一篇文章“简单”认识《卷积神经网络》(更新版)

一、概念了解
前言
卷积神经网络(Convolutional Neural Network, CNN),对于图像处理有出色表现,在计算机视觉中得到了广泛的应用。
卷积神经网络通过卷积层与池化层的叠加实现对输入数据的特征提取,最后连接全连接层实现分类。
基于什么提出卷积神经网络?
动物视觉系统对外界的感知是:
- 视觉皮层的每个神经元只响应某些特定区域的刺激(感受野)
- 从局部到全局(信息分层处理机制)
卷积神经网络:
每个神经元只需对 局部图像 进行感知;
在更高层将局部的信息综合起来,得到全局信息;
卷积(Convolution)
每一个卷积核,相对于一个滤波器;它会筛选合适的信息,过滤不匹配的信息。
比如,卷积核a,它是用来提取出图片的形状信息;卷积核b,它是用来提取出图片的颜色信息;
池化 (Pooling)
池化操作是降采样(Subsampling)中的一种;为了描述大的图像,可以对不同位置的特征进行聚合统计;
采用图像区域上某个特征的平均值或最大值,维度低且有效(不容易过拟合)。
优势
卷积神经网络十分合适用于大尺寸图像的学习;
- 训练参数少(卷积操作、权值共享、池化操作 减少了训练的参数)
- 平移不变性(图像被平移,卷积依然保证能检测到它的特征)
- 模式具有空间层次(当浅层的神经元学习到较小的局部模式后,后面的卷积层会将前一层学习到的模式组合成更高的模式)
二、进一步理解
前言
卷积神经网络(Convolutional Neural Network, CNN),是一种前馈神经网络,对于图像处理有出色表现,在计算机视觉中得到了广泛的应用。
卷积神经网络 主要包括卷积层(convolution layer)、池化层(pooling layer)和全连接层(fully connected layer)。
卷积神经网络通过卷积层与池化层的叠加实现对输入数据的特征提取,最后连接全连接层实现分类。
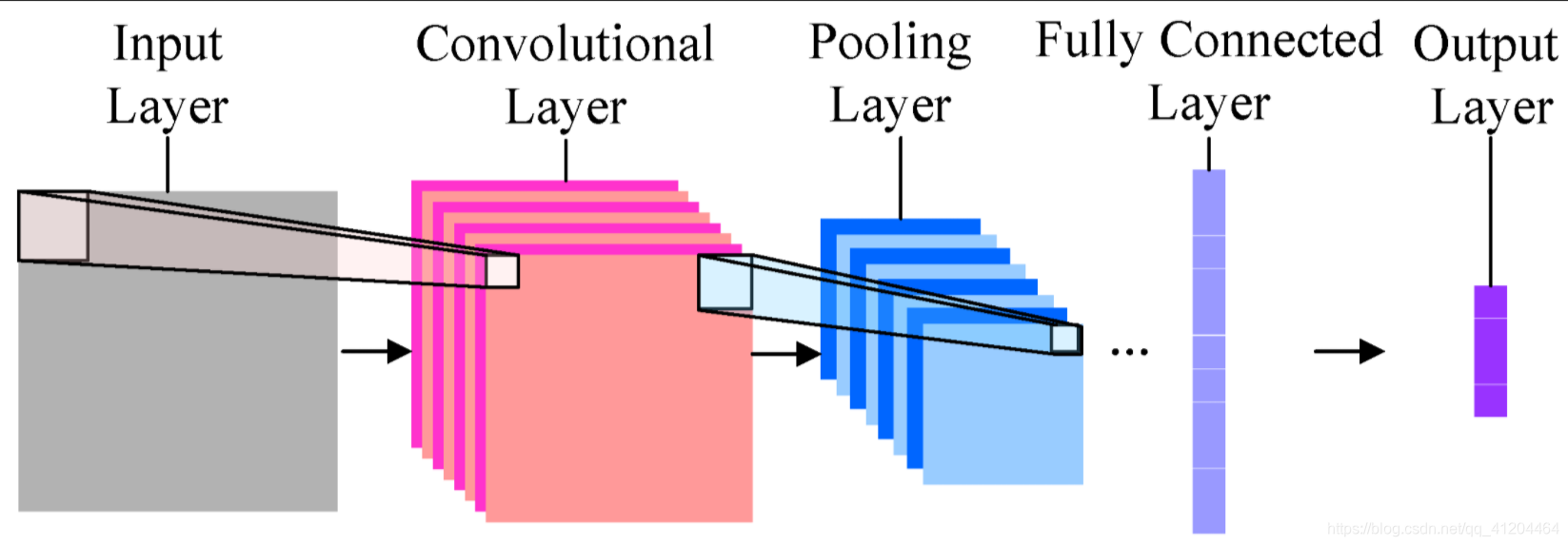
卷积神经网络通过卷积操作和池化操作学习输入特征的局部模式;随着网络层数的增加,卷积神经网络对这些局部模式不断地进行组合、抽象,最终学习到高级特征。
卷积神经网络 能提取图像的特征,避免了对图像的复杂前期预处理,而可以直接输入图像原始图像。即:卷积层+池化层 用来提取特征;全连接层用来分类等。
基于什么提出卷积神经网络?
