使用 Inception-v3,实现图像识别(Python、C++)

目录
对于我们的大脑来说,视觉识别似乎是一件特别简单的事。人类不费吹灰之力就可以分辨狮子和美洲虎、看懂路标或识别人脸。但对计算机而言,这些实际上是很难处理的问题:这些问题只是看起来简单,因为大脑非常擅长理解图像。
在过去几年内,机器学习领域在解决此类难题方面取得了巨大进展。尤其是,我们发现一种称为深度卷积神经网络的模型可以很好地处理较难的视觉识别任务 - 在某些领域的表现与人类大脑不相上下,甚至更胜一筹。
研究人员通过用 ImageNet(计算机视觉的一种学术基准)验证其工作成果,证明他们在计算机视觉方面取得了稳步发展。他们陆续推出了以下几个模型,每一个都比上一个有所改进,且每一次都取得了新的领先成果:QuocNet、AlexNet、Inception (GoogLeNet)、BN-Inception-v2。Google 内部和外部的研究人员均发表过关于所有这些模型的论文,但这些成果仍是难以复制的。现在我们将采取后续步骤,发布用于在我们的最新模型 Inception-v3 上进行图像识别的代码。
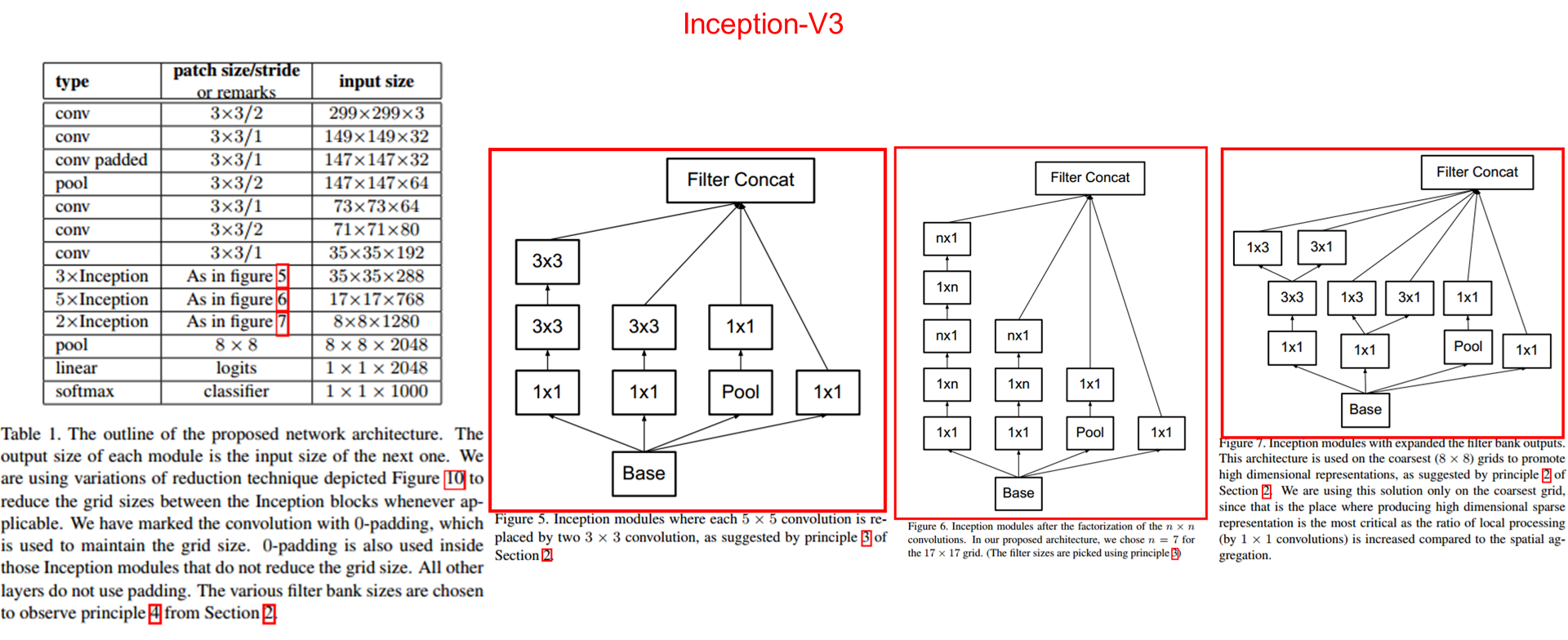
Inception-v3 使用 2012 年的数据针对 ImageNet 大型视觉识别挑战赛训练而成。它的层次结构如下图所示:
Inception-v3处理的是标准的计算机视觉任务,在此类任务中,模型会尝试将所有图像分成 1000 个类别,如 “斑马”、“斑点狗” 和 “洗碗机”。例如,以下是 AlexNet 对某些图像进行分类的结果:

为了比较各个模型,我会检查正确答案不在模型预测的最有可能的 5 个选项中的频率,称为 “top-5 错误率”。 AlexNet 在 2012 年的验证数据集上实现了 15.3% 的 top-5 错误率;Inception (GoogLeNet)、BN-Inception-v2 和 Inception-v3 的 top-5 错误率分别达到 6.67%、4.9% 和 3.46%。
人类在 ImageNet 挑战赛上的表现如何?Andrej Karpathy 曾尝试衡量自己的表现,他发表了一篇博文,提到自己的 top-5 错误率为 5.1%。
本次将介绍如何使用 Inception-v3。小伙伴们将了解如何使用 Python 或 C++ 将图像分成 1000 个类别。此外,我们还将讨论如何从该模型提取更高级别的特征,以重复用于其他视觉任务。
首次运行程序时,classify_image.py 会从 tensorflow.org 下载经过训练的模型。你的硬盘上需要有约 200M 的可用空间。
首先,从 GitHub 克隆 TensorFlow 模型代码库。
cd models/tutorials/image/imagenet
classify_image.py 程序内容如下:
-
from __future__ import absolute_import
-
from __future__ import division
-
from __future__ import print_function
-
-
import argparse
-
import os.path
-
import re
-
import sys
-
import tarfile
-
-
import numpy as np
-
from six.moves import urllib
-
