搭建伪分布式Spark集群及RDD简单操作

安装一个简单的伪分布式Spark集群及RDD简单操作

@[toc]
实验环境
前提是已经配置好Java、Hadoop了
- 环境:Linux
- 安装包版本:
- scala-2.11.8.tgz
- spark-2.1.0
- jdk1.8.0_171
- hadoop-2.6.0
spark: http://spark.apache.org/downloads.html
scala: https://www.scala-lang.org/download/2.11.8.html
- 安装包存放路径:/usr/local
实验原理
安装配置
安装过程其实很简单,Spark是一个计算框架,功能就和Hadoop的MapReduce一样,Hadoop的MapReduce是不需要启动的,因MapReduce只是提供了一组计算的API,使用Yarn作为资源调度就行。
环境监控
Spark集群配置好以后,可以使用sbin目录下的start-all.sh启动集群。启动集群后,可以使用浏览器就行查看,master的默认端口是8080,学会使用浏览器进行监控能够方便我们很多操作。
安装前的环境准备
关闭spark服务
- 本次实验为安装一个简单的伪分布式Spark集群,环境中已经配置好Java、Hadoop,如果是真实环境中,则需要三台至多台服务器,这里只进行简单配置安装学习。在安装Spark之前还需要安装Scala,因为Spark是scala开发,所以scala是需要配置的。解压安装Scala,解压后文件依然存放在/usr/local下。
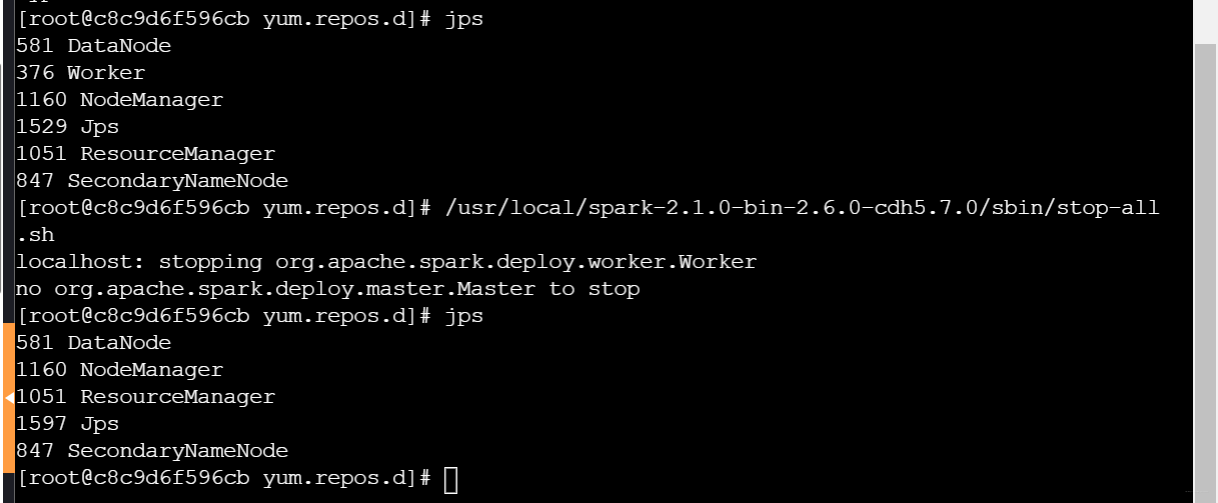
- 使用命令查看进程,可以看到已经开启开启多个服务,实验中我们关闭spark相关服务,练习spark的安装和开启。
- 查看所有进程服务:jps
- 关闭spark服务:/usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0/sbin/stop-all.sh
- 查看进程:jps

解压Scala安装包
首先进入/usr/local文件夹下查看我们需要的安装包,然后进行解压安装
- 查看local下列表:ls /usr/local
- 解压scala: tar -zxvf /usr/local/scala-2.11.8.tgz -C /usr/local/