动物视觉系统对外界的感知是:
- 视觉皮层的每个神经元只响应某些特定区域的刺激(感受野)
- 从局部到全局(信息分层处理机制)
卷积神经网络:
每个神经元只需对 局部图像 进行感知;
在更高层将局部的信息综合起来,得到全局信息;
卷积(Convolution)
简介
卷积滤波,每一个卷积核,相对于一个滤波器;它会筛选合适的信息,过滤不匹配的信息。
比如,卷积核a,它是用来提取出图片的形状信息;卷积核b,它是用来提取出图片的颜色信息;
一个卷积核提取到的特征对应一个通道(上图:二维矩阵),不同卷积核得到的特征进行堆叠,形成具有多个不同通道的特征立方体。
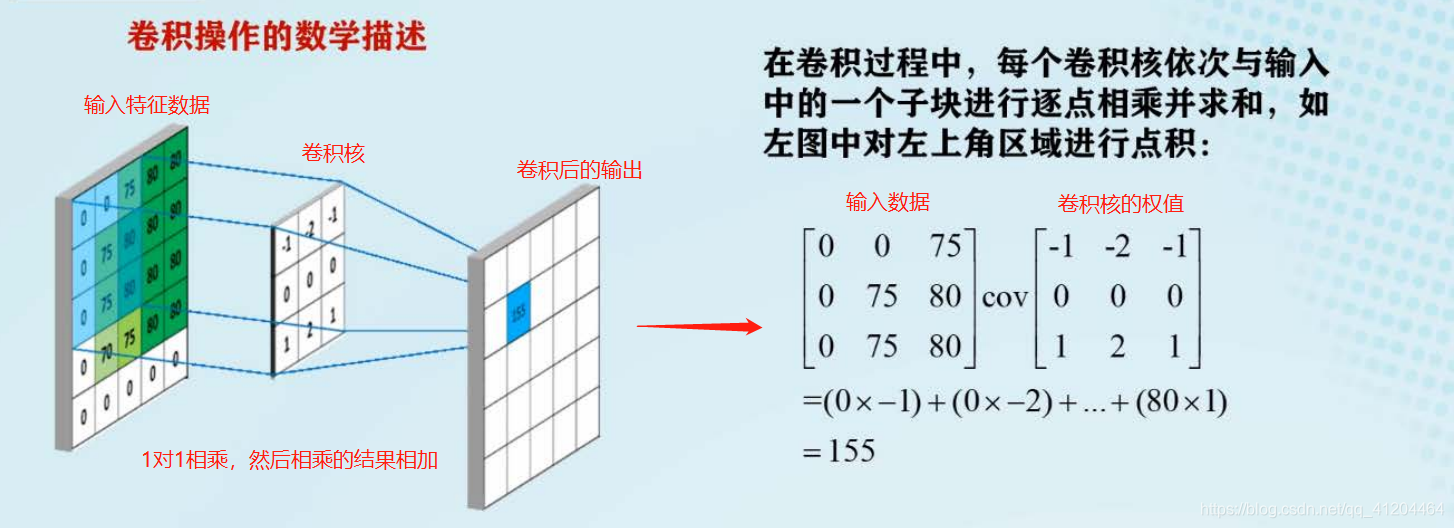
卷积操作
几个重要的参数
- 卷积和尺寸:感受野的大小,通常指卷积核的长和宽;比如:3*3,5*5的卷积核
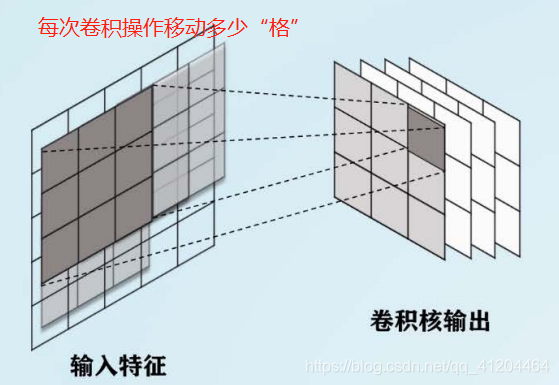
- 卷积核步长:卷积核在长度方向核宽度方向上每次一点的距离。比如:步长为1,每次移动一格;步长为3,每次移动三格;
