Selenium 高级点儿的技能都有啥???

今天是持续写作的第 27 / 100 天。
如果你有想要交流的想法、技术,欢迎在评论区留言。
Selenium 除了对网页的基本操作以外,还有一些进阶技巧,接下来的将通过两篇文章为你说明。

滑块验证是验证码的一种进化,在 2020 年已经不经常见到了,大多数都已经被滑动拼图验证码给替代了,但是也有少数的网站,依旧采用滑动验证,例如天猫注册页面,携程注册页面。

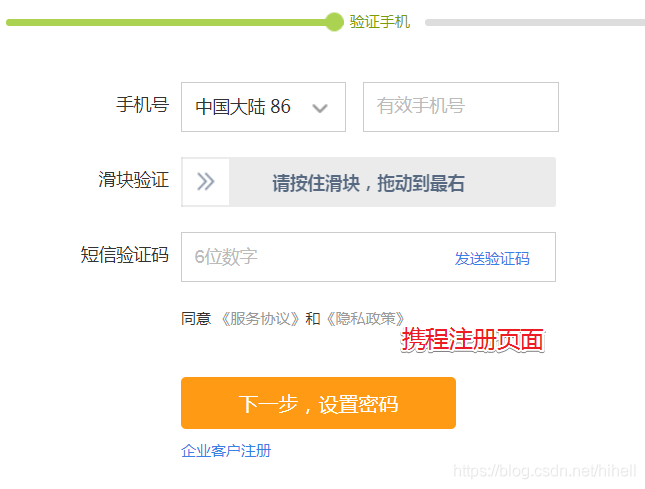
本篇博客以天猫注册为例,为你说明如何解决滑块验证码的问题。
步骤如下:
- 打开天猫注册页面;
- 同意注册协议;
- 拖动滑块到最右侧。
打开注册页面,点击同意
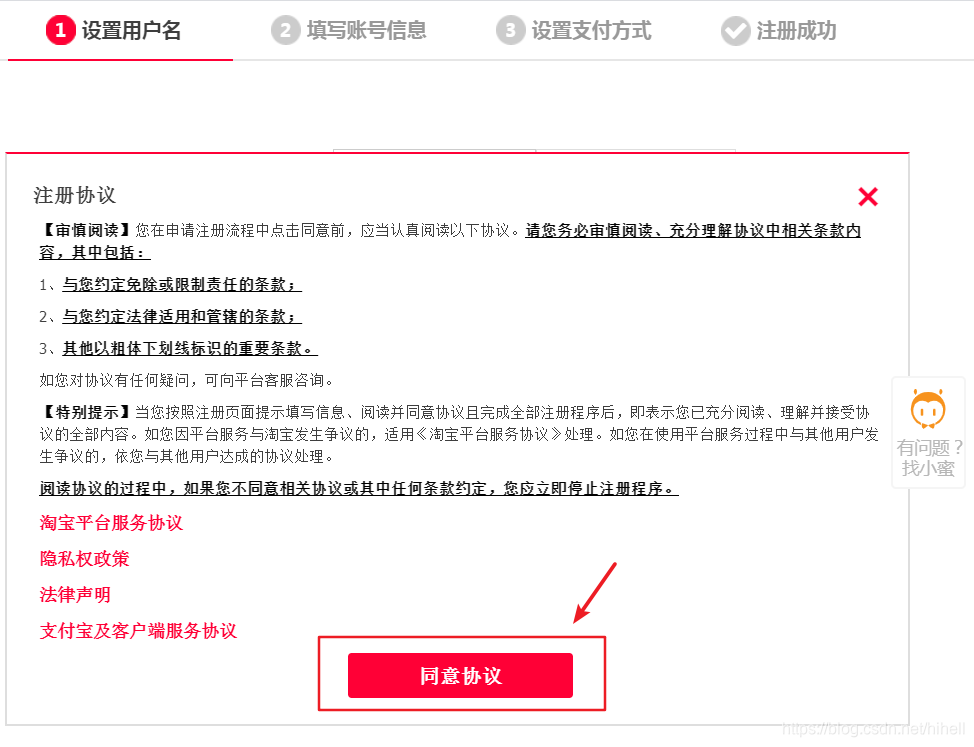
打开页面,查看一下同意协议按钮,重点查看如何获取到按钮元素。

在执行代码之后,发现出现问题了,打开天猫注册页面 https://register.tmall.com/的源码,里面竟然没有要获取的标签,而是嵌套了一个子网页,厉害~