import tensorflow as tf
-
-
FLAGS = None
-
-
# pylint: disable=line-too-long
-
DATA_URL = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz'
-
# pylint: enable=line-too-long
-
-
-
class NodeLookup(object):
-
"""Converts integer node ID's to human readable labels."""
-
-
def __init__(self,
-
label_lookup_path=None,
-
uid_lookup_path=None):
-
if not label_lookup_path:
-
label_lookup_path = os.path.join(
-
FLAGS.model_dir, 'imagenet_2012_challenge_label_map_proto.pbtxt')
-
if not uid_lookup_path:
-
uid_lookup_path = os.path.join(
-
FLAGS.model_dir, 'imagenet_synset_to_human_label_map.txt')
-
self.node_lookup = self.load(label_lookup_path, uid_lookup_path)
-
-
def load(self, label_lookup_path, uid_lookup_path):
-
"""Loads a human readable English name for each softmax node.
-
-
Args:
-
label_lookup_path: string UID to integer node ID.
-
uid_lookup_path: string UID to human-readable string.
-
-
Returns:
-
dict from integer node ID to human-readable string.
-
"""
-
if not tf.gfile.Exists(uid_lookup_path):
-
tf.logging.fatal('File does not exist %s', uid_lookup_path)
-
if not tf.gfile.Exists(label_lookup_path):
-
tf.logging.fatal('File does not exist %s', label_lookup_path)
-
-
# Loads mapping from string UID to human-readable string
-
proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines()
-
uid_to_human = {}
-
p = re.compile(r'[n\d]*[ \S,]*')
-
for line in proto_as_ascii_lines:
-
parsed_items = p.findall(line)
-
uid = parsed_items[0]
-
human_string = parsed_items[2]
