相似度计算方法:余弦相似度

【摘要】 相似度计算方法:余弦相似度
计算用户相似度和用户对未知物品的可能评分
基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
例如现在有A、B、C、D四个用户,分别对a、b、c、d、e五个物品表达了自己喜好程度(通过评分高低来表现自己的偏好...
相似度计算方法:余弦相似度
基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
例如现在有A、B、C、D四个用户,分别对a、b、c、d、e五个物品表达了自己喜好程度(通过评分高低来表现自己的偏好程度高低),现在要为C用户推荐物品:
构建用户物品评分表

相似度计算
计算用户相似度的方法很多,这里选用余弦相似度
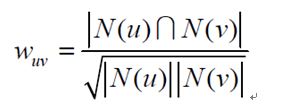
余弦相似度原理
用向量空间中的两个向量夹角的余弦值作为衡量两个个体间差异大小的度量,值越接近1,就说明夹角角度越接近0°,也就是两个向量越相似,就叫做余弦相似
给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。
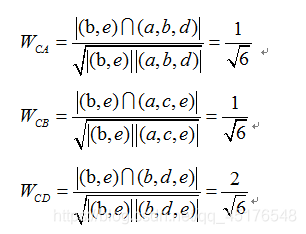
可以看出D用户与C用户相似度最大。
3、计算推荐结果
用户C评分的物品是b和e,下面计算用户C对物品a,c,d的偏好程度:

参考代码:
-
import math
-
-
class UserCF:
-
def __init__(self):
-
self.user_score_dict = self.initUserScore()
-
self.users_sim = self.UserSimilarity()
-
-
# 初始化用户评分数据
-
def initUserScore(self):
-
user_score_dict = {"A": {"a": 3.0, "b": 4.0, "c": 0.0, "d": 3.5, "e": 0.0},
-
"B": {"a": 4.0, "b": 0.0, "c": 4.5, "d": 0.0, "e": 3.5},
-
"C": {"a": 0.0, "b": 3.5, "c": 0.0, "d": 0., "e": 3.0},
-
"D": {"a": 0.0, "b": 4.0, "c": 0.0, "d": 3.50, "e": 3.0}}
-
return user_score_dict
-
-
-
-
# 计算用户之间的相似度,采用的是遍历每一个用户进行计算
-
def UserSimilarity(self):
-
W = dict()
-
for u in self.user_score_dict.keys():
-
W.setdefault(u,{})
-
for v in self.user_score_dict.keys():
-
if u == v:
-
continue
-
u_set = set( [key for key in self.user_score_dict[u].keys() if self.user_score_dict[u][key] > 0])
-
v_set = set( [key for key in self.user_score_dict[v].keys() if self.user_score_dict[v][key] > 0])
-
W[u][v] = float(len(u_set & v_set)) / math.sqrt(len(u_set) * len(v_set))
-
return W
-
-
# 预测用户对item的评分
-
def preUserItemScore(self, userA, item):
-
score = 0.0
-
for user in self.users_sim[userA].keys():
-
if user != userA:
-
score += self.users_sim[userA][user] * self.user_score_dict[user][item]
-
return score
-
-
# 为用户推荐物品
-
def recommend(self, userA):
-
# 计算userA 未评分item的可能评分
-
user_item_score_dict = dict()
-
for item in self.user_score_dict[userA].keys():
-
if self.user_score_dict[userA][item] <= 0:
-
user_item_score_dict[item] = self.preUserItemScore(userA, item)
-
return user_item_score_dict
-
-
if __name__ == "__main__":
-
ub = UserCF()
-
print(ub.recommend("C"))
-
spyder实验结果:
{'a': 2.8577380332470415, 'c': 1.8371173070873839, 'd': 4.286607049870562}
文章来源: blog.csdn.net,作者:北山啦,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_45176548/article/details/115890407

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)