配置环境变量
配置环境变量,添加Scala的安装路径
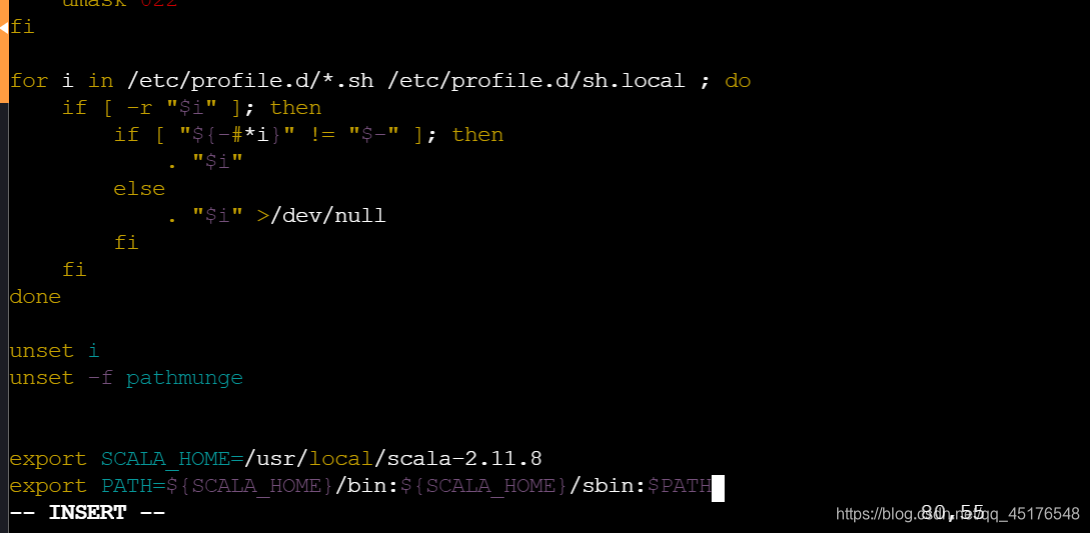
- 编辑配置文件:vim /etc/profile
编辑如下:
export SCALA_HOME=/usr/local/scala-2.11.8
export PATH=${SCALA_HOME}/bin:${SCALA_HOME}/sbin:$PATH
- 保存退出,生效配置文件让其立刻生效。然后再运行scala进行验证。
- 生效变量:
source /etc/profile - 开启scala:
scala
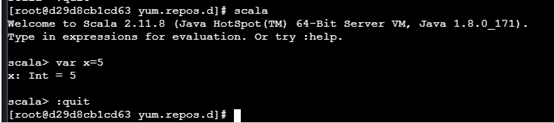
示例验证,为x赋值为5,然后退出scala:
scala> var x =5
sacal> :quit
解压Spark安装包,添加配置
解压Spark安装包
- Spark安装文件在/usr/local/下面,使用命令解压到 /usr/local/下面:
tar zxvf /usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz -C /usr/local
- 解压完成后,同样在~/bashrc中添加SPARK_HOME环境变量,同时将bin目录和sbin目录添加到PATH路径下。
export SPARK_HOME=/usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0
export PATH=${SPARK_HOME}/sbin:${SPARK_HOME}/bin:$PATH
注意使用source命令使其生效。
生效环境变量:source /etc/profile
- 修改spark配置文件
修改Spark的配置文件,首先将spark-env.sh.templete复制为spark-env.sh,在里面配置:JAVA_HOME、SPARK_MASTER_IP、HADOOP_CONF_DIR,注意保存。
- 进入spark配置目录:cd $SPARK_HOME/conf/
- 查看当前路径:pwd
- 查看当前目录下所有配置文件:ls
- 将自带的template样例文件复制为配置文件:cp spark-env.sh.template spark-env.sh
- 编辑配置文件:vim spark-env.sh

export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export SPARK_MASTER_IP=localhost
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop

启动spark集群
启动集群,查看进程 。因为spark执行程序在spark/sbin目录下,当前在spark的配置目录conf路径下,因此可以退到sa
- 退回上一层:cd …
- 命令:sbin/start-all.sh
- 命令:jps
启动伪集群之后,可以看到其进程显示启动了master和worker。说明伪机群搭建时,服务器是主节点,也是从节点。