-
uid_to_human[uid] = human_string
-
-
# Loads mapping from string UID to integer node ID.
-
node_id_to_uid = {}
-
proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines()
-
for line in proto_as_ascii:
-
if line.startswith(' target_class:'):
-
target_class = int(line.split(': ')[1])
-
if line.startswith(' target_class_string:'):
-
target_class_string = line.split(': ')[1]
-
node_id_to_uid[target_class] = target_class_string[1:-2]
-
-
# Loads the final mapping of integer node ID to human-readable string
-
node_id_to_name = {}
-
for key, val in node_id_to_uid.items():
-
if val not in uid_to_human:
-
tf.logging.fatal('Failed to locate: %s', val)
-
name = uid_to_human[val]
-
node_id_to_name[key] = name
-
-
return node_id_to_name
-
-
def id_to_string(self, node_id):
-
if node_id not in self.node_lookup:
-
return ''
-
return self.node_lookup[node_id]
-
-
-
def create_graph():
-
"""Creates a graph from saved GraphDef file and returns a saver."""
-
# Creates graph from saved graph_def.pb.
-
with tf.gfile.FastGFile(os.path.join(
-
FLAGS.model_dir, 'classify_image_graph_def.pb'), 'rb') as f:
-
graph_def = tf.GraphDef()
-
graph_def.ParseFromString(f.read())
-
_ = tf.import_graph_def(graph_def, name='')
-
-
-
def run_inference_on_image(image):
-
"""Runs inference on an image.
-
-
Args:
-
image: Image file name.
-
-
Returns:
-
Nothing
-
"""
-
if not tf.gfile.Exists(image):
-
tf.logging.fatal('File does not exist %s', image)
-
image_data = tf.gfile.FastGFile(image, 'rb').read()
-
-
# Creates graph from saved GraphDef.
-
create_graph()
-
-
with tf.Session() as sess:
-
# Some useful tensors:
-
# 'softmax:0': A tensor containing the normalized prediction across
-
# 1000 labels.
-
# 'pool_3:0': A tensor containing the next-to-last layer containing 2048
-
# float description of the image.
-
# 'DecodeJpeg/contents:0': A tensor containing a string providing JPEG
-
# encoding of the image.
-
# Runs the softmax tensor by feeding the image_data as input to the graph.
-
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0')
-
predictions = sess.run(softmax_tensor,
-
{'DecodeJpeg/contents:0': image_data})
-
predictions = np.squeeze(predictions)
-
-
# Creates node ID --> English string lookup.
-
node_lookup = NodeLookup()
-
-
top_k = predictions.argsort()[-FLAGS.num_top_predictions:][::-1]
-
for node_id in top_k:
-
human_string = node_lookup.id_to_string(node_id)
-
score = predictions[node_id]
-
print('%s (score = %.5f)' % (human_string, score))
-
-
-
def maybe_download_and_extract():
-
"""Download and extract model tar file."""
-
dest_directory = FLAGS.model_dir
-
if not os.path.exists(dest_directory):
-
os.makedirs(dest_directory)
-
filename = DATA_URL.split('/')[-1]
-
filepath = os.path.join(dest_directory, filename)
-
if not os.path.exists(filepath):
-
def _progress(count, block_size, total_size):
-
sys.stdout.write('\r>> Downloading %s %.1f%%' % (
-
filename, float(count * block_size) / float(total_size) * 100.0))
-
sys.stdout.flush()
-
filepath, _ = urllib.request.urlretrieve(DATA_URL, filepath, _progress)
-
print()
-
statinfo = os.stat(filepath)
-
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
-
tarfile.open(filepath, 'r:gz').extractall(dest_directory)
-
-
-
def main(_):
-
maybe_download_and_extract()
-
image = (FLAGS.image_file if FLAGS.image_file else
-
os.path.join(FLAGS.model_dir, 'cropped_panda.jpg'))
-
run_inference_on_image(image)
-
-
-
if __name__ == '__main__':
-
parser = argparse.ArgumentParser()
