[mysql] 17.4 mysql MGR 组复制操作指南

- 组复制以以下不同模式运行:
-
single-primary 模式
-
multi-primary 模式
默认模式为单主模式。不同的模式之间互斥的,例如,一个以多主要模式配置,而另一个则无法以单主要模式配置。要在模式之间切换,需要使用其他操作配置重新启动组(不是是服务)。无论采用哪种部署模式,组复制都不会处理客户端故障转移,而客户端故障转移必须由应用程序本身,连接器或中间件框架(例如代理或MySQL Router 8.0)来处理。
在多主模式下部署时,需要检查语句以确保它们与该模式兼容。在多主模式下部署组复制时,将进行以下检查:
-
如果在SERIALIZABLE隔离级别下执行事务,则在与组同步时,其提交将失败。
-
如果事务是针对具有具有级联约束的外键的表执行的,则该事务在与组同步时将无法提交。
这些检查可以通过设置 group_replication_enforce_update_everywhere_checks 到FALSE来禁用。在单主要模式下部署时,此选项必须设置为 FALSE。
17.4.1.1 Single-Primary (单主模式)
在此模式下,组具有唯一读写模式的服务器。组中的所有其他成员都设置为只读模式(带有 super-read-only=ON )。这是自动的。主服务器通常是引导该组的第一台服务器,所有其他加入的服务器会自动识别到主服务器,并设置为只读。
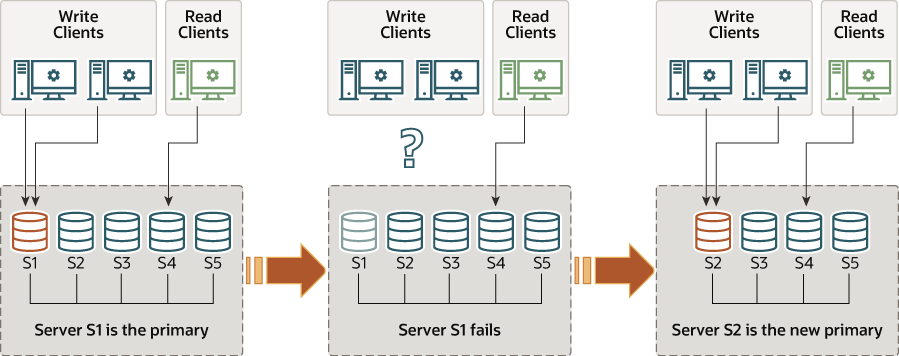
在单主模式下,由于系统强制只有一个服务可以写入,因此禁用了在多主模式下的某些检查。例如,允许对具有级联外键的表进行更改,而在多主键模式下则不允许更改。当主要成员失败时,自动的主要选举机制将选择新的主要成员。选举过程主要根据 group_replication_member_weight的值来进行排序。假设该组的所有成员都运行相同的MySQL版本,则该成员具有最高 group_replication_member_weight 数值的被选为新的主库。如果多个服务器具有相同 group_replication_member_weight数值的服务,则将根据服务器的server_uuid字典顺序对其进行优先级排序,并选择第一个服务。选出新的主数据库后,它将自动设置为可读写,其他辅助数据库仍保留为辅助数据库,仍为只读。
当一个新的主当选,它仅是可写的,直到处理了完所有原主服务的事务。这样可以避免旧的主事务中的旧事务与在该成员上执行的新事务之间可能发生的并发问题。在新的主数据库重新路由客户端应用程序之前,最好等待新的主数据库应用其复制相关的中继日志。
如果该组与运行不同版本MySQL的成员一起运行,则选举过程可能会受到影响。例如,如果任何成员不支持 group_replication_member_weight,那么将根据server_uuid 较低主要版本成员的顺序选择 主服务。或者,如果运行不同MySQL版本的所有成员都支持 group_replication_member_weight,group_replication_member_weight 则从较低主要版本的成员中选择主。
17.4.1.2 Multi-Primary Mode(多主模式)
在多主模式下,没有单主概念。由于没有服务器扮演任何特殊角色,因此无需参与选举程序。
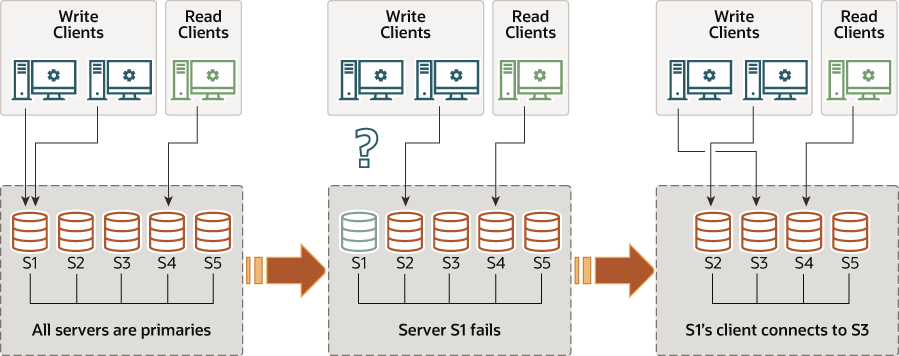
加入组时,所有服务器均设置为读写模式。
以下示例显示了在单主模式下,如何找出当前哪个服务器是主服务器。
mysql> SHOW STATUS LIKE 'group_replication_primary_member'17.4.2 调优 Recovery
每当新成员加入复制组时,它都会连接到合适的donor ,并获取丢失的数据,直到将其声明的恢复点为止。组复制中的这一关键组件是容错的并且是可配置的。
整个恢复过程中,另一个值得关注的主要问题是确保它可以应对故障。因此,组复制提供了可靠的错误检测机制。在早期版本的组复制中,当与donor联系时,恢复只能检测到由于身份验证问题或其他问题引起的连接错误。对此类问题场景的反应是切换到新的donor,因此尝试与其他成员进行新的连接。
其他失败场景:
-
数据被清除如果选定的donor恢复过程中需要一些清除过的数据,则会发生错误。恢复检测到此错误,并选择了新的donor。
-
重复数据-如果加入该组的服务器已经包含一些与恢复期间来自选定donor的数据冲突的数据,则会发生错误。这可能是由于加入该组的服务器中存在一些错误的事务引起的。
另外一方面看,恢复应该失败,而不是转移到另一个donor,但是在异构组织中,一些成员有可能共享有冲突的事务,而其他成员则没有。出于这个原因,一旦出错,恢复就会从组中选择另一个donor。
-
其他错误-如果任何恢复线程失败(接收者线程或应用线程失败),则会发生错误,并且恢复切换到新的dono
恢复数据传输依赖于二进制日志和现有的MySQL复制框架,因此,某些临时错误可能会导致接收方或应用线程中的错误。在这种情况下,供体切换过程具有重试功能,类似于常规复制中的功能。
