用Python实现一个简单的——人脸相似度对比

近几年来,兴起了一股人工智能热潮,让人们见到了AI的能力和强大,比如图像识别,语音识别,机器翻译,无人驾驶等等。总体来说,AI的门槛还是比较高,不仅要学会使用框架实现,更重要的是,需要有一定的数学基础,如线性代数,矩阵,微积分等。
幸庆的是,国内外许多大神都已经给我们造好“轮子”,我们可以直接来使用某些模型。今天就和大家交流下如何实现一个简易版的人脸对比,非常有趣!
整体思路:
1、预先导入所需要的人脸识别模型;
2、遍历循环识别文件夹里面的图片,让模型“记住”人物的样子;
3、输入一张新的图像,与前一步文件夹里面的图片比对,返回最接近的结果。
使用到的第三方模块和模型:
1、模块:os,dlib,glob,numpy;
2、模型:人脸关键点检测器,人脸识别模型。
第一步:导入需要的模型。
这里解释一下两个dat文件:
它们的本质是参数值(即神经网络的权重)。人脸识别算是深度学习的一个应用,事先需要经过大量的人脸图像来训练。所以一开始我们需要去设计一个神经网络结构,来“记住”人类的脸。
对于神经网络来说,即便是同样的结构,不同的参数也会导致识别的东西不一样。在这里,这两个参数文件就对应了不同的功能(它们对应的神经网络结构也不同):
shape_predictor.dat这个是为了检测人脸的关键点,比如眼睛,嘴巴等等;dlib_face_recognition.dat是在前面检测关键点的基础上,生成人脸的特征值。
所以后面使用dlib模块的时候,其实就是相当于,调用了某个神经网络结构,再把预先训练好的参数传给我们调用的神经网络。顺便提一下,在深度学习领域中,往往动不动会训练出一个上百M的参数模型出来,是很正常的事。
-
import os,dlib,glob,numpy
-
from skimage import io
-
-
# 人脸关键点检测器
-
predictor_path = "shape_predictor.dat"
-
# 人脸识别模型、提取特征值
-
face_rec_model_path = "dlib_face_recognition.dat"
-
# 训练图像文件夹
-
faces_folder_path ='train_images'
-
-
# 加载模型
-
detector = dlib.get_frontal_face_detector()
-
sp = dlib.shape_predictor(predictor_path)
-
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
第二步:对训练集进行识别。
在这一步中,我们要完成的是,对图片文件夹里面的人物图像,计算他们的人脸特征,并放到一个列表里面,为了后面可以和新的图像进行一个距离计算。关键地方会加上注释,应该不难理解。
-
candidate = [] # 存放训练集人物名字
-
descriptors = [] #存放训练集人物特征列表
-
-
for f in glob.glob(os.path.join(faces_folder_path,"*.jpg")):
-
print("正在处理: {}".format(f))
-
img = io.imread(f)
-
candidate.append(f.split('\\')[-1].split('.')[0])
-
# 人脸检测
-
dets = detector(img, 1)
-
for k, d in enumerate(dets):
-
shape = sp(img, d)
-
# 提取特征
-
face_descriptor = facerec.compute_face_descriptor(img, shape)
-
v = numpy.array(face_descriptor)
-
descriptors.append(v)
-
-
print('识别训练完毕!')
当你做完这一步之后,输出列表descriptors看一下,可以看到类似这样的数组,每一个数组代表的就是每一张图片的特征量(128维)。然后我们可以使用L2范式(欧式距离),来计算两者间的距离。
举个例子,比如经过计算后,A的特征值是[x1,x2,x3],B的特征值是[y1,y2,y3], C的特征值是[z1,z2,z3]。
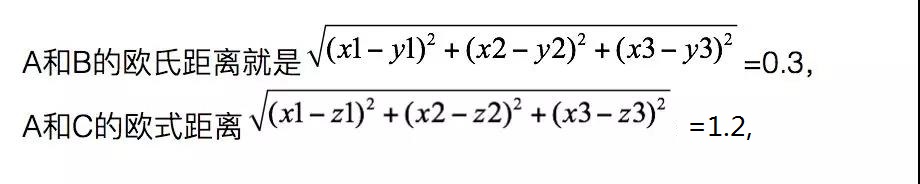
那么由于A和B更接近,所以会认为A和B更像。想象一下极端情况,如果是同一个人的两张不同照片,那么它们的特征值是不是应该会几乎接近呢?知道了这一点,就可以继续往下走了。
第三步:处理待对比的图片。
其实是同样的道理,如法炮制,目的就是算出一个特征值出来,所以和第二步差不多。然后再顺便计算出新图片和第二步中每一张图片的距离,再合成一个字典类型,排个序,选出最小值,搞定收工!
-
try:
-
## test_path=input('请输入要检测的图片的路径(记得加后缀哦):')
-
img = io.imread(r".\test_images\test6.jpg")
-
dets = detector(img, 1)
-
except:
-
print('输入路径有误,请检查!')
-
-
dist = []
-
for k, d in enumerate(dets):
-
shape = sp(img, d)
-
face_descriptor = facerec.compute_face_descriptor(img, shape)
-
d_test = numpy.array(face_descriptor)
-
for i in descriptors: #计算距离
-
dist_ = numpy.linalg.norm(i-d_test)
-
dist.append(dist_)
-
-
# 训练集人物和距离组成一个字典
-
c_d = dict(zip(candidate,dist))
-
cd_sorted = sorted(c_d.items(), key=lambda d:d[1])
-
print ("识别到的人物最有可能是: ",cd_sorted[0][0])
这里我用了一张“断水流大师兄”林国斌的照片,识别的结果是,果然,是最接近黎明了(嘻嘻,我爱黎明)。但如果你事先在训练图像集里面有放入林国斌的照片,那么出来的结果就是林国斌了。

为什么是黎明呢?我们看一下输入图片里的人物最后与每个明星的距离,输出打印一下:
{'刘亦菲': 0.5269014581137407,
'刘诗诗': 0.4779630331578229,
'唐艺昕': 0.45967444611419184,
'杨幂': 0.4753850256188804,
'迪丽热巴': 0.5730399094704894,
'郑秀妍': 0.40740137304879187,
'郑秀晶': 0.45325515192940385,
'郭富城': 0.7624925709626963,
'黎明': 0.8925473299225084}
没错,他和黎明的距离是最小的,所以和他也最像了!
源码及模型下载:https://download.csdn.net/download/m0_38106923/10772957
拓展项目:Python+OpenCv实现AI人脸识别身份认证系统
文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/83862334

- 点赞
- 收藏
- 关注作者
评论(0)