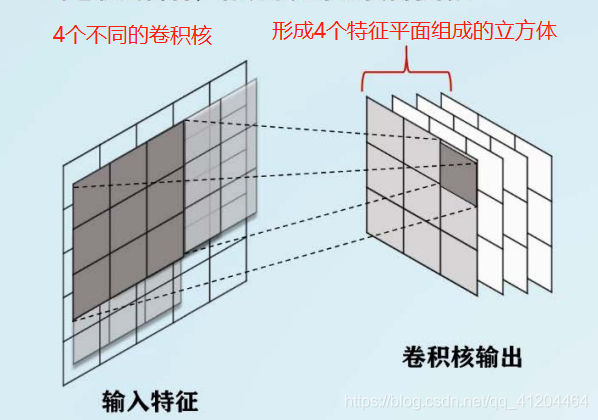
- 卷积核数量:卷积核的数量对应卷积核输出特征的深度,每个卷积核的输出为一个通道,多个卷积核的输出进行堆叠,形成一个特征立方体。比如:一共有4个不同的卷积核,那么形成4个平面组成的立方体。
图像化
卷积和尺寸:感受野的大小,通常指卷积核的长和宽;比如:3*3,5*5的卷积核
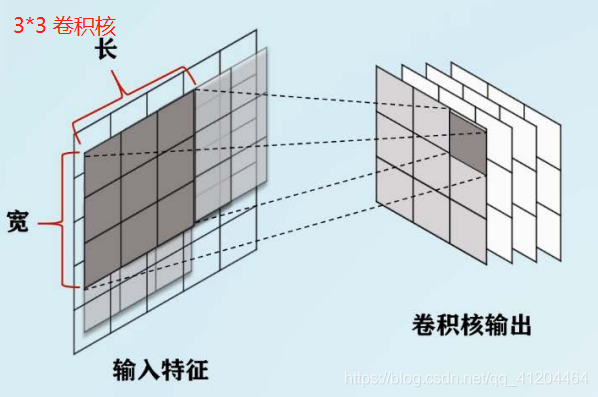
卷积核步长:卷积核在长度方向核宽度方向上每次一点的距离。比如:步长为1,每次移动一格;步长为3,每次移动三格;移动方向,通常是从左到右:
卷积核数量:卷积核的数量对应卷积核输出特征的深度,每个卷积核的输出为一个通道,多个卷积核的输出进行堆叠,形成一个特征立方体。比如:一共有4个不同的卷积核,那么形成4个通道(特征平面)组成的立方体。
池化(Pooling)
池化操作是降采样(Subsampling)中的一种;为了描述大的图像,可以对不同位置的特征进行聚合统计;