-
# classify_image_graph_def.pb:
-
# Binary representation of the GraphDef protocol buffer.
-
# imagenet_synset_to_human_label_map.txt:
-
# Map from synset ID to a human readable string.
-
# imagenet_2012_challenge_label_map_proto.pbtxt:
-
# Text representation of a protocol buffer mapping a label to synset ID.
-
parser.add_argument(
-
'--model_dir',
-
type=str,
-
default=r'C:\Users\Administrator\Desktop\imagenet',
-
help="""\
-
Path to classify_image_graph_def.pb,
-
imagenet_synset_to_human_label_map.txt, and
-
imagenet_2012_challenge_label_map_proto.pbtxt.\
-
"""
-
)
-
parser.add_argument(
-
'--image_file',
-
type=str,
-
default=r'C:\Users\Administrator\Desktop\imagenet\cropped_panda.jpg',
-
help='Absolute path to image file.'
-
)
-
parser.add_argument(
-
'--num_top_predictions',
-
type=int,
-
default=5,
-
help='Display this many predictions.'
-
)
-
FLAGS, unparsed = parser.parse_known_args()
-
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
运行以下命令:
python classify_image.py
以上命令会对提供的大熊猫图像进行分类。

如果模型运行正确,脚本将生成以下输出:
-
giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.88493)
-
indri, indris, Indri indri, Indri brevicaudatus (score = 0.00878)
-
lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00317)
-
custard apple (score = 0.00149)
-
earthstar (score = 0.00127)
如果想提供其他 JPEG 图像,只需修改 --image_file 参数即可。
如果将模型数据下载到其他目录,则需要使 --model_dir 指向所使用的目录。
在Windows环境下小伙伴们可以在直接到GitHub下载该程序案例:https://github.com/tensorflow/models
但是有时下载识别模型时经常会失败,这里我给大家分享下我调试好的Demo:https://download.csdn.net/download/m0_38106923/10892062
可以使用 C++ 运行同一 Inception-v3 模型,以在生产环境中使用模型。为此,可以下载包含 GraphDef 的归档文件,GraphDef 会以如下方式定义模型(从 TensorFlow 代码库的根目录运行):
-
curl -L "https://storage.googleapis.com/download.tensorflow.org/models/inception_v3_2016_08_28_frozen.pb.tar.gz" |
-
tar -C tensorflow/examples/label_image/data -xz
接下来,我们需要编译包含加载和运行图的代码的 C++ 二进制文件。如果按照针对您平台的说明下载 TensorFlow 源安装文件,则应该能够通过从 shell 终端运行以下命令来构建该示例:
bazel build tensorflow/examples/label_image/...
上述命令应该会创建一个可执行的二进制文件,然后可以运行该文件,如下所示:
bazel-bin/tensorflow/examples/label_image/label_image
这里使用的是框架附带的默认示例图像,输出结果应与以下内容类似:
-
I tensorflow/examples/label_image/main.cc:206] military uniform (653): 0.834306
-
I tensorflow/examples/label_image/main.cc:206] mortarboard (668): 0.0218692
-
I tensorflow/examples/label_image/main.cc:206] academic gown (401): 0.0103579
-
I tensorflow/examples/label_image/main.cc:206] pickelhaube (716): 0.00800814
-
I tensorflow/examples/label_image/main.cc:206] bulletproof vest (466): 0.00535088
在本例中,我们使用的是默认的海军上将格蕾丝·赫柏的图像,您可以看到,网络可正确识别她穿的是军装,分数高达 0.8。

有关其工作原理,请参阅 tensorflow/examples/label_image/main.cc 文件(https://www.tensorflowers.cn/t/7558)。希望此代码可帮助小伙伴们将 TensorFlow 集成到自己的应用中,因此将逐步介绍主要函数:
命令行标记可控制文件加载路径以及输入图像的属性。由于应向模型输入 299x299 RGB 的正方形图像,因此标记 input_width 和 input_height 应设成这些值。此外,我们还需要将像素值从介于 0 至 255 之间的整数缩放成浮点值,因为图执行运算时采用的是浮点数。我们使用 input_mean 和 input_std 标记控制缩放;先用每个像素值减去 input_mean,然后除以 input_std。
这些值看起来可能有点不可思议,但它们只是原模型作者根据他 / 她想要用做输入图像以用于训练的内容定义的。如果小伙伴们有自行训练的图,只需对值做出调整,使其与您在训练过程中使用的任何值一致即可。
你可以参阅 ReadTensorFromImageFile() 函数,了解这些标记是如何应用到图像的。
-
// Given an image file name, read in the data, try to decode it as an image,
-
// resize it to the requested size, and then scale the values as desired.