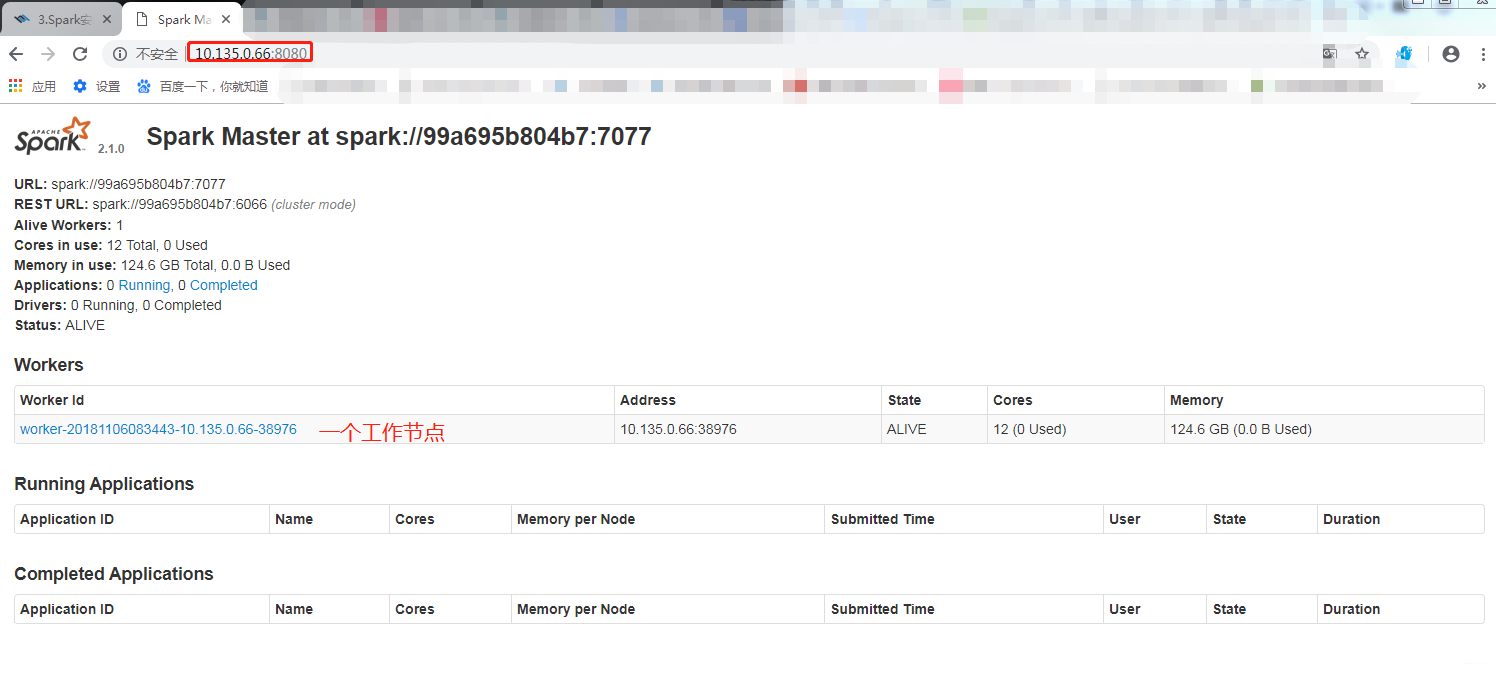
当然Spark也提供了浏览器端口供我们监控spark节点的状态。可以直接访问主节点master的8080端口进行查看
Spark运行模式
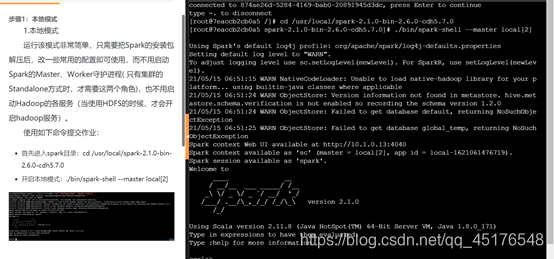
本地模式
• 首先进入spark目录:cd /usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0
• 开启本地模式:./bin/spark-shell --master local[2]
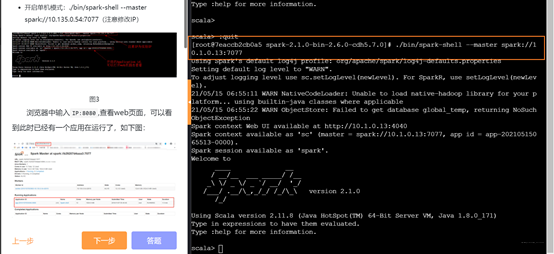
standalone模式
在交互式Shell中Spark应用程序,需运行下面的命令:
• 开启单机模式:./bin/spark-shell --master spark://10.135.0.54:7077(注意修改IP)
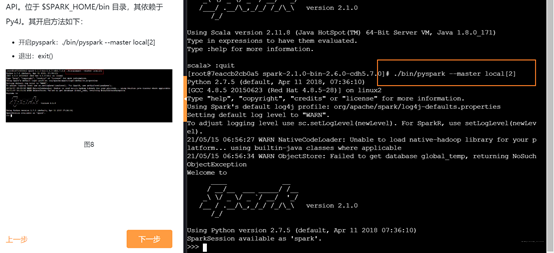
开启PySpark
PySpark 是 Spark 为 Python 开发者提供的 API。位于 $SPARK_HOME/bin 目录,其依赖于 Py4J。其开启方法如下:
• 开启pyspark:./bin/pyspark --master local[2]
• 退出:exit()
RDD基本操作
从集合创建RDD
-
首先开启spark,然后进入Spark shell交互界面
• 进入spark目录:cd /usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0/
• 进入spark交互界面:bin/spark-shell -
通过并行化集合来创建RDD
针对程序中的集合,调用SparkContext中的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD
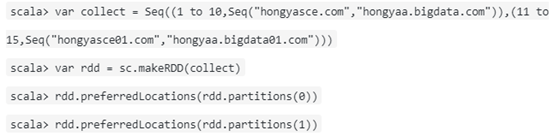
- 使用makeRDD创建RDD
该用法可以指定每一个分区的preferredLocations。操作如下:
元素转化操作
- 首先开启spark,然后进入Spark shell交互界面
• 进入spark目录:cd /usr/local/spark-2.1.0-bin-2.6.0-cdh5.7.0/
• 进入spark交互界面:bin/spark-shell
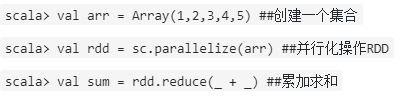
对一个数据{1,2,3,3}的RDD进行基本的RDD转化操作
scala> val arr = Array(1,2,3,3) ##创建一个集合
scala> val rdd = sc.parallelize(arr) ##并行化操作RDD
-
map()将函数应用于RDD中的每个元素,将返回新的RDD
-
flatMap()将函数应用于RDD中的每个元素,将返回的迭代器的所有元素构成的RDD,通常用于切分单词
-
filter()过滤,结果返回一个由通过传给filter()的函数的元素组成的RDD。
-
distinct()去重。
-
sample(withRepalcement,fraction,[seed])对RDD采样 ,以及是否替换。withRepalcement 是否为放回(不重复),fraction为数量。结果是非确定的,产生一般的数据。