重试次数
尝试从donor 池连接到donor 时,加入组的服务器尝试尝试的次数为10。这是通过group_replication_recovery_retry_count 插件变量配置的 。以下命令将尝试连接到供体的最大尝试次数设置为10。
mysql> SET GLOBAL group_replication_recovery_retry_count= 10;请注意,这说明了加入该组的服务器尝试连接到每个合适的donors的全局尝试次数。
Sleep Routines(休眠策略)
group_replication_recovery_reconnect_interval 插件变量定义多少时间恢复过程中应donor的连接尝试之间sleep。此变量的默认设置为60秒,您可以动态更改此值。以下命令将恢复施主连接重试间隔设置为120秒。
mysql> SET GLOBAL group_replication_recovery_reconnect_interval= 120;但是请注意,每次donor 连接尝试后恢复都不会停止。由于加入该组的服务器正在连接到不同的服务器,而不是一遍又一遍地连接到同一台服务器,因此可以假定影响服务器A的问题不影响服务器B。因此,仅当恢复所有服务器的donor后,恢复才可能会挂起。一旦加入该组的服务器尝试连接到该组中所有合适的donor,并且没有剩余者,恢复过程将根据group_replication_recovery_reconnect_interval 变量配置的秒数进入休眠 。
17.4.3 Network Partitioning(网络分区)
每当需要复制的更改发生时,小组就需要达成共识。常规事务就是这种情况,但组成员身份更改和一些使组保持一致的内部消息传递也是必需的。共识要求大多数小组成员同意给定的决定。当大多数组成员丢失时,该组将无法继续前阻止,因为它无法确保多数或法定人数。
当发生多个非自愿故障时,仲裁可能会丢失,从而导致大多数服务器突然从组中删除。例如,在一组5台服务器中,如果其中3台立即变为静默状态,则大多数服务器将受到损害,因此无法实现仲裁。实际上,其余两个服务器无法判断其他3台服务器是否崩溃,或者网络分区是否单独隔离了这2台服务器,因此无法自动重新配置该组。
另一方面,如果服务器自愿退出该组,则它们会指示该组重新配置自身。实际上,这意味着要离开的服务器会告诉其他人它要离开。这意味着其他成员可以正确地重新配置组,维护成员身份的一致性,并重新计算大多数成员。例如,在上述5台服务器同时3台离开的情况下,如果3台离开的服务器逐个警告组他们要离开的组,则成员资格可以将自己从5台调整为2台时间,确保达到法定人数。
replication_group_members z这个性能模式表显示每个服务器在当前视图下的服务状态。在大多数情况下,系统没有运行到分区,因此该表显示的信息在组中的所有服务器之间都是一致的。换句话说,该表中每个服务器的状态在当前视图中被所有人同意。但是,如果存在网络分区,并且仲裁丢失,那么该表将显示UNREACHABLE 其无法联系的那些服务器的状态。该信息由组复制中内置的本地故障检测器导出。
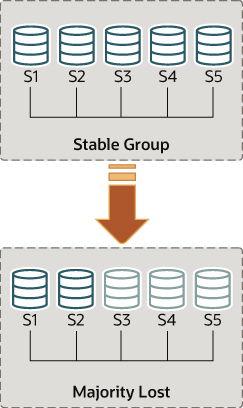
为了了解这种类型的网络分区,以下部分描述了一个场景,其中最初有5台服务器正常工作,然后只有2台服务器处于联机状态,然后对组进行了更改。图中描绘了该场景。
因此,假设其中有一个包含这5个服务器的组:
-
具有成员标识符的服务器s1
199b2df7-4aaf-11e6-bb16-28b2bd168d07 -
具有成员标识符的服务器s2
199bb88e-4aaf-11e6-babe-28b2bd168d07 -
具有成员标识符的服务器s3
1999b9fb-4aaf-11e6-bb54-28b2bd168d07 -
具有成员标识符的服务器s4
19ab72fc-4aaf-11e6-bb51-28b2bd168d07 -
具有成员标识符的服务器s5
19b33846-4aaf-11e6-ba81-28b2bd168d07
最初,该组运行良好,服务器之间彼此通信愉快。可以通过登录s1并查看其replication_group_members 性能表来验证这一点 。例如:
mysql> SELECT MEMBER_ID,MEMBER_STATE, MEMBER_ROLE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+-------------+
| MEMBER_ID | MEMBER_STATE |-MEMBER_ROLE |