-
Status ReadTensorFromImageFile(string file_name, const int input_height,
-
const int input_width, const float input_mean,
-
const float input_std,
-
std::vector<Tensor>* out_tensors) {
-
tensorflow::GraphDefBuilder b;
首先,创建一个 GraphDefBuilder 对象,它可用于指定要运行或加载的模型。
-
string input_name = "file_reader";
-
string output_name = "normalized";
-
tensorflow::Node* file_reader =
-
tensorflow::ops::ReadFile(tensorflow::ops::Const(file_name, b.opts()),
-
b.opts().WithName(input_name));
然后,为要运行的小型模型创建节点,以加载、调整和缩放像素值,从而获得主模型期望作为其输入的结果。我创建的第一个节点只是一个 Const 操作,它会存储一个张量,其中包含要加载的图像的文件名。然后,该张量会作为第一个输入传递到 ReadFile 操作。小伙伴们可能会注意到,我将 b.opts() 作为最后一个参数传递到所有操作创建函数。该参数可确保该节点会添加到 GraphDefBuilder 中存储的模型定义中。此外,我还通过向 b.opts() 发起 WithName() 调用来命名 ReadFile 运算符,从而命名该节点,虽然这不是绝对必要的操作(因为如果您不执行此操作,系统会自动为该节点分配名称),但确实可简化调试过程。
-
// Now try to figure out what kind of file it is and decode it.
-
const int wanted_channels = 3;
-
tensorflow::Node* image_reader;
-
if (tensorflow::StringPiece(file_name).ends_with(".png")) {
-
image_reader = tensorflow::ops::DecodePng(
-
file_reader,
-
b.opts().WithAttr("channels", wanted_channels).WithName("png_reader"));
-
} else {
-
// Assume if it's not a PNG then it must be a JPEG.
-
image_reader = tensorflow::ops::DecodeJpeg(
-
file_reader,
-
b.opts().WithAttr("channels", wanted_channels).WithName("jpeg_reader"));
-
}
-
// Now cast the image data to float so we can do normal math on it.
-
tensorflow::Node* float_caster = tensorflow::ops::Cast(
-
image_reader, tensorflow::DT_FLOAT, b.opts().WithName("float_caster"));
-
// The convention for image ops in TensorFlow is that all images are expected
-
// to be in batches, so that they're four-dimensional arrays with indices of
-
// [batch, height, width, channel]. Because we only have a single image, we
-
// have to add a batch dimension of 1 to the start with ExpandDims().
-
tensorflow::Node* dims_expander = tensorflow::ops::ExpandDims(
-
float_caster, tensorflow::ops::Const(0, b.opts()), b.opts());
-
// Bilinearly resize the image to fit the required dimensions.
-
tensorflow::Node* resized = tensorflow::ops::ResizeBilinear(
-
dims_expander, tensorflow::ops::Const({input_height, input_width},
-
b.opts().WithName("size")),
-
b.opts());
-
// Subtract the mean and divide by the scale.
-
tensorflow::ops::Div(
-
tensorflow::ops::Sub(
-
resized, tensorflow::ops::Const({input_mean}, b.opts()), b.opts()),
-
tensorflow::ops::Const({input_std}, b.opts()),
-
b.opts().WithName(output_name));
接下来,我继续添加更多节点,以便将文件数据解码为图像、将整数转换为浮点值、调整大小,最终对像素值运行减法和除法运算。
-
// This runs the GraphDef network definition that we've just constructed, and
-
// returns the results in the output tensor.
