Python爬虫--BeautifulSoup总结

【摘要】 Python爬虫–BeautifulSoup总结
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
文章目录
Python爬虫--BeautifulSoup总结安装Beauti...
Python爬虫–BeautifulSoup总结
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.

安装BeautifulSoup
from bs4 import BeautifulSoup
- 1
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
soup = BeautifulSoup(html_doc,"lxml")
- 1
几个简单的浏览结构化数据的方法
soup.title
- 1
<title>The Dormouse's story</title>
- 1
soup.title.name
- 1
'title'
- 1
soup.title.string
- 1
"The Dormouse's story"
- 1
soup.title.text
- 1
"The Dormouse's story"
- 1
soup.title.parent.name
- 1
'head'
- 1
soup.p
- 1
<p class="title"><b>The Dormouse's story</b></p>
- 1
soup.p.name
- 1
'p'
- 1
soup.p["class"]
- 1
['title']
- 1
soup.a
- 1
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
- 1
soup.find("a")
- 1
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
- 1
soup.find_all("a")
- 1
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
- 1
- 2
- 3
从文档中找到所有的< a>标签的链接
for link in soup.find_all("a"): print(link.get("href"))
- 1
- 2
http://example.com/elsie
http://example.com/lacie
http://example.com/tillie
- 1
- 2
- 3
在文档中获取所有的文字内容
print(soup.get_text())
- 1
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
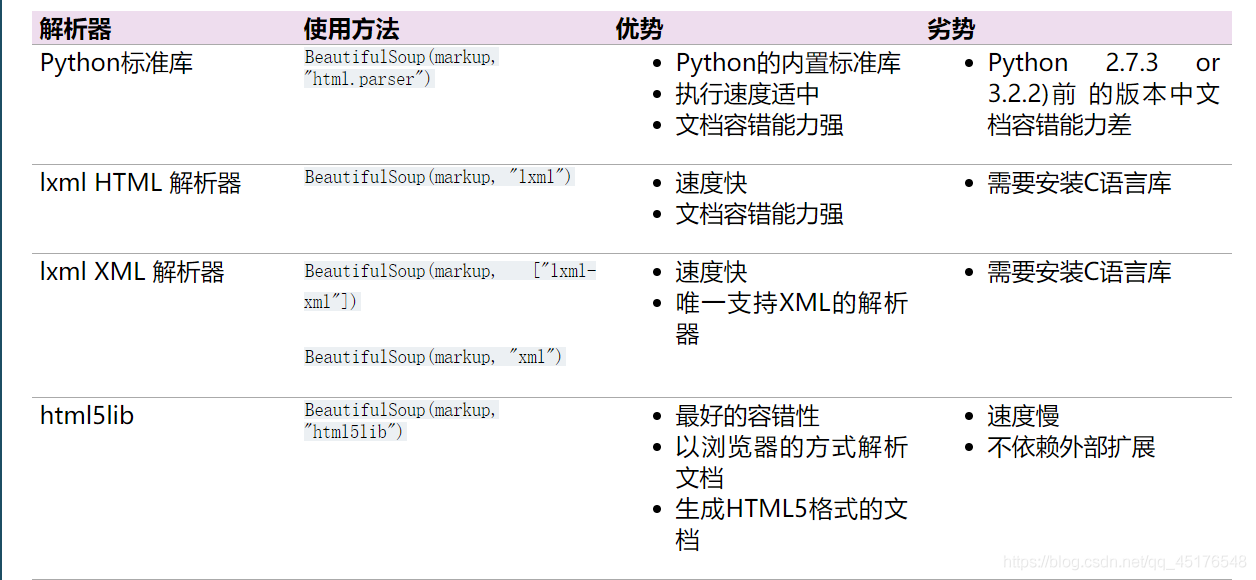
常见解释器的优缺点
Tag
- Tag有很多方法和属性,在 遍历文档树 和 搜索文档树 中有详细解释.现在介绍一下tag中最重要的属性: name和attributes
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
tag
- 1
- 2
- 3
<b class="boldest">Extremely bold</b>
- 1
type(tag)
- 1
bs4.element.Tag
- 1
Name
- 每个tag都有自己的名字,通过 .name 来获取:
tag.name
- 1
'b'
- 1
- 如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档
tag.name = "blockquote"
tag
- 1
- 2
<blockquote class="boldest">Extremely bold</blockquote>
- 1
Attributes
- 一个tag可能有很多个属性.tag 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同:
tag["class"]
- 1
['boldest']
- 1
tag.attrs
- 1
{'class': ['boldest']}
- 1
- tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样
tag["class"] = "verybold"
tag["id"] = 1
tag
- 1
- 2
- 3
<blockquote class="verybold" id="1">Extremely bold</blockquote>
- 1
del tag["class"]
tag
- 1
- 2
<blockquote id="1">Extremely bold</blockquote>
- 1
多值属性
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.p['class']
- 1
- 2
['body', 'strikeout']
- 1
css_soup = BeautifulSoup('<p class="body"></p>')
css_soup.p['class']
- 1
- 2
['body']
- 1
可以遍历的字符串
- 字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串:
tag.string
- 1
'Extremely bold'
- 1
type(tag.string)
- 1
bs4.element.NavigableString
- 1
-
一个 NavigableString 字符串与Python中的Unicode字符串相同,
并且还支持包含在遍历文档树 和 搜索文档树 中的一些特性.