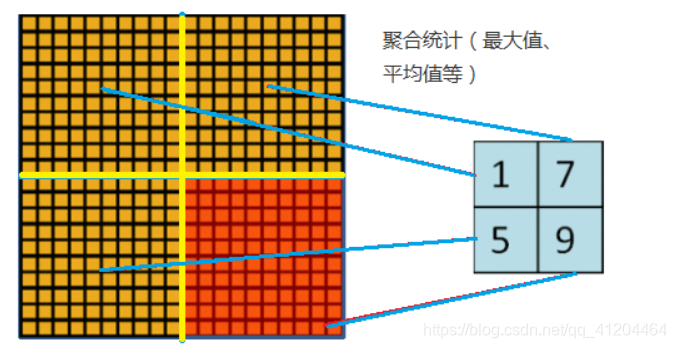
采用图像区域上某个特征的平均值或最大值,维度低且有效(不容易过拟合)。
特征维度变化
卷积神经网络中的卷积层核池化层会改变输入特征的维度;
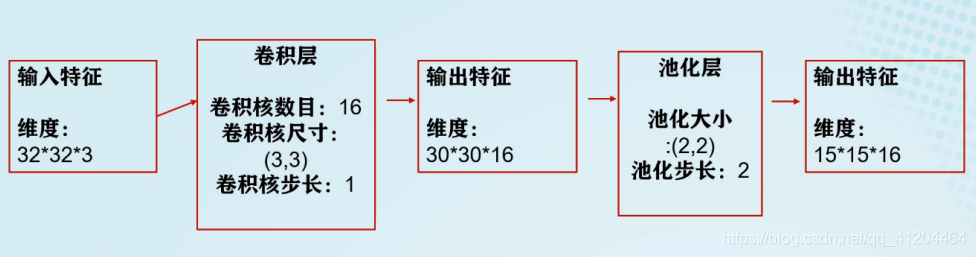
优势
卷积神经网络十分合适用于大尺寸图像的学习;
- 训练参数少(卷积操作、权值共享、池化操作 减少了训练的参数)
- 平移不变性(图像被平移,卷积依然保证能检测到它的特征)
- 模式具有空间层次(当浅层的神经元学习到较小的局部模式后,后面的卷积层会将前一层学习到的模式组合成更高的模式)
经典的卷积神经网络
LeNet模型
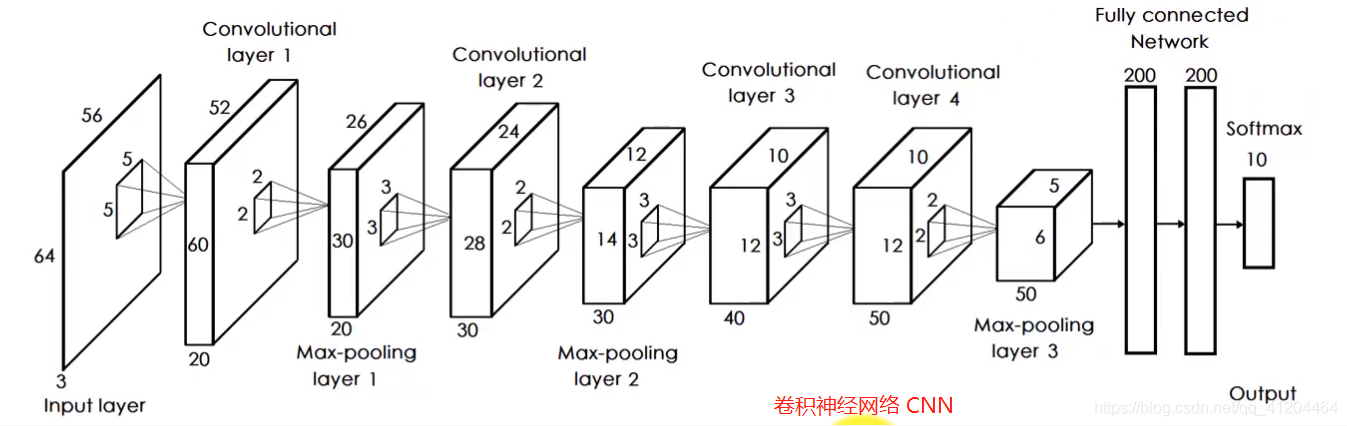
LeNet-5 输入的二维图像,先经过两次的( 卷积层->池化层 ),再经过全连接层,最后使用softmax分类作为输出层。
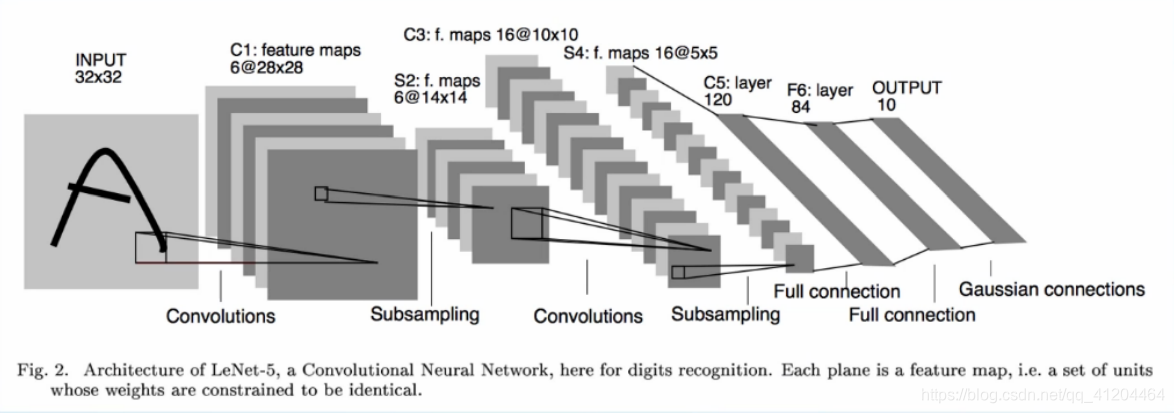
LeNet-5 是用于手写体字符识别的卷积神经网络。