检查之后,发现真正的注册地址如下:
https://reg.taobao.com/member/reg/fill_mobile.htm
- 1
有了真实的地址就可以进行代码的编写了。
from selenium import webdriver
import time
driver = webdriver.Firefox()
# 浏览器最大化
driver.maximize_window()
# 打开注册页面
driver.get('https://reg.taobao.com/member/reg/fill_mobile.htm')
# 点击同意协议按钮 J_AgreementBtn
driver.find_element_by_id("J_AgreementBtn").click()
time.sleep(5)
driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
寻找滑块区域与滑块
点击同意协议之后就是寻找滑块的过程了,通过开发者工具进行定位。

最终多次尝试之后,得到的代码如下:
# 发现滑块区域部分代码
scale = driver.find_element_by_id("nc_1_n1t")
print(scale.size)
# 发现区域滑块
sc = driver.find_element_by_by_id("nc_1_n1z")
print(sc.size)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
实现拖动环节
拖动咱采用 Selenium 给提供的 drag_and_drop_to_offset 方法。具体代码如下,以下代码过程中存在微调,也就是说需要反复调整参数,最终实现理想的效果。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Firefox()
# 浏览器最大化
driver.maximize_window()
# 打开注册页面
driver.get('https://reg.taobao.com/member/reg/fill_mobile.htm')
# 点击同意协议按钮 J_AgreementBtn
driver.find_element_by_id("J_AgreementBtn").click()
# 发现滑块区域部分代码
scale = driver.find_element_by_id("nc_1_n1t")
print(scale.size)
# 发现区域滑块
source = driver.find_element_by_id("nc_1_n1z")
print(source.size)
# 拖拽滑块,从左侧拖拽到右侧
ActionChains(driver).drag_and_drop_by_offset(source,scale.size["width"],source.size["height"]).perform()
time.sleep(5)
driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
具体实现代码的效果出现之后,还是非常有意思的,希望你可以运行一下。
Selenium 实现截图操作
通过 Selenium 实现截图在自动化测试中有两个目的,一个是截取错误信息,方便测试,另一个是捕获验证码,方便后续处理。
网页截图操作
实现网页截图非常简单,直接用 Selenium 自带的 save_screenshot 方法即可,有了这个方法之后,你碰到的网页在也不用安装插件进行截图了,可以自己写一个小程序。
driver.save_screenshot("dangdang.png")
- 1
直接使用获取的是浏览器访问网页首屏的截图,如何实现截取完整网页呢?只需要通过 JS 即可解决。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Firefox()
# 打开注册页面
driver.get('http://www.dangdang.com/')
# 通过 JS 代码获取网页的宽度和高度
width = driver.execute_script("return document.documentElement.scrollWidth")
height = driver.execute_script("return document.documentElement.scrollHeight")
# 设置浏览器的宽高
driver.set_window_size(width, height)
time.sleep(5)
driver.save_screenshot("dangdang.png")
driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
指定元素截图
元素截图,其实是配合另一个库完成的,该库为 pillow,专门用于处理图像的库。
通过 pip install pillow 安装新库。
接下来以途牛旅游网注册页面为例,给你演示一下如何截取指定元素。注意下面代码获取网页元素坐标的方法,后来发现方法不是很好用,进行了 N 多的尝试,试出来的数字。不同的网站解决办法不同,可以自行试一下。
from selenium import webdriver
import time
from PIL import Image
driver = webdriver.Firefox()
driver.maximize_window()
# 打开注册页面
driver.get('https://passport.tuniu.com/register')
time.sleep(3)
# 截取全屏
driver.save_screenshot("./tuniu.png")
# 找到验证码区域 identify_img
code = driver.find_element_by_id("identify_img")
# 获取元素在网页中的坐标,这个地方通过代码不太准确,尝试了多次取值
left = 1040 # code.location['x']
up = 590 #code.location['y']
print(code.size["width"],code.size["height"])
right = left + code.size["width"]
below = up + code.size["height"]
im = Image.open('./tuniu.png')
im = im.crop((left, up, right, below))
im.save("./code.png")
driver.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
拿到验证码图片之后,可以通过一些打码平台实现自动登录某些网站。
写在后面
本篇博客主要介绍了 Selenium 滑块操作、网页/元素截图两个知识点,学习完成之后相信你对 Selenium 的认知又有所提高。
如果你想跟博主建立亲密关系,可以关注同名公众号 梦想橡皮擦,近距离接触一个逗趣的互联网高级网虫。
博主 ID:梦想橡皮擦,希望大家点赞、评论、收藏。
文章来源: blog.csdn.net,作者:梦想橡皮擦,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/hihell/article/details/111327362

- 点赞
- 收藏
- 关注作者
评论(0)