+--------------------------------------+--------------+-------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | ONLINE | SECONDARY |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE | PRIMARY |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE | SECONDARY |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | ONLINE | SECONDARY |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | ONLINE | SECONDARY |
+--------------------------------------+--------------+-------------+但是,片刻之后发生了灾难性故障,服务器s3,s4和s5意外停止。此后几秒钟,再次replication_group_members查看s1上的表显示该 表仍处于联机状态,但其他几个成员不在。实际上,如下所示,它们标记为 UNREACHABLE。而且,系统无法重新配置自身以更改成员资格,因为大多数已经丢失。
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+该表显示s1现在位于没有外部干预就无法进行升级的组中,因为大多数服务器无法访问。在这种特殊情况下,需要重置组成员资格列表以使系统继续运行,这在本节中进行了说明。或者,可以选择停止s1和s2上的组复制(或完全停止s1和s2),找出s3,s4和s5发生了什么,然后重新启动组复制(或服务器)。
组复制使您可以通过强制进行特定配置来重置组成员资格列表。例如,在上面的示例中,其中s1和s2是唯一的联机服务器,您可以选择强制仅由s1和s2组成的成员资格配置。这需要检查有关s1和s2的一些信息,然后使用该 group_replication_force_members 变量。
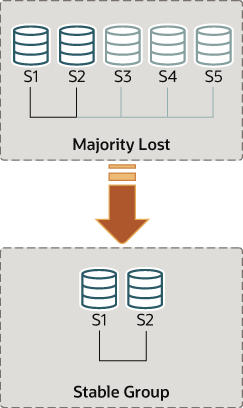
假设又回到了s1和s2是组中剩下的唯一服务器的情况。服务器s3,s4和s5意外离开了该组。为了使服务器s1和s2继续运行,您想强制仅包含s1和s2的成员资格配置。
该程序使用 group_replication_force_members 并且应被视为最后的补救措施。必须格外小心地使用它 ,并且仅用于使仲裁无效。如果使用不当,它可能会创建人为裂脑方案或完全阻塞整个系统。
回想一下,系统已被阻塞,当前配置如下(如s1上的本地故障检测器所感知):
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+首先要做的是检查s1和s2的本地地址(组通信标识符)是什么。登录到s1和s2并按以下方式获取该信息。
mysql> SELECT @@group_replication_local_address;一旦知道了s1(127.0.0.1:10000)和s2(127.0.0.1:10001)的组通信地址,就可以在两个服务器之一上使用它来注入新的成员资格配置,从而覆盖丢失了仲裁的现有成员资格配置。要在s1上执行此操作:
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";通过强制执行其他配置,可以解除对组的阻止。replication_group_members更改后,请同时检查s1和s2以验证组成员身份。首先在s1上。
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+然后在s2上.
mysql> SELECT * FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+强制执行新的成员配置时,请确保将要从组中强制退出的所有服务确实需要停止。在上述情况下,如果s3,s4和s5并非真正不可访问而是在线,则它们可能已经形成了自己的功能分区(5分之3,因此占大多数)。在这种情况下,将组成员列表强制为s1和s2可能会造成人为的裂脑情况。因此,在强制执行新的成员资格配置之前,确保要排除的服务器确实已关闭是非常重要的;如果没有关闭,请在继续操作之前将其关闭。
使用 group_replication_force_members 系统变量成功强制新的组成员身份并取消阻止该组后,请确保清除系统变量。 group_replication_force_members 必须为空才能发出START GROUP_REPLICATION声明。
注意,也可使用MySQL Enterprise Backup和组复制一起,MySQL Enterprise Backup是MySQL Server的商业许可备份实用程序,可与 MySQL Enterprise Edition一起使用。可以参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/group-replication-enterprise-backup.html

- 点赞
- 收藏
- 关注作者
评论(0)