-
tensorflow::GraphDef graph;
-
TF_RETURN_IF_ERROR(b.ToGraphDef(&graph));
最后,我获得一个存储在变量 b 中的模型定义,并可以使用 ToGraphDef() 函数将其转换成一个完整的图定义。
-
std::unique_ptr<tensorflow::Session> session(
-
tensorflow::NewSession(tensorflow::SessionOptions()));
-
TF_RETURN_IF_ERROR(session->Create(graph));
-
TF_RETURN_IF_ERROR(session->Run({}, {output_name}, {}, out_tensors));
-
return Status::OK();
接下来,创建一个 tf.Session 对象(它是实际运行图的接口)并运行它,从而指定要从哪个节点获得输出,以及将输出数据存放在什么位置。
这为我们提供了一个由 Tensor 对象构成的向量,在此例中,我们知道它将仅是单个对象的长度。在这种情况下,可以将 Tensor 视为多维数组,它将 299 像素高、299 像素宽、3 通道的图像存储为浮点值。如果产品中已有自己的图像处理框架,则应该能够使用该框架,只要在将图像馈送到主图之前对其应用相同的转换即可。
下面是使用 C++ 动态创建小型 TensorFlow 图的简单示例,但对于预训练的 Inception 模型,我们需要从文件中加载更大的定义。可以查看 LoadGraph() 函数,了解如何做到这一点。
-
// Reads a model graph definition from disk, and creates a session object you
-
// can use to run it.
-
Status LoadGraph(string graph_file_name,
-
std::unique_ptr<tensorflow::Session>* session) {
-
tensorflow::GraphDef graph_def;
-
Status load_graph_status =
-
ReadBinaryProto(tensorflow::Env::Default(), graph_file_name, &graph_def);
-
if (!load_graph_status.ok()) {
-
return tensorflow::errors::NotFound("Failed to load compute graph at '",
-
graph_file_name, "'");
-
}
如果已经浏览图像加载代码,则应该对许多术语都比较熟悉了。我会加载直接包含 GraphDef 的 protobuf 文件,而不是使用 GraphDefBuilder 生成 GraphDef 对象。
-
session->reset(tensorflow::NewSession(tensorflow::SessionOptions()));
-
Status session_create_status = (*session)->Create(graph_def);
-
if (!session_create_status.ok()) {
-
return session_create_status;
-
}
-
return Status::OK();
-
}
然后,我从该 GraphDef 创建一个 Session 对象,并将其传递回调用程序,以便调用程序稍后可以运行它。
GetTopLabels() 函数很像图像加载,只是在本例中,我想要获取运行主图得到的结果,并将其转换成得分最高的标签的排序列表。与图像加载器类似,该函数可创建一个 GraphDefBuilder,向其添加几个节点,然后运行较短的图,从而获取一对输出张量。在本例中,它们分别表示最高结果的经过排序的得分和索引位置。
-
// Analyzes the output of the Inception graph to retrieve the highest scores and
-
// their positions in the tensor, which correspond to categories.
-
Status GetTopLabels(const std::vector<Tensor>& outputs, int how_many_labels,
-
Tensor* indices, Tensor* scores) {
-
tensorflow::GraphDefBuilder b;
-
string output_name = "top_k";
-
tensorflow::ops::TopK(tensorflow::ops::Const(outputs[0], b.opts()),
-
how_many_labels, b.opts().WithName(output_name));
-
// This runs the GraphDef network definition that we've just constructed, and
-
// returns the results in the output tensors.
-
tensorflow::GraphDef graph;
-
TF_RETURN_IF_ERROR(b.ToGraphDef(&graph));
-
std::unique_ptr<tensorflow::Session> session(
-
tensorflow::NewSession(tensorflow::SessionOptions()));
-
TF_RETURN_IF_ERROR(session->Create(graph));
-
// The TopK node returns two outputs, the scores and their original indices,
-
// so we have to append :0 and :1 to specify them both.