元素行动操作
-
collect():返回RDD中的所有元素。
rdd.collect()
-
count():RDD中的元素个数。
rdd.count()
-
countByValue():各结果在RDD中出现的次数。
rdd.countByValue() -
take(num):从RDD中返回num个元素。
rdd.take(2) -
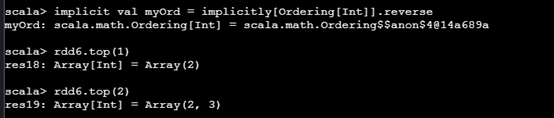
top(num):从RDD中返回前面的num个元素。
rdd.top(2)
-
takeSample(withReplacement,num,[seed]) 从RDD中返回任意一些元素(非确定)。
rdd.takeSample(false,1) -
fold(zero)(func):和reduce一样,但是需要提供初始值。
rdd.fold(0)((x,y) => x+y) -
aggregate(zeroValue)(seq0p,comb0p) 和reduce类似但是通常返回不同的数据
rdd.aggregate((0,0))((x,y) => (x._1 + y,x._2 +1 ),(x,y) => (x._1 + y._1, x._2 + y._2))



到这里就结束了,如果对你有帮助,欢迎点赞关注评论,你的点赞对我很重要,author:北山啦

- 点赞
- 收藏
- 关注作者
评论(0)