输入:32*32的手写字体图片,这些手写字体包含0~9数字,也就是相当于10个类别的图片
输出:分类结果,0~9之间的一个数
VGGNet模型
VGGNet模型是2014年的 ImageNet分类的亚军,物体检测冠军,使用了更小的卷积核(3x3),并且连续多层组合使用。VGG Net 经常被用来提取图像特征。
该模型有多种网络架构,较为常用的是VGG16和VGG19。
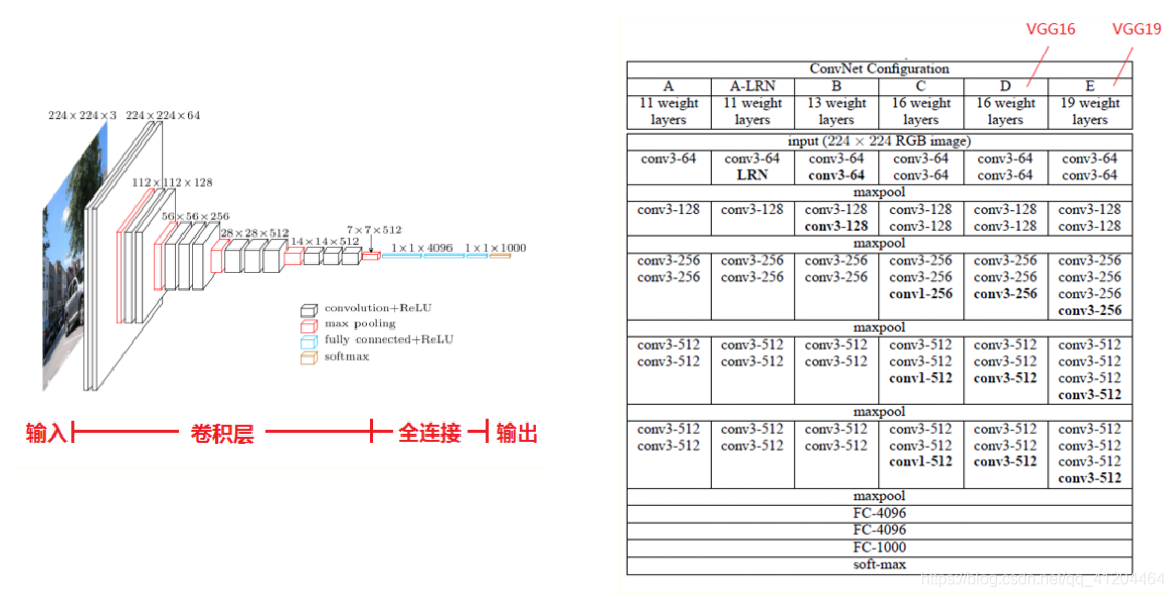
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
GoogLeNet模型
GoogLeNet模型是2014年的ImageNet分类的冠军, GoogleNet提出了一种 Inception结构,该结构可以将不同的卷积层通过并联的方式结合在一起。 Inception历经了1、V2、3、V4等多个版本的发展,不断趋于完善。
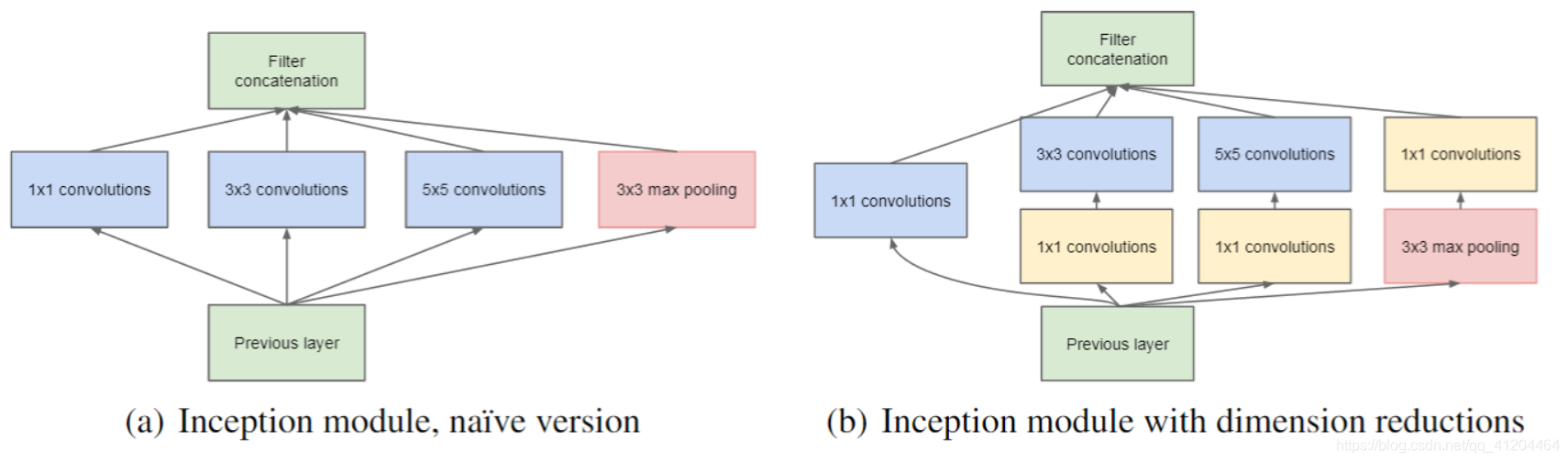
保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
卷积神经网络应用
- 图像分类
- 目标检测
- 目标跟踪
- 语义分割
- 实例分割
参考:
1)西安电子科技大学《人工智能导论》课程;
2)北京交通大学《图像处理与机器学习》课程;
3)http://yann.lecun.com/exdb/lenet/index.html
4)https://zhuanlan.zhihu.com/p/43143470
5)https://my.oschina.net/u/876354/blog/1632862
6)https://www.cnblogs.com/ai-learning-blogs/p/11110391.html
如有错误,欢迎指出;欢迎交流~
文章来源: guo-pu.blog.csdn.net,作者:一颗小树x,版权归原作者所有,如需转载,请联系作者。
原文链接:guo-pu.blog.csdn.net/article/details/115451144

- 点赞
- 收藏
- 关注作者
评论(0)