-
std::vector<Tensor> out_tensors;
-
TF_RETURN_IF_ERROR(session->Run({}, {output_name + ":0", output_name + ":1"},
-
{}, &out_tensors));
-
*scores = out_tensors[0];
-
*indices = out_tensors[1];
-
return Status::OK();
PrintTopLabels() 函数会采用这些经过排序的结果,并以友好的方式输出这些结果。CheckTopLabel() 函数与其极为相似,但出于调试目的,需确保最有可能的标签是我们预期的值。
最后,main() 将所有这些调用绑定在一起。
-
int main(int argc, char* argv[]) {
-
// We need to call this to set up global state for TensorFlow.
-
tensorflow::port::InitMain(argv[0], &argc, &argv);
-
Status s = tensorflow::ParseCommandLineFlags(&argc, argv);
-
if (!s.ok()) {
-
LOG(ERROR) << "Error parsing command line flags: " << s.ToString();
-
return -1;
-
}
-
-
// First we load and initialize the model.
-
std::unique_ptr<tensorflow::Session> session;
-
string graph_path = tensorflow::io::JoinPath(FLAGS_root_dir, FLAGS_graph);
-
Status load_graph_status = LoadGraph(graph_path, &session);
-
if (!load_graph_status.ok()) {
-
LOG(ERROR) << load_graph_status;
-
return -1;
-
}
加载主图
-
// Get the image from disk as a float array of numbers, resized and normalized
-
// to the specifications the main graph expects.
-
std::vector<Tensor> resized_tensors;
-
string image_path = tensorflow::io::JoinPath(FLAGS_root_dir, FLAGS_image);
-
Status read_tensor_status = ReadTensorFromImageFile(
-
image_path, FLAGS_input_height, FLAGS_input_width, FLAGS_input_mean,
-
FLAGS_input_std, &resized_tensors);
-
if (!read_tensor_status.ok()) {
-
LOG(ERROR) << read_tensor_status;
-
return -1;
-
}
-
const Tensor& resized_tensor = resized_tensors[0];
加载、处理输入图像并调整其大小
-
// Actually run the image through the model.
-
std::vector<Tensor> outputs;
-
Status run_status = session->Run({ {FLAGS_input_layer, resized_tensor}},
-
{FLAGS_output_layer}, {}, &outputs);
-
if (!run_status.ok()) {
-
LOG(ERROR) << "Running model failed: " << run_status;
-
return -1;
-
}
在本示例中,我们将图像作为输入,运行已加载的图
-
// This is for automated testing to make sure we get the expected result with
-
// the default settings. We know that label 866 (military uniform) should be
-
// the top label for the Admiral Hopper image.
-
if (FLAGS_self_test) {
-
bool expected_matches;
-
Status check_status = CheckTopLabel(outputs, 866, &expected_matches);
-
if (!check_status.ok()) {
-
LOG(ERROR) << "Running check failed: " << check_status;
-
return -1;
-
}
-
if (!expected_matches) {
-
LOG(ERROR) << "Self-test failed!";
-
return -1;
-
}
-
}
出于测试目的,我们可以在下方检查以确保获得了预期的输出
-
// Do something interesting with the results we've generated.
-
Status print_status = PrintTopLabels(outputs, FLAGS_labels);
最后,输出我们找到的标签
-
if (!print_status.ok()) {
-
LOG(ERROR) << "Running print failed: " << print_status;
-
return -1;
-
}
在本示例中,我使用 TensorFlow 的 Status 对象处理错误,它非常方便,因为通过它,小伙伴们可以使用 ok() 检查工具了解是否发生了任何错误,如果有错误,则可以输出可以读懂的错误消息。
在本示例中,我演示的是对象识别,但小伙伴们应该能够对自己在各种领域找到的或自行训练的其他模型使用非常相似的代码。我希望这一小示例可就如何在自己的产品中使用 TensorFlow 为大家带来一些启发。
文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/85645215

- 点赞
- 收藏
- 关注作者
评论(0)