Grasp2Vec:通过自我监督式抓取学习物体表征

从很小的时候开始,人类就能够识别最喜欢的物品,并将它们捡起来,尽管从未有人明确教过他们这样做。认知发展研究表明,与周围物体互动的能力在培养物体感知和操纵能力(例如有目的的抓取)的过程中起着至关重要的作用。通过与周围的环境互动,人类能够以自我监督的方式学习:我们知道自己作出的动作,并会从结果中学习。在机器人领域,人们正在积极研究这种自我监督学习,因为这使机器人系统能够在不需要大量训练数据或人工监督的情况下进行学习。
受物体恒存概念的启发,Google提出了 Grasp2Vec,这是一种简单但非常高效的算法,可用于获取物体表征。Grasp2Vec 基于这样一种直觉,即抓起任何物体的尝试都会提供一些信息。如果机器人抓住并举起某个物体,则此物体在被抓取前必须存在于场景中。此外,机器人知道它抓取的物体目前在自己手中,因此物体被移出了场景。通过这种形式的自我监督,机器人可以根据抓取后场景中的视觉变化来学会识别物体。

基于之前与 X Robotics 的合作(即一系列机器人同时仅通过单目摄像机输入来学习抓取家居用品),Google使用机械臂来 “无目的地” 抓取物体,而这种体验使机器人可以学习丰富的物体表征。然后它们可以将这些表征用于获得 “有目的抓取” 的能力,即机械臂之后可以根据用户指令抓取物体。效果如下所示:

构建感知奖励函数
在强化学习 (RL) 的框架中,任务成功与否可以通过 “奖励函数” 来衡量。通过使奖励最大化,机器人可以从头开始自学各种抓取技能。当成功可以由简单的传感器测量结果来衡量时,设计奖励函数并非难事。举一个简单的例子,当机器人按下某个按钮时,它会直接得到奖励。
但是,如果我们的成功标准取决于对手头任务的感知认识,那么设计奖励函数就会困难得多。例如实例抓取任务,我们向机器人呈现一张图片,其中需要其抓取的物体正被抓着。在机器人尝试抓取该物体后,它会检查手中的物体。此任务的奖励函数可以归结为回答物体识别问题:这些物体是否与目标匹配?

在左图中,机器臂正抓着刷子,背景中有一些物体(黄色杯子、蓝色塑料块)。在右图中,机器臂正抓着黄色杯子,背景中有刷子。如果左图是所需结果,则正确的奖励函数应该能够 “理解” 上面两张图片对应不同的物体
为解决这一识别问题,我们需要能够从非结构化图像数据(没有任何人为标注)中提取有意义对象概念的感知系统,以无监督的方式学习对物体的视觉感知。无监督学习算法的核心是对数据作出结构性假设。常见的假设是我们可以将图像压缩成低维空间,并从之前的帧预测出视频中的对应帧。然而,如果没有对数据内容的进一步假设,则这些假设往往不足以用来学习分离对象表征。
那么如果我们在数据收集期间,使用机器人实际分离不同对象呢?机器人领域为表征学习提供了绝佳的机会,由于机器人可以操纵物体,因此能够提供数据中所需的变化因素。我们的方法基于以下想法:被抓取的物体会从场景中移除。这会产生:
- 抓取前的场景图像
- 抓取后的场景图像
- 抓取物体本身的单独视图

左图:抓取前的物体 中间:抓取后的物体 右图:所抓取的物体
那么,如果我们定义一个从图像中提取 “对象集” 的嵌入函数,则该函数应该存在以下减法关系:

Google使用完全卷积架构和简单的度量学习算法来实现这种等式关系。在训练时,下图中展示的架构会将抓取前和抓取后的图像嵌入到密集空间特征图中。这些特征图经平均池化后变为向量,“抓取前” 和 “抓取后” 向量之间的差异代表一组物体。该向量和被抓取物体的相应向量表征会通过 N 配对目标归于等价。
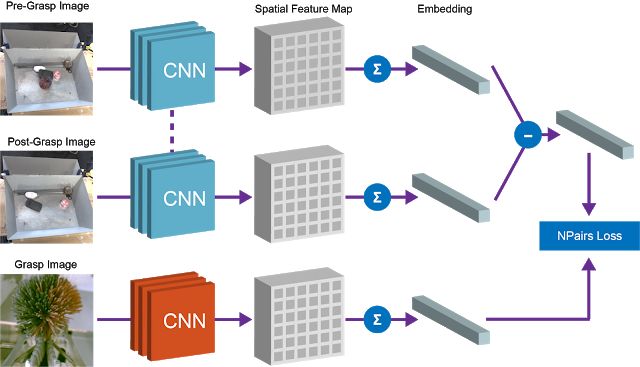
经过训练后,我们的模型会自然出现两个有用的属性。
1.对象相似性
第一个属性是向量嵌入之间的余弦距离,这让我们可以比较对象,并确定它们是否相同。此属性可用于实现强化学习的奖励函数,并使机器人能够在没有人为提供标签的情况下学习实例抓取。
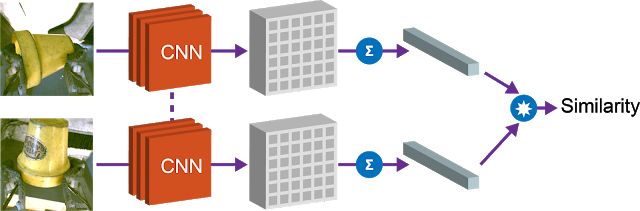
2.寻找目标对象
第二个属性是我们可以将场景空间图和对象嵌入结合起来,以确定 “查询对象” 在图像空间中的位置。通过获取空间特征图的元素积和查询对象的对应向量,我们可以在空间图中找到与查询对象 “匹配” 的所有像素。
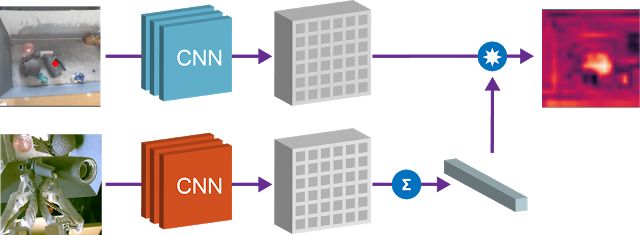
使用 Grasp2Vec 嵌入在场景中寻找物体。左上方的图像展示了箱子中的物体。左下方是我们希望抓取的查询对象。通过将查询对象向量的点积与场景图像的空间特征相结合,我们得到每像素的 “激活图”(右上方的图像),其中展示了图像中的相应区域与查询对象的相似度。此响应图可用于寻找要抓取的物体
当存在多个与查询对象匹配的物体时,或者即使查询中包含多个对象(两个向量的平均值),我们的方法仍然有效。例如,以下是在场景中检测到多个橙色块的情况。

所生成的 “热图” 可用于规划机器人寻找目标对象的方法。我们将 Grasp2Vec 的定位和实例识别功能与 “无目的抓取” 的策略相结合,在数据收集期间实现机器人找到已见过物体的 80% 成功率,以及找到未见过新物体的 59% 成功率。
结论
在这篇文章中,我们展示了机器人抓取技能如何生成用于学习对象中心表征的数据。然后,我们可以利用表征学习来 “引导” 机器人学习实例抓取等更复杂的技能,同时保留自主抓取系统的自我监督学习属性。
除了我们自己的研究以外,最近的许多论文也研究了如何通过抓取、推压以及采用其他方法操纵环境中的物体,从而将自我监督互动应用于获取表征。展望未来,我们不仅对机器学习能够通过更出色的感知和控制能力为机器人带来哪些成果而感到兴奋,还对机器人在新的自我监督范式中能为机器学习带来哪些改变感到期待。
本文摘自Google最新的技术文章,结合自己的一些感悟略作调整。
文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/86262573

- 点赞
- 收藏
- 关注作者
评论(0)