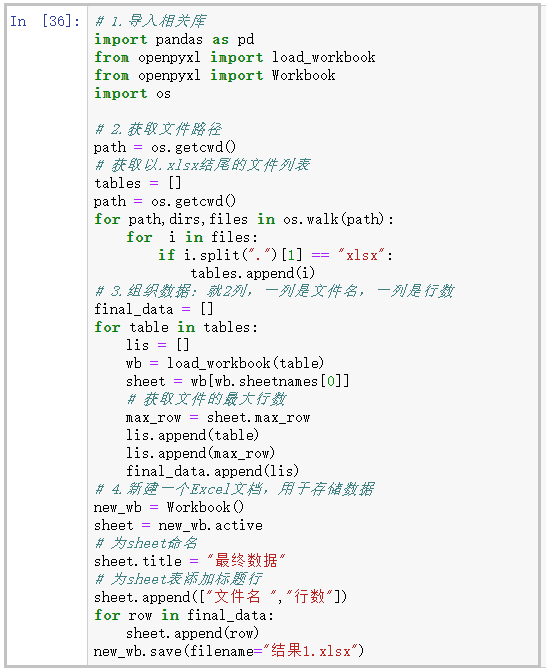
3. 完整代码
为了文章的完整性,我在文章最后放上我的代码。但是限于文章篇幅,最后我只粘贴一张图片,详细代码,大家可以去文末获取。
文章来源: blog.csdn.net,作者:数据分析与统计学之美,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_41261833/article/details/107964369

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)