力扣(LeetCode)刷题,简单+中等题(第34期)

目录
力扣(LeetCode)定期刷题,每期10道题,业务繁重的同志可以看看我分享的思路,不是最高效解决方案,只求互相提升。
第1题:整数转罗马数字
试题要求如下:

解题思路:
1、建立两个数组,分别是数值数值以及罗马字符数组,这两个数组的罗马数与数组值对应;
2、找对应的罗马字符;
3、将罗马字符拷贝进输出字符串中。
回答(C语言):
-
#include<string.h>
-
-
char * intToRoman(int num){
-
//step1:定义数组
-
int s[13] = {1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1};//数值数组
-
char a[13][3] = {"M","CM","D","CD","C","XC","L","XL","X","IX","V","IV","I"};//罗马字符数组
-
char *res = (char *)calloc(16,sizeof(char));
-
-
int count = 0;//罗马字符拷贝次数
-
-
//step2:找对应的罗马字符
-
for(int i = 0;i < 13;i++){
-
count = num / s[i];
-
num %= s[i];
-
//step3:拷贝罗马字符
-
for(int j = 0;j < count;j++){
-
strcat(res,a[i]);//"strcat":该函数是将a[i]的字符串拷贝到res后面
-
}
-
}
-
-
return res;
-
}
运行效率如下所示:

第2题:电话号码的字母组合
试题要求如下:
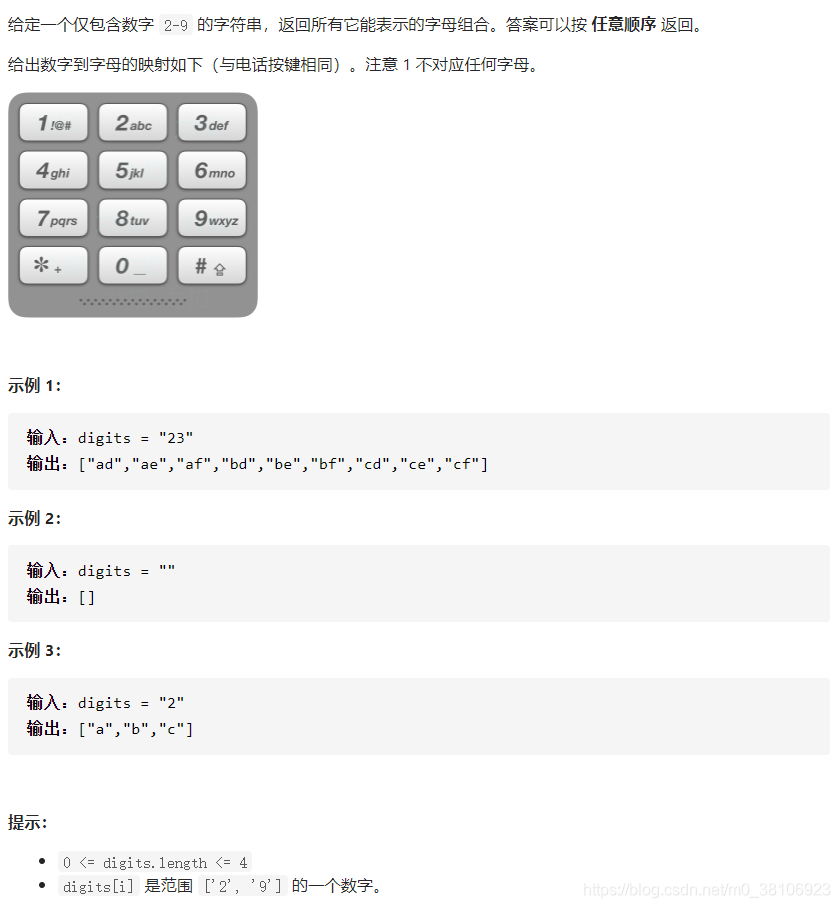
解题思路:
使用Map表存储每个数字对应的所有可能的字母,然后进行回溯操作,穷举出所有的解。
回答(C语言):
-
/**
-
* Note: The returned array must be malloced, assume caller calls free().
-
*/
-
char phoneMap[9][5] = {"", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"}; // 1 不对应任何字母
-
/* Note: The returned array must be malloced, assume caller calls free(). */
-
void backtrack(char* digits, int digits_size, int index, char* item, int item_size, char** ans, int* returnSize) {
-
if (index == digits_size) {
-
char* tmp = malloc((item_size + 1) * sizeof(char)); // 为每一个 item 分配独立空间
-
strcpy(tmp, item); // 把每一个 item 复制保存下来
-
ans[(*returnSize)++] = tmp;
-
}
-
else {
-
char* letters = phoneMap[digits[index] - '1'];
-
int size = strlen(letters);
-
for (int i = 0; i < size; i++) {
-
item[item_size++] = letters[i];
-
item[item_size] = 0;
-
backtrack(digits, digits_size, index + 1, item, item_size, ans, returnSize);
-
item[--item_size] = 0;
-
}
-
}
-
}
-
-
char** letterCombinations(char* digits, int* returnSize) {
-
int digits_size = strlen(digits);
-
*returnSize = 0;
-
-
if (digits_size == 0) {
-
return NULL;
-
}
-
-
int num = pow(4, digits_size);
-
char** ans = (char**)malloc(num * sizeof(char*));
-
char* item = malloc((digits_size + 1) * sizeof(char));
-
-
backtrack(digits, digits_size, 0, item, 0, ans, returnSize);
-
-
return ans;
-
}
运行效率如下所示:

第3题:二叉树的所有路径
试题要求如下:

解题思路:
最直观的方法是使用深度优先搜索。在深度优先搜索遍历二叉树时,需要考虑当前的节点以及它的孩子节点。
- 如果当前节点不是叶子节点,则在当前的路径末尾添加该节点,并继续递归遍历该节点的每一个孩子节点。
- 如果当前节点是叶子节点,则在当前路径末尾添加该节点后我们就得到了一条从根节点到叶子节点的路径,将该路径加入到答案即可。
如此,当遍历完整棵二叉树以后就得到了所有从根节点到叶子节点的路径。当然,深度优先搜索也可以使用非递归的方式实现。
回答(C语言):
-
/**
-
* Definition for a binary tree node.
-
* struct TreeNode {
-
* int val;
-
* struct TreeNode *left;
-
* struct TreeNode *right;
-
* };
-
*/
-
-
/**
-
* Note: The returned array must be malloced, assume caller calls free().
-
*/
-
void construct_paths(struct TreeNode* root, char** paths, int* returnSize, int* sta, int top) {
-
if (root != NULL) {
-
if (root->left == NULL && root->right == NULL) { // 当前节点是叶子节点
-
char* tmp = (char*)malloc(1001);
-
int len = 0;
-
for (int i = 0; i < top; i++) {
-
len += sprintf(tmp + len, "%d->", sta[i]);
-
}
-
sprintf(tmp + len, "%d", root->val);
-
paths[(*returnSize)++] = tmp; // 把路径加入到答案中
-
} else {
-
sta[top++] = root->val; // 当前节点不是叶子节点,继续递归遍历
-
construct_paths(root->left, paths, returnSize, sta, top);
-
construct_paths(root->right, paths, returnSize, sta, top);
-
}
-
}
-
}
-
-
char** binaryTreePaths(struct TreeNode* root, int* returnSize) {
-
char** paths = (char**)malloc(sizeof(char*) * 1001);
-
*returnSize = 0;
-
int sta[1001];
-
-
construct_paths(root, paths, returnSize, sta, 0);
-
-
return paths;
-
}
运行效率如下所示:

第4题:砖墙
试题要求如下:
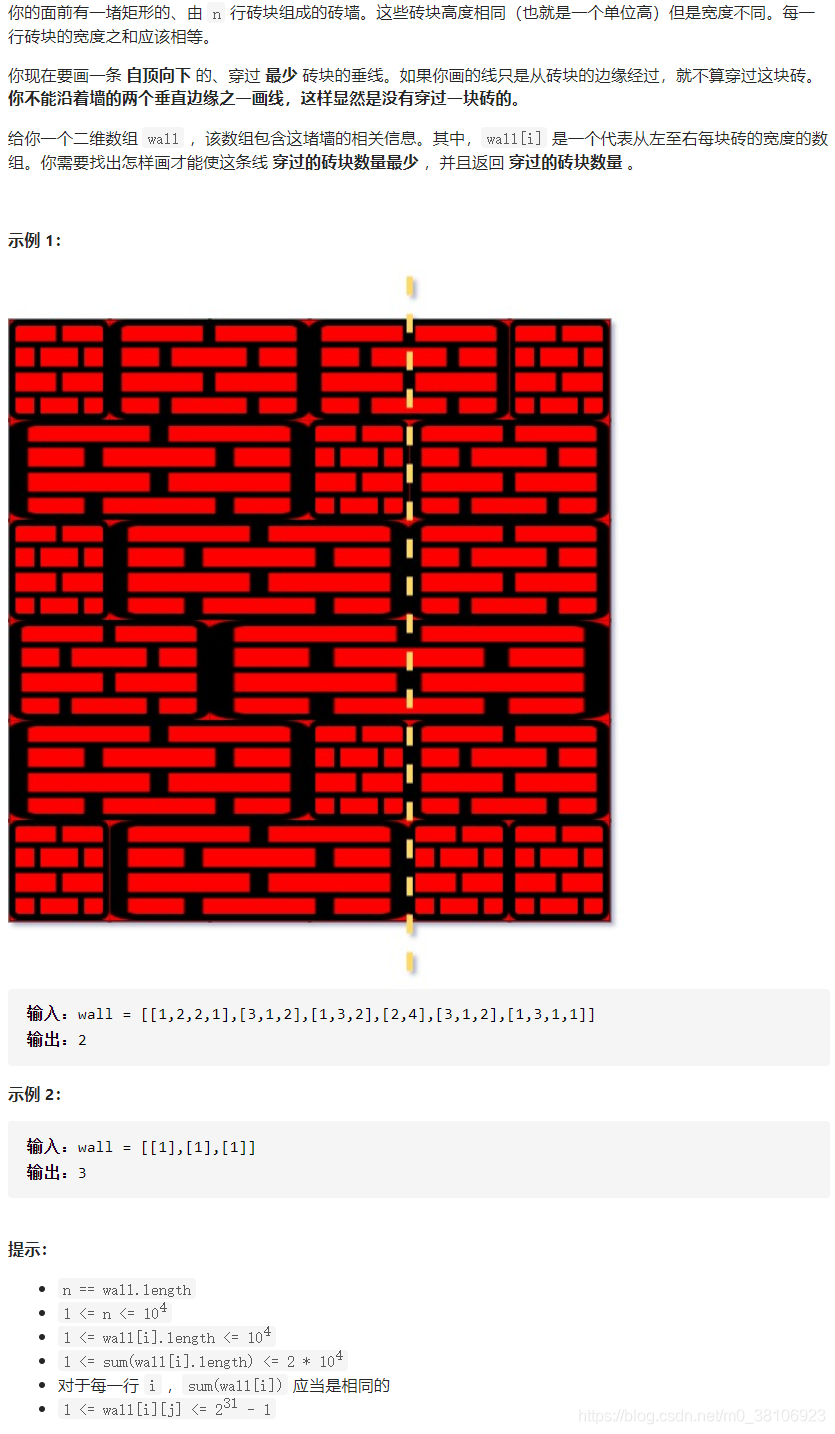
解题思路:
遍历砖墙的每一行,对于当前行,我们从左到右地扫描每一块砖,使用一个累加器记录当前砖的右侧边缘到砖墙的左边缘的距离,将除了最右侧的砖块以外的其他砖块的右边缘到砖墙的左边缘的距离加入到哈希表中。最后我们遍历该哈希表,找到出现次数最多的砖块边缘,这就是垂线经过的砖块边缘,而该垂线经过的砖块数量即为砖墙的高度减去该垂线经过的砖块边缘的数量。
回答(C语言):
-
struct HashTable {
-
int key, val;
-
UT_hash_handle hh;
-
};
-
-
int leastBricks(int** wall, int wallSize, int* wallColSize) {
-
struct HashTable* cnt = NULL;
-
for (int i = 0; i < wallSize; i++) {
-
int n = wallColSize[i];
-
int sum = 0;
-
for (int j = 0; j < n - 1; j++) {
-
sum += wall[i][j];
-
struct HashTable* tmp;
-
HASH_FIND_INT(cnt, &sum, tmp);
-
if (tmp == NULL) {
-
tmp = malloc(sizeof(struct HashTable));
-
tmp->key = sum, tmp->val = 1;
-
HASH_ADD_INT(cnt, key, tmp);
-
} else {
-
tmp->val++;
-
}
-
}
-
}
-
int maxCnt = 0;
-
struct HashTable *iter, *tmp;
-
HASH_ITER(hh, cnt, iter, tmp) {
-
maxCnt = fmax(maxCnt, iter->val);
-
}
-
return wallSize - maxCnt;
-
}
运行效率如下所示:

第5题:下一个排列
试题要求如下:

回答(C语言):
-
void swap(int *a, int *b) {
-
int t = *a;
-
*a = *b, *b = t;
-
}
-
-
void reverse(int *nums, int left, int right) {
-
while (left < right) {
-
swap(nums + left, nums + right);
-
left++, right--;
-
}
-
}
-
-
void nextPermutation(int *nums, int numsSize) {
-
int i = numsSize - 2;
-
-
while (i >= 0 && nums[i] >= nums[i + 1]) {
-
i--;
-
}
-
if (i >= 0) {
-
int j = numsSize - 1;
-
while (j >= 0 && nums[i] >= nums[j]) {
-
j--;
-
}
-
swap(nums + i, nums + j);
-
}
-
-
reverse(nums, i + 1, numsSize - 1);
-
}
运行效率如下所示:

第6题:括号生成
试题要求如下:
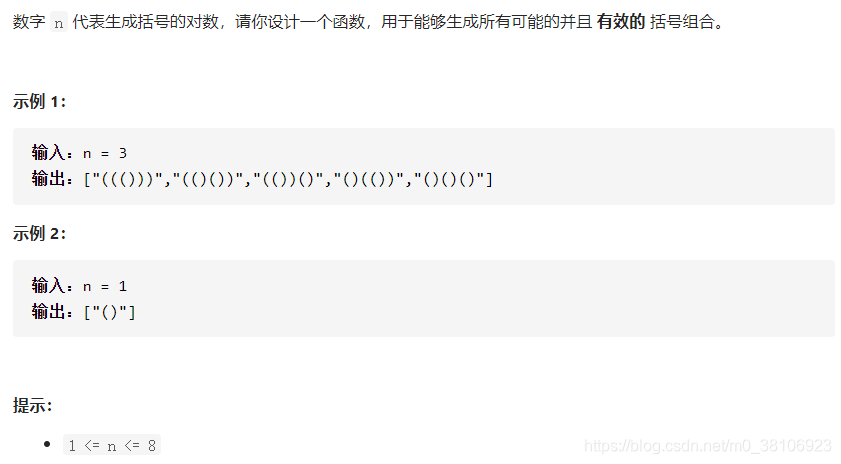
解题思路:
回溯算法递归求解:如果左括号数量不大于 n,我们可以放一个左括号。如果右括号数量小于左括号的数量,我们可以放一个右括号。
回答(C语言):
-
// 回溯法求解
-
#define MAX_SIZE 1430 // 卡特兰数: 1, 1, 2, 5, 14, 42, 132, 429, 1430
-
-
void generate(int left, int right, int n, char *str, int index, char **result, int *returnSize) {
-
if (index == 2 * n) { // 当前长度已达2n
-
result[(*returnSize)] = (char*)calloc((2 * n + 1), sizeof(char));
-
strcpy(result[(*returnSize)++], str);
-
return;
-
}
-
// 如果左括号数量不大于 n,可以放一个左括号
-
if (left < n) {
-
str[index] = '(';
-
generate(left + 1, right, n, str, index + 1, result, returnSize);
-
}
-
// 如果右括号数量小于左括号的数量,可以放一个右括号
-
if (right < left) {
-
str[index] = ')';
-
generate(left, right + 1, n, str, index + 1, result, returnSize);
-
}
-
}
-
-
/**
-
* Note: The returned array must be malloced, assume caller calls free().
-
*/
-
char** generateParenthesis(int n, int *returnSize) {
-
char *str = (char*)calloc((2 * n + 1), sizeof(char));
-
char **result = (char **)malloc(sizeof(char *) * MAX_SIZE);
-
*returnSize = 0;
-
generate(0, 0, n, str, 0, result, returnSize);
-
return result;
-
}
运行效率如下所示:

第7题:删除并获得点数
试题要求如下:
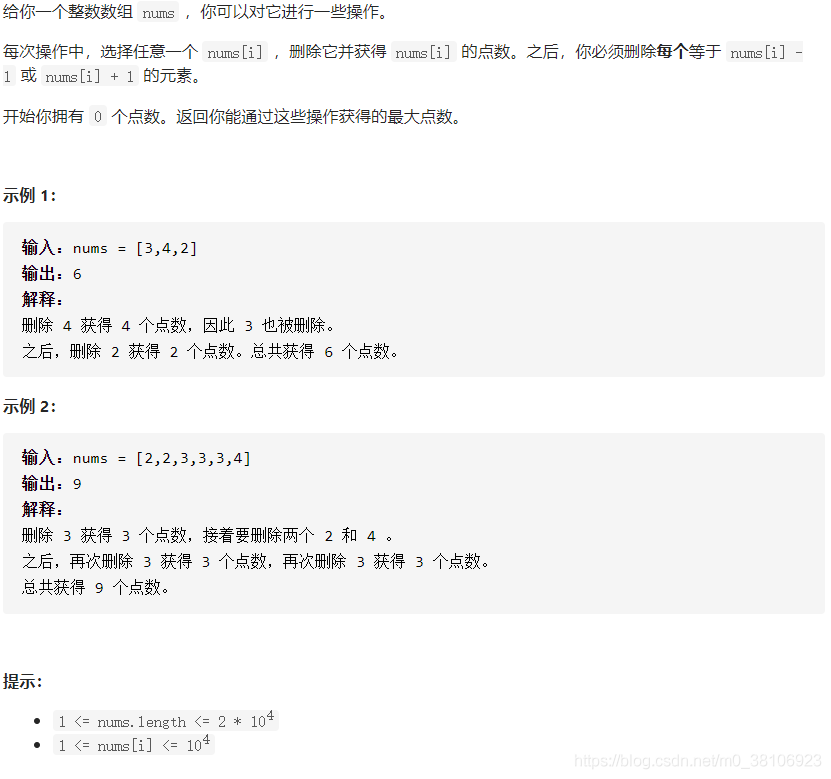
回答(C语言):
-
int rob(int *nums, int numsSize) {
-
int first = nums[0], second = fmax(nums[0], nums[1]);
-
-
for (int i = 2; i < numsSize; i++) {
-
int temp = second;
-
second = fmax(first + nums[i], second);
-
first = temp;
-
}
-
-
return second;
-
}
-
-
int deleteAndEarn(int *nums, int numsSize) {
-
int maxVal = 0;
-
-
for (int i = 0; i < numsSize; i++) {
-
maxVal = fmax(maxVal, nums[i]);
-
}
-
-
int sum[maxVal + 1];
-
memset(sum, 0, sizeof(sum));
-
-
for (int i = 0; i < numsSize; i++) {
-
sum[nums[i]] += nums[i];
-
}
-
-
return rob(sum, maxVal + 1);
-
}
运行效率如下所示:

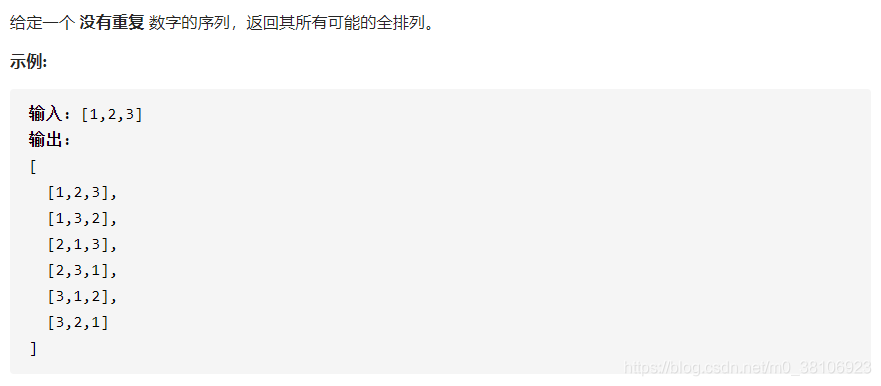
第8题:全排列
试题要求如下:
回答(C语言):
-
/**
-
* Return an array of arrays of size *returnSize.
-
* The sizes of the arrays are returned as *returnColumnSizes array.
-
* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().
-
*/
-
-
int count;
-
-
void dfs(int* nums,int numsSize,int depth,int* cur,bool* used,int** res){
-
if(depth==numsSize){
-
res[count]=(int*)malloc(numsSize*sizeof(int));
-
memcpy(res[count++],cur,numsSize*sizeof(int));
-
return;
-
}
-
-
for(int i=0;i<numsSize;++i){
-
if(used[i]==true) continue;
-
cur[depth]=nums[i];
-
used[i]=true;
-
//++depth;
-
-
dfs(nums,numsSize,depth+1,cur,used,res);
-
-
//--depth;
-
used[i]=false;
-
}
-
}
-
-
int** permute(int* nums, int numsSize, int* returnSize, int** returnColumnSizes){
-
int s=1;
-
for(int i=1;i<=numsSize;++i) s*=i;
-
int** res=(int**)malloc(s*sizeof(int*));
-
-
bool* used=(bool*)malloc(numsSize*sizeof(bool));
-
memset(used,0,numsSize*sizeof(bool));
-
-
int* cur=(int*)malloc(numsSize*sizeof(int));
-
-
count=0;
-
dfs(nums,numsSize,0,cur,used,res);
-
-
*returnSize=s;
-
*returnColumnSizes=(int*)malloc(s*sizeof(int));
-
for(int i=0;i<s;++i) (*returnColumnSizes)[i]=numsSize;
-
-
return res;
-
}
运行效率如下所示:

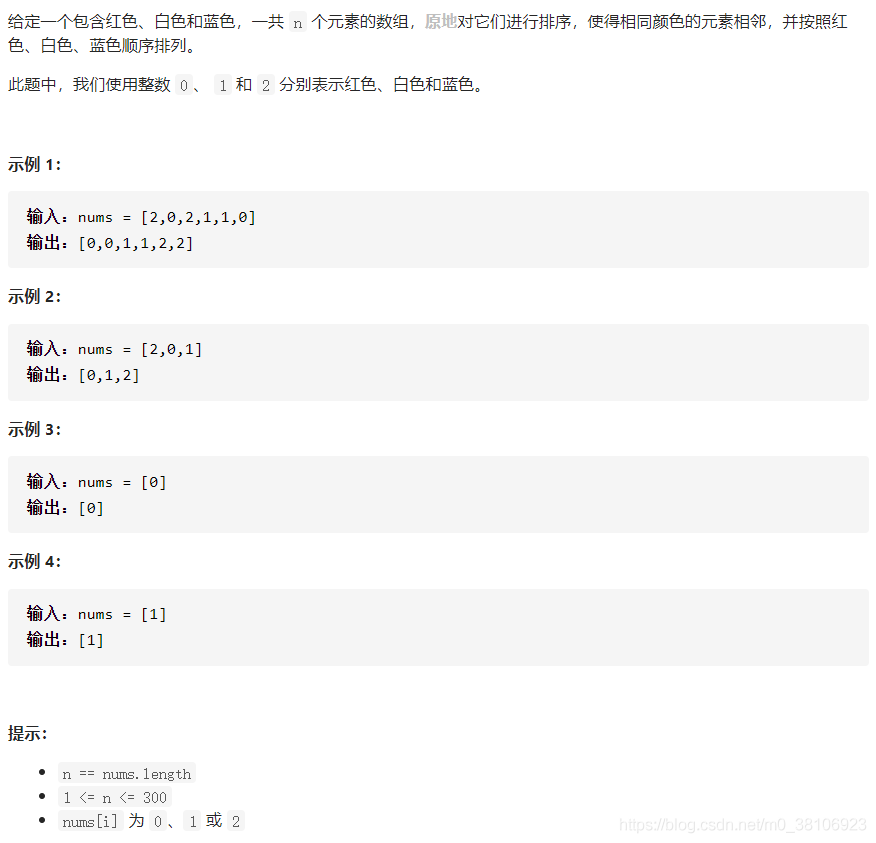
第9题:颜色分类
试题要求如下:
回答(C语言):
-
void swap(int *a, int *b) {
-
int t = *a;
-
*a = *b, *b = t;
-
}
-
-
void sortColors(int *nums, int numsSize) {
-
int ptr = 0;
-
-
for (int i = 0; i < numsSize; ++i) {
-
if (nums[i] == 0) {
-
swap(&nums[i], &nums[ptr]);
-
++ptr;
-
}
-
}
-
for (int i = ptr; i < numsSize; ++i) {
-
if (nums[i] == 1) {
-
swap(&nums[i], &nums[ptr]);
-
++ptr;
-
}
-
}
-
}
运行效率如下所示:

第10题:字母异位词分组
试题要求如下:

解题思路:
1、先排序字符串,以判断是否是异位词;
2、在hashtable中存放异位词的从小到大的字符串;
3、在ht中查找,以此判断是否需要创建result的新行;
4、存在ht中,则通过Str->id插入字符串即可;
5、不存在ht中,则在result中创建新行。
回答(C语言):
-
#define STR_MAX_LEN 10000
-
-
static int compare(const void* x, const void* y)
-
{
-
return *(char*)x - *(char*)y;
-
}
-
-
struct Str {
-
char key_str[STR_MAX_LEN];
-
int id;
-
UT_hash_handle hh;
-
};
-
-
char*** groupAnagrams(char** strs, int strsSize, int* returnSize, int** returnColumnSizes)
-
{
-
if (strs == NULL || strsSize < 0) {
-
return NULL;
-
}
-
struct Str *keyStrsHash = NULL, *str = NULL;
-
char ***result = (char ***)malloc(sizeof(char **) * strsSize);
-
char **sortedStrs = (char **)malloc(sizeof(char *) * strsSize);
-
*returnSize = 0;
-
*returnColumnSizes = (int *)malloc(sizeof(int) * strsSize);
-
-
for (int i = 0; i < strsSize; i++) {
-
int len = strlen(strs[i]);
-
sortedStrs[i] = (char*)malloc(len + 1);
-
(void)strcpy(sortedStrs[i], strs[i]);
-
qsort(sortedStrs[i], len, sizeof(char), compare);
-
-
HASH_FIND_STR(keyStrsHash, sortedStrs[i], str);
-
if (!str) {
-
str = (struct Str*)malloc(sizeof(struct Str));
-
strcpy(str->key_str, sortedStrs[i]);
-
str->id = *returnSize;
-
HASH_ADD_STR(keyStrsHash, key_str, str);
-
-
result[*returnSize] = (char**)malloc(sizeof(char*) * strsSize);
-
result[*returnSize][0] = (char*)malloc(len + 1);
-
strcpy(result[*returnSize][0], strs[i]);
-
-
(*returnColumnSizes)[*returnSize] = 1;
-
(*returnSize)++;
-
} else {
-
int row = str->id;
-
int col = (*returnColumnSizes)[row];
-
result[row][col] = (char*)malloc(len + 1);
-
strcpy(result[row][col], strs[i]);
-
((*returnColumnSizes)[row])++;
-
}
-
}
-
-
HASH_CLEAR(hh, keyStrsHash);
-
for (int i = 0; i < strsSize; i++) {
-
free(sortedStrs[i]);
-
}
-
return result;
-
}
运行效率如下所示:

文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/116331578

- 点赞
- 收藏
- 关注作者
评论(0)