通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串: -
tag中包含的字符串不能编辑,但是可以被替换成其他的字符串,用replace_with()方法
tag.string.replace_with("No longer bold")
tag
- 1
- 2
<blockquote id="1">No longer bold</blockquote>
- 1
BeautifulSoup
- BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
- 因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attribute属性.但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .name
soup.name
- 1
'[document]'
- 1
注释及特殊字符串
- 文档的注释部分
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
comment
- 1
- 2
- 3
- 4
'Hey, buddy. Want to buy a used parser?'
- 1
type(comment)
- 1
bs4.element.Comment
- 1
- Comment 对象是一个特殊类型的 NavigableString 对象:
comment
- 1
'Hey, buddy. Want to buy a used parser?'
- 1
但是当它出现在HTML文档中时, Comment 对象会使用特殊的格式输出:
print(soup.prettify())
- 1
<html>
<body>
<b> <!--Hey, buddy. Want to buy a used parser?-->
</b>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
from bs4 import CData
cdata = CData("A CDATA block")
comment.replace_with(cdata)
print(soup.b.prettify())
- 1
- 2
- 3
- 4
<b>
<![CDATA[A CDATA block]]>
</b>
- 1
- 2
- 3
遍历文档树
html_doc = """
<html><head><title>The Dormouse's story</title></head> <body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
from bs4 import BeautifulSoup
- 1
soup = BeautifulSoup(html_doc,"html.parser")
- 1
子节点
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点.Beautiful Soup提供了许多操作和遍历子节点的属性.
soup.head
- 1
<head><title>The Dormouse's story</title></head>
- 1
soup.title
- 1
<title>The Dormouse's story</title>
- 1
这是个获取tag的小窍门,可以在文档树的tag中多次调用这个方法.下面的代码可以获取标签中的第一个标签:
soup.body.b
- 1
<b>The Dormouse's story</b>
- 1
通过点取属性的方式只能获得当前名字的第一个tag:
soup.a
- 1
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
- 1
- find_all
如果想要得到所有的标签,或是通过名字得到比一个tag更多的内容的时候,就需要用到 Searching the tree 中描述的方法,比如: find_all()
soup.find_all("a")
- 1
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
- 1
- 2
- 3
.contents和.children
head_tag = soup.head
head_tag
- 1
- 2
<head><title>The Dormouse's story</title></head>
- 1
head_tag.contents
- 1
[<title>The Dormouse's story</title>]
- 1
head_tag.contents[0]
- 1
<title>The Dormouse's story</title>
- 1
head_tag.contents[0].contents
- 1
["The Dormouse's story"]
- 1
BeautifulSoup 对象本身一定会包含子节点,也就是说标签也是 BeautifulSoup 对象的子节点:
soup.contents
- 1
['\n',
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
len(soup.contents)
- 1
2
- 1
soup.contents[0].name
- 1

到这里就结束了,如果对你有帮助,欢迎点赞关注评论,你的点赞对我很重要
文章来源: blog.csdn.net,作者:北山啦,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_45176548/article/details/109144737

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)